标签:样本 str 人工神经网络 干什么 信息 id3 挖掘 c4.5 预测

目 录
第1章 揭开数据挖掘的面纱1
1.1 历史的使命2
数据挖掘的最高境界就是 从数据中获取知识,辅助科学决策。
1.2 数据挖掘的故事6
1.2.1 震撼业界的发现6 --- 沃尔玛 啤酒与尿布
1.2.2 降低成本的绝活9 -- 派克汉尼公司 机器零件磨损分析
1.2.3 出奇制胜的小纸条11 -- 足球点球数据
1.3 什么是数据挖掘?14
数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用信息和知识的过程。
1.4 历史的必然17
从传统的数据仓库,联机在线分析到现代数据库的知识发现KDD,数据挖掘是一种必然的方向。
1.5 数据挖掘能干什么?23
1.5.1 关联(ASSOCIATION)规则挖掘24
关联规则最经典的算法是apriori算法,主要思想是,首先在事件中寻找所有频繁出现的事件子集,然后在这些频繁事件子集中发现可信度较高的规则。
1.5.2 聚类26
聚类是将数据对象划分为若干分类,在同一类中的对象具有较高的相似度,而不同类中的对象差异较大。
两个对象间的距离越小,说明二者越相似,用距离度量对象的相似性应该是最自然的方法。
聚类的两类经典算法:划分方法和层次聚类方法。
划分方法--kmean k-medoids
k-mean聚类的基本思想:类内数据点越近越好,类间点越远越好的尽可能的算法。
①从n个数据对象中任意选取k个对象作为初始的聚类中心
②分别计算每个对象到各个聚类中心的聚类,把对象分配到距离最近的聚类中
③所有对象分配完成后,重新计算k个聚类的中心
④与前一次计算得到的k个聚类中心比较,如果聚类中心发生变化,转到②,否则转到⑤。
k-medoids算法用簇中最靠近中心的一个对象来代表该簇,而k-means算法用质心来代表簇。可见k-means算法对噪声和孤立点数据非常敏感,因为一个离群值会对质心的计算带来很大的影响。而k-mediods算法通过用中心点来代替质心,可以有效地消除这种影响。
当结果簇是密集的,而簇与簇之间区别明显时,k-means算法的效果较好。当对于大规模数据集,该算法是相对可扩展的,并且具有较高的效率。
层次聚类方法:
该方法按数据分层建立簇,形成一颗以簇为节点的树。如果自底向上进行层次聚类,则称为凝聚的层次聚类。如果是自顶向下进行层次聚类,则称为分裂法的层次聚类。
凝聚的层次聚类首先将每个对象作为一个簇,然后逐渐合并这些簇形成较大的簇,直到所有的对象都在同一个簇中,或者满足某一个终止条件。
分裂的层次聚类首先将所有对象置于一个簇中,然后逐渐划分为越来越小的簇,直到每一个对象自成一簇,或者达到了某一个终止条件。
层次方法和其他聚类方法结合可以形成多阶段聚类,这类算法包括birch cure rock chameleon等
视觉聚类算法:
视觉聚类算法是基于我们所建立的尺度空间理论建立起来的,运用这种算法可以对卫星传回的原始图像进行分析,把具有相似属性的事物聚类到同一簇中。
我们使用 相似率 连续率 闭合率 近似率 对称率作为聚类的基本原则。
1.5.3 预测35
数据挖掘的预测就是通过对反映了事物输入和输出之间的关联性的学习,得到预测模型,再利用该模型对未来数据进行预测的过程。
预测方法包括:
1、决策树方法
主要算法有ID3、C4.5
ID3算法核心思想是在决策树的构建过程中采取基于信息增益的特征选择策略,即选取具有最高增益的属性作为当前节点的分裂属性,使得对结果划分中的样本分类所需要的信息量最小。以此构造和训练数据一致的一颗决策树,从而保证了决策树具有最小的分支数量和最小的冗余度。
ID3算法的不足之处
①ID3算法在搜索的过程中不能回溯重新考虑选择过的属性,从而收敛到局部最优解而不是全局最优解。
②信息增益的度量偏袒于属性取值数目较多的属性,这不太合理。
③ID3算法只能处理离散数值的属性,不能处理连续属性。
④当训练样本过小或者包含有噪声的时候,容易产生过拟合现象。
针对ID3算法的不足,提出了C4.5算法。
C4.5在以下方面对算法进行了改进:
①用信息增益比率作为选择标准,弥补了ID3算法偏向于取值较多的属性的不足。
②合并连续属性的取值
③可以处理具有较少属性值的训练样本
④运用不同的剪枝技术来避免决策树的过拟合现象
⑤K次交叉验证等
解决决策树过拟合问题的方法主要是对决策树进行剪枝,剪枝是一种克服噪声的技术,它有助于提高决策树对新数据的准确分类能力,同事能使决策树得到简化,使其更容易理解,加快分类速度。
