标签:文件的 客户端 行合并 位置 nod bubuko 通过 lock int
NameNode主要保存了下面的内容
1-Block和文件之间的关系,即某一个特定文件都有哪些Block;
2-每一个Block存储在什么位置(DataNode上面);
NameNode如何保证元数据的可靠性
fsimage 和内存中保存的元数据互为镜像;
edits.log中存储了一段时间内所有的元数据操作;edits.log文件大小是固定的(默认是64M),那么每当edits.log文件满了,那么将这段时间之内新产生的元数据加到fsimage中,注意这个过程不是直接在内存中持久化,而是将edits.log文件和fsiamge进行合并;由于这个合并操作会占用一定的cpu和内存资源,所以合并操作是在secondaryNameNode上面进行的。在合并期间所产生的元数据操作记录都保存在edits.new文件中,即下图的第3步。
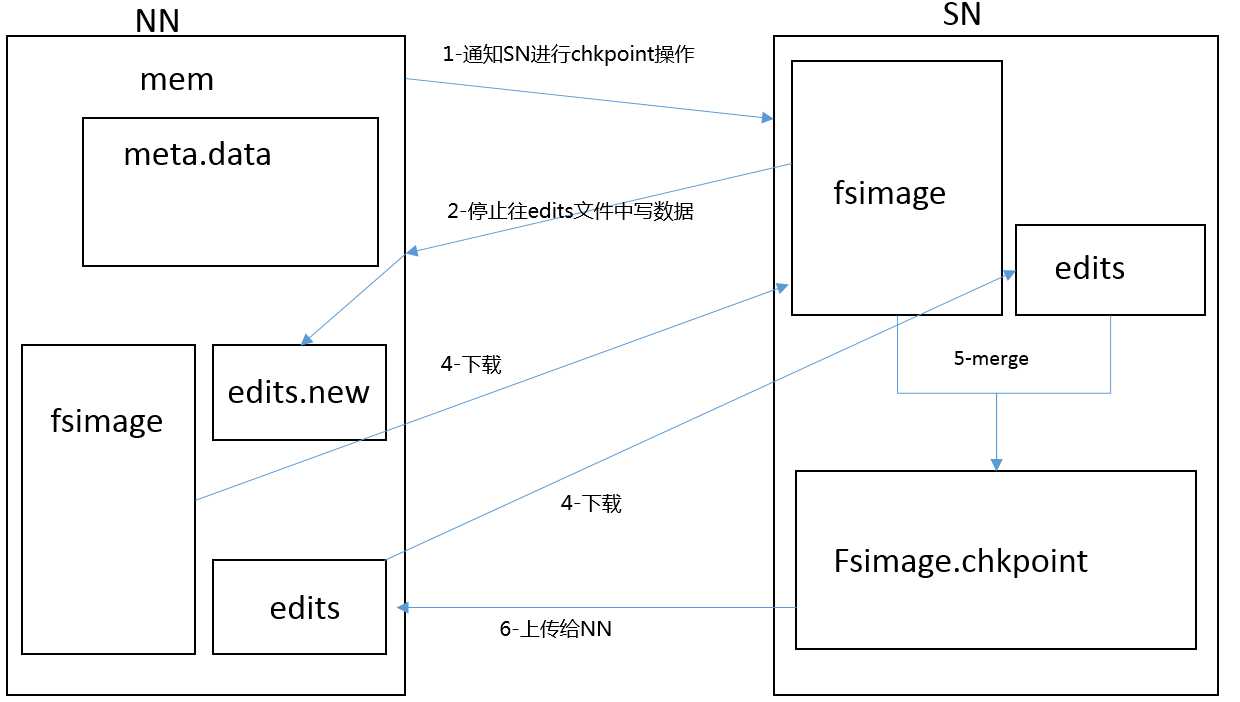
1-客户端上传文件时,NN首先给edits.log文件中记录数据操作日志;
2-客户端得到NN返回的DN的位置,开始上传文件,完成之后返回成功信息给NN,NN就在内存中写入这次上传操作的新产生的元数据信息,并且将操作内容持久化到edits.log文件中;
3-知道edit.log文件被写满,那么开始合并;
Secondar要namenode工作流程;
1-secondary namenode通知namenode切换edits文件;
2-secondary namenode 通知namenode获得fsimage和edits文件(通过http);
3-secondary namenode通过将fsimage载入内存、然后开始合并edits;
4-secondary namenode将新的image发回给namenode;
5-namenode用新的fsimage替换就得fsimage文件;
什么时候checkpoint
1-通过配置项fs.checkpoint.period执行两次checkpoint的最大时间间隔,默认是3600;
2fs.checkpoint.size 指定edits文件的最大值,一旦超过这个最大阈值,那么就会强制触发checkpoint,无论是不是是达到最大的时间间隔。默认的大小是64M
NameNode HA模式
待续。。。。
标签:文件的 客户端 行合并 位置 nod bubuko 通过 lock int
原文地址:https://www.cnblogs.com/maxigang/p/9765416.html