标签:特征 function 2.0 大于 多次 观察 mes 识别 导数
用线性关系去拟合输入和输出。
设输入为x,则输出y=ax+b。
对于多元的情况y=b×1+a1x1+a2x2+...+anxn。
用θ表示系数,可以写作:
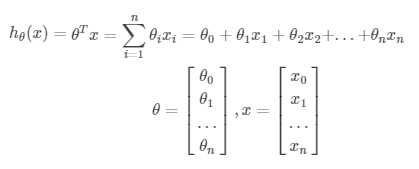
其中,x0=1。
对于连续输入和输出的问题,如果线性回归可以较好的拟合输入和输出,那么可以用这个模型预测其它输入时的输出。
反过来想:如果线性回归可以较好的拟合输入和输出,那么说明输出和输入有很强的线性相关性,可以识别输入中的冗余信息。
初步考虑,就是当使用模型时的输出、和真实的输出有多大偏差,选择一个方法量化这个偏差。
每个样本输入模型时,均会产生一个偏差。
线性回归中,通过求这些偏差的平方平均值,来判断偏差的程度。写作:
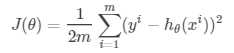
其中实际输出为y,模型输出为h,上标i是指每个样本。系数在平方平均值的基础上除以2。
判断偏差的这个方程起名叫 Cost Function。当偏差越小、即Cost Function的值越小时,拟合的越好。
训练模型的目的在于实现较好的拟合,也就是说使Cost Function的值尽量小。
训练在这里,就是选择一组系数θ(模型确定以后,模型的参数就是系数θ们),实现上面的目的。
微积分学过,可以对θ求偏导数等于0的点,直接得到极值点。
按照Andrew Ng的课件,当参数个数大于10000个时,直接求极值点时间太长,需要选择别的办法。
顾名思义,就是沿着梯度下降。选择一个合适的步长α,一步一步改变θ,使Cost Function的值不断减小。
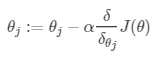
其中,θj表示各个系数。:=前面的冒号表示每个θj同时改变。
走多少步?和怎么判断模型训练好了呢?最好是观察每次θj改变后,J(θ)的值的变化。
最开始θj等于多少呢?最开始,随便选一组值就可以。
步长α应该选多大呢?要通过手动尝试,“找”到合适的值。
最后,经过多次迭代后,算法得到一组θ,使Cost Function的值比较小。
%一个特征的输入参数
X1=[0.50,0.75,1.00,1.25,1.50,1.75,1.75,2.00,2.25,2.50,2.75,3.00,3.25,3.50,4.00,4.25,4.50,4.75,5.00,5.50];
X0=ones(size(X1));
X=([X0;X1])‘;
y=([10, 22, 13, 43, 20, 22, 33, 50, 62, 48, 55, 75, 62, 73, 81, 76, 64, 82, 90, 93])‘;
%梯度下降参数设计
alpha=0.001;%当alpha大于1时就不收敛了
theta=[2;3];%选哪个点作为起点似乎对收敛速度影响不大
times=2000;%迭代次数
for i=1:times
delta=X*theta-y;%求偏导数
theta=theta-alpha.*(X‘*delta);%梯度下降
J(i)=delta‘*delta;%求此时的Cost Function值
end
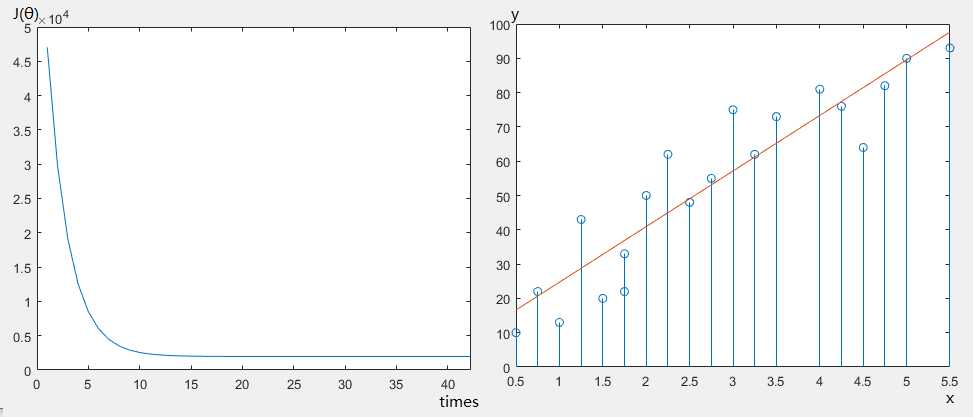
%观察Cost Function值随迭代次数的变化
% plot(J);
%观察拟合情况
stem(X1,y);
p2=X*theta;
hold on;
plot(X1,p2);
实际使用线性回归时,先对输入数据进行优化。包括:1.将冗余的和无关的变量去掉;2.对于非线性关系,采用多项式拟合,将一个变量变为多个变量;3.将输入范围归一化。
线性回归开始假设输入和输出存在线性关系,
然后使用线性回归模型h=θTx,用Cost Function J(θ)评价拟合程度,
通过对J(θ)应用梯度下降算法逼近一组好的参数θ,从而得到一个适用的模型h。
线性回归的使用建立在“输入和输出存在线性关系”这一假设基础上,把一组特征映射到一个值。
使用起来,也许因为模型太简单,感觉不到“机器学习”的感觉。选用时也需要很多先验知识、针对特定情况,就像一般的编程处理问题一样。
在使用梯度下降的算法时,迭代的过程,有点“学习”的感觉。
标签:特征 function 2.0 大于 多次 观察 mes 识别 导数
原文地址:https://www.cnblogs.com/sumr/p/9746649.html