剪枝可分为预剪枝和后剪枝。
预剪枝主要是通过建立某些规则限制决策时的充分生长。后剪枝则是等决策树充分生长完毕后再剪去那些不具有一般代表性的叶节点或者分支。
尽管前一种方法可能看起来比较直接,但是后一种方法在实践中更成功。因此在实际运用中更多的采用后剪枝技术。
2、人工神经网络
神经网络不依赖于模型的自适应函数估计器,可以实现任意的函数关系。
3、支持向量机SVM
支持向量机是根据统计学习理论中结构风险最小化的原则提出的一种机器学习方法。
既可以求解分类问题,也可以用于回归问题。
支持向量机是从线性可分的二分类问题开始建模的,再逐步向线性不可分问题、非线性问题深入,最后推广到线性和非线性回归问题建模。
通过引入核函数来处理分类面是曲面的问题。
可以使用SMO二次规划问题求解。
SVM支持向量机在解决小样本、非线性及高维模式识别问题中表现出许多挺有的优势。
SVM缺点:
①在太大规模数据集时,SVM要解决凸二次个规划而使得算法效率很低,甚至算法无法进行。
②SVM对奇异值的稳健性不高
③SVM的解不具有稀疏性,存在着大量冗余支撑向量
④参数没有较好的选择策略
4、正则化方法
Lasso和L1/L2正则化方法
lasso方法使用模型系数的绝对值作为惩罚来压缩模型系数,是的绝对值较小的系数自动压缩为0,从而使得到的模型具有稀疏性,从而同时实现显著性变化的选择和对应参数的估计。属于L1模型。
1.5.4 序列和时间序列49
时间序列预测和回归问题类似,只是时间序列是用历史的数值来预测未来数值,是一种特殊的自回归,更多的表现为描述对于过去时刻的观测和相应时刻的随机扰动的记忆性规律。
1.6 数据挖掘工具50
Intelligent Miner
Unica model 1
SAS
SPSS -- SPSS包含数据管理、统计分析、图标分析、输出管理等。
WEKA--开源
第2章 数据挖掘流程57
2.1 李部长其人58
2.2 老革命遇见了新问题60
2.3 钓鱼钓来了数据挖掘思路62
2.4 数据挖掘项目立项65
2.5 数据挖掘项目实施70
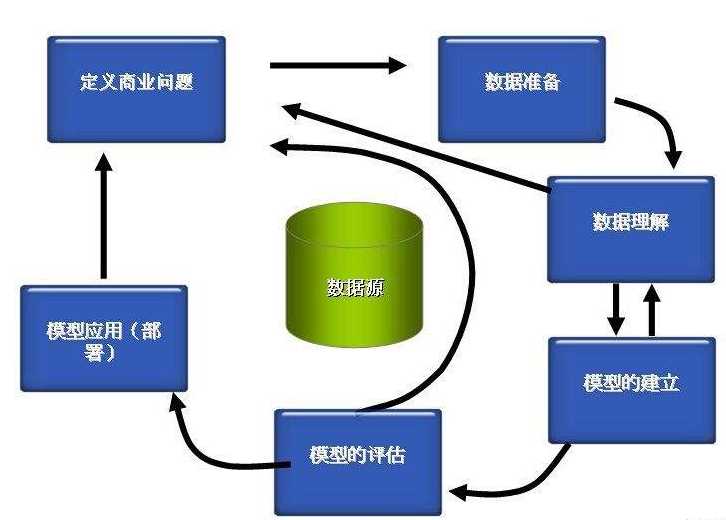
业务理解阶段→数据理解阶段→数据准备阶段→建模阶段→模型评估阶段→部署阶段
2.5.1 业务理解阶段(BUSINESS UNDERSTANDING)72
2.5.2 数据理解阶段(DATA UNDERSTANDING)74
2.5.3 数据准备阶段(DATA PREPARATION)77
2.5.4 建模阶段(MODELING)79
2.5.5 模型评估阶段(EVALUATION)83
2.5.6 部署阶段(DEPLOYMENT)84
2.6 李部长的展望86
第3章 数据挖掘在电力行业的应用89
3.1 应用前景90
3.2 电力设备状态检修94
3.3 电力系统暂态稳定性评估108
3.4 负荷预测115
3.5 盗电检测120
3.6 电力数据挖掘系统的构建124
第4章 数据挖掘在交通航空领域的应用127
4.1 铁路票价制定128
4.2 高铁轨道检修137
4.3 交通流量预测140
第5章 数据挖掘在冶金行业的应用145
5.1 流程工业这点儿事146
5.2 产品质量控制150
5.3 高炉炉温预测157
5.4 磨矿粒度预测162
5.5 炼焦配煤优化168
第6章 数据挖掘在税务、金融行业的应用173
6.1 税务稽查174
6.2 反洗钱180
6.3 股票指数追踪188
第7章 数据挖掘在故障诊断中的应用195
7.1 火箭发动机故障诊断196
7.2 机械设备故障诊断203
7.3 核动力设备故障诊断207
7.4 船舶动力故障诊断218
第8章 数据挖掘在电信业中的应用225
8.1 市场细分225
8.1 市场细分226
8.2 精确营销231
8.3 业务响应239
8.4 客户流失分析244
第9章 Web数据挖掘249
9.1 Web数据挖掘概述250
9.1 Web数据挖掘概述250
9.2 垂直搜索引擎中的数据挖掘252
9.3 面向电子商务的数据挖掘260
9.4 社交网络中的数据挖掘267
《大话数据挖掘》读书
标签:样本 str 人工神经网络 干什么 信息 id3 挖掘 c4.5 预测
原文地址:https://www.cnblogs.com/LearnFromNow/p/9747716.html