标签:art img 就是 基于 决定 qps 应用 代码实现 无法自动
一般生产环境单机所能承受的QPS压力为2w左右,过大的压力会导致服务器爆炸。即便是单机能够撑住2w QPS,一般也不会这么做,生产环境一般会预留50%的冗余能力,防止QPS因为某个热门的活动而爆炸。当QPS超过单机所能承受的压力时,自然而然会想到引入分布式集群。那么,某一个请求会被哪台服务器处理呢,这是随机的,还是说按照一定的规则处理的?这就是负载均衡算法所要干的事。
负载均衡器就是实现一种或者多种负载均衡算法的软件或者硬件设备。负载均衡器根据协议层的不同,通常又分为两种,第一种在四层传输层实现,第二种就是在七层应用层实现。
很多专用的硬件负载均衡器都支持在TCP层实现负载均衡,效率高。当然TCP层实现负载均衡有它的缺点,如无法保存长连接等。所以一般类似于BAT这种大公司,都是多层负载均衡配合的。
一般纯软件实现的通常在应用层来实现,这也是应用比较多的一种实现方式。目前比较流行的实现有Nginx、HAProxy、Keepalived等。当然Linux内核自带的LVS(Linux Virtual Server)就是四层的实现。
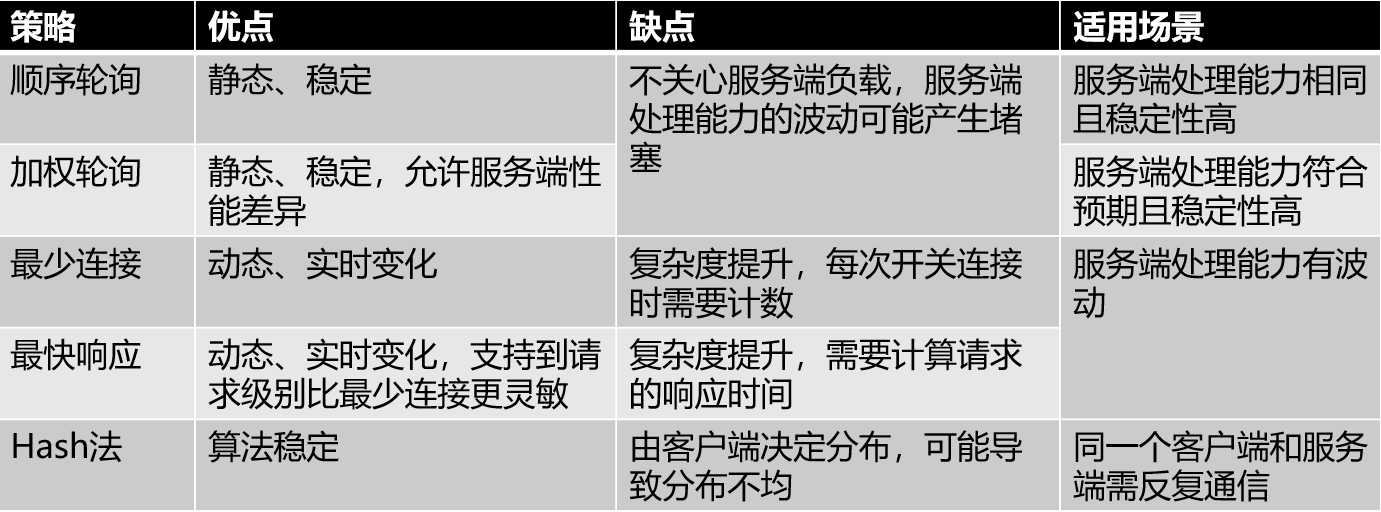
轮询是一种很简单的实现,依次将请求分配给后端服务器。
加权本质是一种带优先级的方式,加权轮询就是一种改进的轮询算法,轮询算法是权值相同的加权轮询。需要给后端每个服务器设置不同的权值,决定分配的请求数比例。这个算法应用就相当广泛了,对于无状态的负载场景,非常适合。
随机把请求分配给后端服务器。请求分配的均匀程度依赖于随机算法了,因为实现简单,常常用于配合处理一些极端的情况,如出现热点请求,这个时候就可以random到任意一台后端,以分散热点。当然缺点也不言而喻。
哈希算法想必大家并不陌生,应用最为广泛。根据Source IP、 Destination IP、URL、或者其它,算hash值或者md5,再采用取模。比如有N台服务器: S1、S2、S3……Sn
hash值 % N

显然,相同的请求会被映射到相同的后端。这非常适合维护长连接和提高命中率。
但是它天生也有一些缺点。比如说,现在某个请求通过哈希被映射到S3上去了,如果S3宕机了,就不得不二次Hash,重新计算路由时会剔除宕机的后端。
hash值 % (N - 1)
这样会导致几乎所有请求路由产生变化。由此导致命中率的急剧下降。当然一般生产环境通过提供S3的备机来解决这种问题,但是主备之间切换也是需要时间,它们之间的数据同步也是有延时的。所以需要根据业务场景来权衡了。
扩容也会有类似的问题,计算路由公式变为:
hash值 % (N + 1)
为了解决这种问题,一般生产环境可能采用成倍扩容的方式。N -> 2N,这样求路由可以做到与原来保持一致。当然必不可少的造成机器资源的浪费。请各位看官自行权衡。
对于热点请求,这种Hash算法也可能成在雪崩效应,取决于采用何种Hash,基于URL还是基于IP等。总之,不能把热点请求路由到单机上,否则单机撑不住,会逐个逐个被打爆,也就是雪崩效应。
最小连接数(Least Connection),把请求分配给活动连接数最小的后端服务器。它通过活动来估计服务器的负载。比较智能,但需要维护后端服务器的连接列表。
加权最小连接数(Weighted Least Connection),在后端服务器性能差异较大的情况下,可以优化LC的性能,高权值的服务可以承受更多的连接负载。
最短响应时间(Least Response Time),把请求分配给平均响应时间最短的后端服务器。平均响应时间可以通过ping探测请求或者正常请求响应时间获取。
RT(Response Time)是衡量服务器负载的一个非常重要的指标。对于响应很慢的服务器,说明其负载一般很高了,应该降低它的QPS。
之前有人说使用CPU占用率作为负载均衡的指标,只能说没理解CPU占用率的实质。理论上CPU占用率是越高越好,说明服务充分利用了CPU资源。但对于设计不合理的程序导致的CPU占用过高这是程序的设计问题,并不违背这条理论。
标签:art img 就是 基于 决定 qps 应用 代码实现 无法自动
原文地址:https://www.cnblogs.com/kaleidoscope/p/9754489.html