标签:代码 style 打开 内容 str src 通过 出现 color
什么是字符编码?
计算机只能识别0和1,当我们与计算机进行交互的时候不可能通过0和1进行交互,因此我们需要一张表把我们人类的语言一一对应成计算机能够识别的语言,这张表就是我们通常所说的字符编码表。因为计算机是美国人发明的,在设计之初的时候并未考虑到全世界的情况,所以最开始只有一张ASCII表(这个表只是英文和计算机识别语言的一一对应),随着计算机的普及,为了使用计算机,各国陆陆续续的又出现了很多自己国家的字符编码表,但是这样就造成了另外一种现象,就是乱码。当中国使用外国的软件的时候,由于编码表不一样的问题导致无法解码出正确的字符,从而出现乱码。为了解决这样的问题,出现了一个叫做unicode的万国码,把世界上所有的语言通过这一张表一一映射,这样乱码的问题就解决了。但是unicode由于所占字节过大,为了节省空间从而达到减少IO操作时间的目的,又出现了一种变长编码方式utf-8(unicode transform format),它只是unicode的一种转换格式,和世界上其他的语言没有一一对应关系,目前现状来看,计算机内存中使用的编码方式是unicode。所以在我们进行编码和解码的过程中,如果出现了各国语言不一致的问题,我们需要通过unicode进行转换。
目前有的字符编码
软件执行文件的三步骤,python解释器也一样

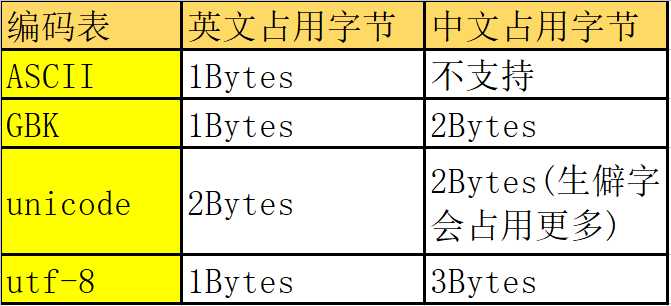
文件存入硬盘的过程(nodpad++为例)
结论:存文件的过程中不能出错,一旦存错就算是相同的编码方式也是解码不了的。
第一步:打开软件,也就是操作系统把软件添加到内存中
第二步:输入内容,此时所有的内容都是存在内存中的(先更改字符编码集,然后在写入内容),当我们编码改成日文的时候会发现目前我们依然能够看到是不乱码的,那是因为在内存中都是以unicode的形式编码的,无论是哪一国的语言都是可以显示的。
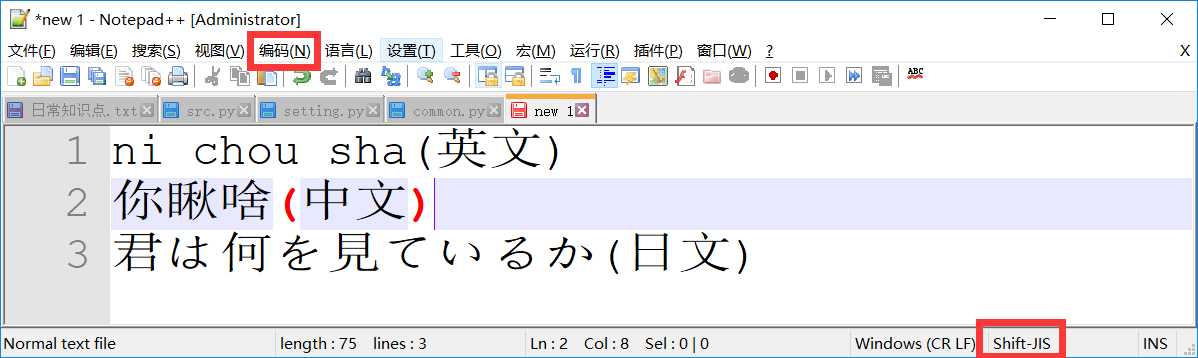
第三步:点击保存按钮,把内容保存在硬盘上面
第四步:以同样的编码方式重新打开的时候发现中文出现乱码
python读取文件的三个步骤
第一步:打开python解释器,加载到内存,没有实际文件的编码和解码过程
第二步:python当作一个文本编辑器去从硬盘中加载文件到内存,此时不会关注语法,但是有解码的过程。因此当初存文件的时候的编码和解码是否一样决定是否会报错。
python2默认编码方式为ASCII python3默认编码方式为utf-8
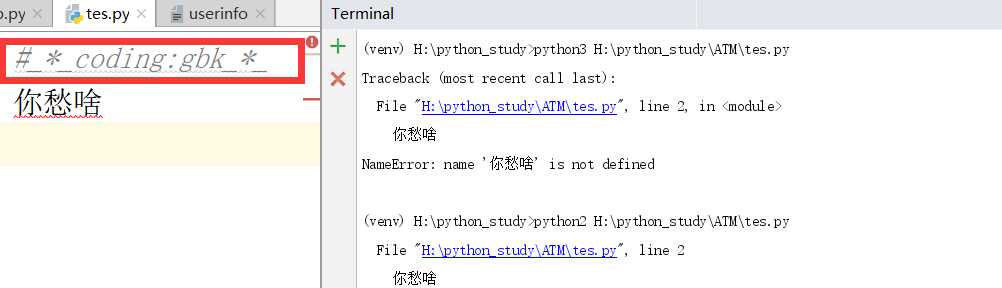
