标签:爸爸 www link return detail 路径 elements jieba jpg
一开始是想用qq空间说说做词云的,然而qq空间需要用cookies以及其他加密的东西,退而求其次搞搞新闻吧。
直接上代码了
# -*-coding:utf-8 -*- from selenium import webdriver import wordcloud #词云制作器 import jieba#强大的中文分词库 from scipy.misc import imread#读取图片 import time url=‘https://news.nuist.edu.cn/main.htm‘ news=webdriver.Chrome() news.get(url) def getnews(): raw="" news.find_element_by_link_text(‘+更多‘).click() for n in range(1,60): news.find_element_by_class_name(‘pageNum‘).send_keys(str(n)) news.find_element_by_class_name(‘pagingJump‘).click()#换页读取 boxes=news.find_elements_by_xpath(‘//span[@class="col_title"]/a[@target="_blank"]‘)xpath读取新闻标题 for box in boxes: raw+=box.text return raw def delit(raw):#去除中文字符,后来发现好像多此一步 r = ‘,。、【 】 “”:;()《》‘ for i in r: if i in raw: raw=raw.replace(i,‘‘) return raw def makecloud(raw): words=‘ ‘.join(jieba.lcut(raw)) mask=imread(‘apicture.JPG‘)#背景图片 cloud=wordcloud.WordCloud(font_path=‘msyh.ttc‘,width=1080,height=720,mask=mask,max_words=400) cloud.generate(words) cloud.to_file(‘pic.png‘) def main(): raw=getnews() raw1=delit(raw) makecloud(raw1) news.close() main()
有时候我们在html源码里面难以获得我们想要的元素的id,class只有不特殊的tag时候怎么办?这时候就要用xpath方法来查找。
我很讨厌给你一堆定义,那就直接上例子:
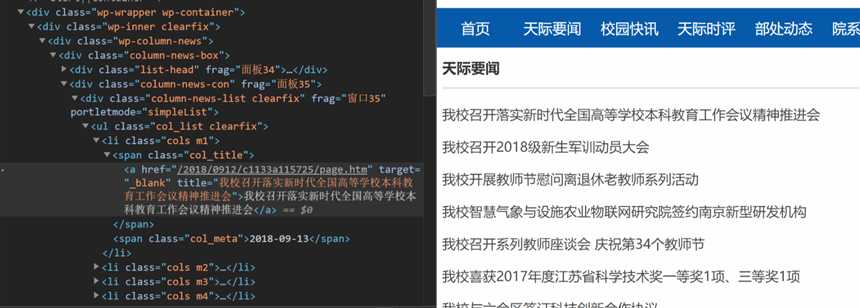
我要提取这一段文字,然而不能用find_element_by_id,也不能用classname,甚至因为链接是变化的所以连linktext也不行,这时候就只能硬着头皮来学xpath了
首先xpath提供了 // 方法就是任意位置查找,相对/根目录的一长串绝对路径,这里 我们的元素可以这么输入:
//spam[@class="col_title"]/a[@target="_blank"]
啥意思呢,上面图片我们可以看到一堆层级关系我们不管,我们只找新闻标签a和父级,a有target属性值为_blank,那么a[@target=‘_blank‘]就是标签名字为a,属性叫target且值为_blank的元素
但是我们往下翻有些不相关的信息也是这个值,那这个标签加上他爸爸总不一样了吧,加上父级/,标签为span,属性class值为”col_title“的,总归不一样了吧。
当然再不济叫上爷爷级总行了。 这种方法是html5的,当然selenium也加上了这个功能。
关于wordcloud和jieba的使用,参看https://www.icourse163.org/learn/BIT-268001?tid=1002788003#/learn/content?type=detail&id=1004116227
好了,说这么多展示一下结果

selenium爬取新闻做成词云(以及selenium的xpath查找方法)
标签:爸爸 www link return detail 路径 elements jieba jpg
原文地址:https://www.cnblogs.com/batt1ebear/p/9763764.html