标签:list cond 定义 barcode default project 好的 workflow lda
setwd(‘D:/tcgabio‘)
rm(list = ls())
# TCGA-12-4567-01-blah-blah --> 这是Normal
# TCGA-12-4567-11-blah-blah --> 这是tumor
# 注意黑体的部分。01-09是tumor;10-19是Normal;20-29是Control
library(TCGAbiolinks)
# 下载前的query
query <- GDCquery(project = "TCGA-COAD",
data.category = "Transcriptome Profiling",
data.type = "Gene Expression Quantification",
workflow.type = "HTSeq - FPKM-UQ")
GDCdownload(query)
# 将下载好的query转换成一个SummerizedExperiment的文件,这个以rda为后缀的文件是一个总结性文件,
# 有了它,我们可以不再需要之前下载的raw数据,所以后面的remove.files.prepared可以选择True,
# 这样会把之前下载的大量文件删除,当然也可以留着不删除(即default)。
dataCOAD <- GDCprepare(query, save = TRUE,
save.filename = "dataCOAD_summerizedExperiment.rda",
remove.files.prepared = TRUE)
# 可以看一看rda文件,用到的package是SummarizedExperiment
library(SummarizedExperiment)
samples.information=colData(dataCOAD)
# 数据准备好了,我们接下来开始进行DEA分析。所谓DEA,也就是Differential Expression Analysis,将Tumor组和对照组进行比较。
# 首先,将刚才GDCprepare好的数据进行normalization,用normalization()
# 这里注意geneInfo=geneInfoHT,default其实是geneInfo,但由于我们前面选择的是HTseq,所以要选择geneInfoHT
dataNorm <- TCGAanalyze_Normalization(tabDF = dataCOAD, geneInfo = geneInfoHT)
# 之后,常规选择,用Filtering()
dataFilt <- TCGAanalyze_Filtering(tabDF = dataNorm,
method ="quantile",
qnt.cut = 0.25)
# 接着,定义对照组(这里的对照组是Solid normal tissue),用到SampleType(),定义肿瘤组,用SampleType()
samplesNT <- TCGAquery_SampleTypes(barcode = colnames(dataFilt),
typesample = c("NT"))
samplesTP <- TCGAquery_SampleTypes(barcode = colnames(dataFilt),
typesample = c("TP"))
# 进行DEA分析,用到DEA()
dataDEGs <- TCGAanalyze_DEA(mat1 =dataFilt[,samplesNT],
mat2 = dataFilt[,samplesTP],
Cond1type = "Normal",
Cond2type = "Tumor",
fdr.cut = 0.01 ,
logFC.cut = 1,
method = "glmLRT")
# 最后,将分析好的数据整入进一个表格里,用到LevelTab()
dataDEGsFiltLevel <- TCGAanalyze_LevelTab(dataDEGs,"Tumor","Normal",
dataFilt[,samplesTP],dataFilt[,samplesNT])
# 将表格保存到一个csv的文件
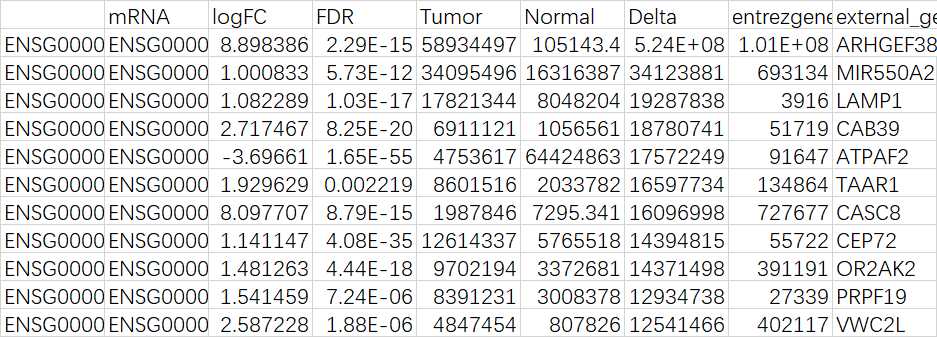
write.csv(dataDEGsFiltLevel,file="DEA_COAD.csv")
#最后得到得csv文件如下:
标签:list cond 定义 barcode default project 好的 workflow lda
原文地址:https://www.cnblogs.com/chinahack/p/9762216.html