左边是一个以gbk的方式存储的文件,右边通过python3和python2分别去执行文件都会报错,这个是在第二步读取文件就会出现的错误,因为python2和python3默认编码方式都不是gbk,因此在加载到内存这一步就出现了错误
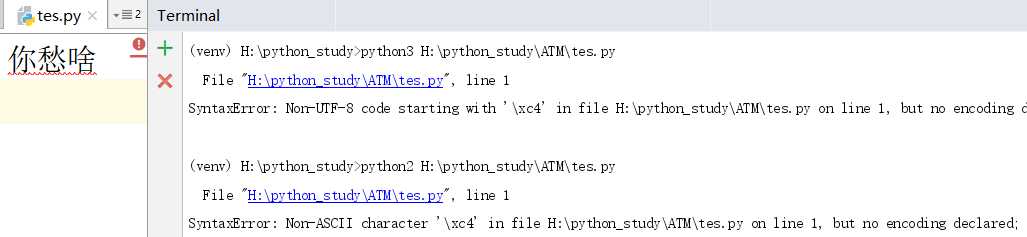
在前面加上了一行字符,表示告诉解释器当在读取文件的时候应该用哪中编码方式,这样在加载到内存这一步就不会出错了。报错的原因并不是字符编码的问题,而是程序的语法问题,也就是第三步了。
当前两步执行完成之后,文件中的内容就以unicode的方式存在了内存中。
接下来开始执行第三部,也就是python语法的检测(在这一步的处理python2和python3是不一样的):
为什么python2和python3在这一步不一样呢?代码存在与内存中是要存两份的,第一份就是在第二步(在未执行代码之前)从文件中读取出来的代码是以unicode的方式存在于内存中的,第二份就是在代码的执行过程中会对字符串重新申请一份内存空间,而这份内存空间是以什么样的编码方式存储的是与python的解释器有关系的!
print函数
print函数打印的时候默认是以终端的编码格式打印的!
python3
当python3读到 s = ‘你瞅啥‘ 会重新申请一份内存空间然后把 ‘你瞅啥’ 以unicode的方式存储起来。(所以说无论终端是以什么样的编码格式打印的都是不会出现乱码的)
# 下面这段代码无论放在哪里都是可以执行出来结果的,因为内存中的都是unicode编码 #_*_coding:gbk_*_ s = ‘你愁啥‘ print(s, type(s))
#_*_coding:gbk_*_ s = ‘你愁啥‘ print(s, type(s))
#s可以直接encode成任意编码格式 print(s.encode(‘gbk‘)) print(type(s.encode(‘gbk‘))) #<class ‘bytes‘>
python2
当python2读到 s = ‘你瞅啥‘ 默认会重新申请一份内存空间然后把 ‘你瞅啥’ 以最上面一行的编码方式存储
# 如果是python2运行此代码,当运行到s = ‘你瞅啥‘ 的时候会新开辟一个内存空间以gbk的格式存进去
# 所以打印终端必须是gbk,否则会出现错误
#_*_coding:gbk_*_ s = ‘你愁啥‘ print(s, type(s))
# 如果是python2的话一般会在字符串前面加上u,直接把字符串解码成unicode格式 #_*_coding:gbk_*_ s = u‘你愁啥‘ # 相当于执行了 s = ‘你瞅啥‘.decode(‘gbk‘) print(s, type(s))
标签:代码 style 打开 内容 str src 通过 出现 color
原文地址:https://www.cnblogs.com/huwentao/p/9750547.html