标签:put 搜索 sso add 属性 efault 项目文件 sel sci
安装scrapy会出现错误,我们选择anaconda3作为编译环境,搜索scrapy安装(有错误自查)
创建scrapy爬虫项目:
调出cmd,到相应目录:输入:
scrapy startproject stockstar
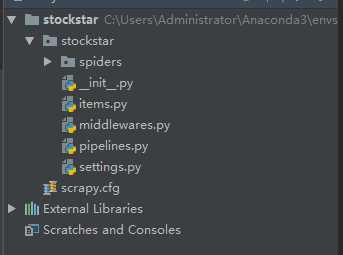
放置spide代码的目录文件 spider(用于编写爬虫)
项目中的item文件 items.py(用于保存所抓取的数据的容器,其存储方式类似于Python的字典)
项目的 中间件 middlewares.py(提供一种简便的机制,通过允许插入自定义代码来拓展scrapy的功能)
项目的pipelines文件 pipelines.py(核心处理器)
项目的 设置文件 settings.py
项目的配置文件 scrapy.cfg
创建项目后:在settings文件中有一句:
# Obey robots.txt rules ROBOTSTXT_OBEY = True
有时候我们需要关闭:设为false
右击文件夹,在弹出的快捷键中选择:Mark Directory as --Sources Root,这样使导入包的语法更简洁
1.定义一个item容器:
在items.py中编写:
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy from scrapy.loader import ItemLoader from scrapy.loader.processors import TakeFirst class StockstarItemLoader(ItemLoader): #自定义itemloader,用于存储爬虫所抓取的字段内容 default_output_processor = TakeFirst() class StockstarItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() code = scrapy.Field() #股票代码 abbr = scrapy.Field() #股票简称 last_trade = scrapy.Field() #最新价 chg_ratio = scrapy.Field() #涨跌幅 chg_amt = scrapy.Field() #涨跌额 chg_ratio_5min = scrapy.Field() #5分钟涨幅 volumn = scrapy.Field() #成交量 turn_over = scrapy.Field() #成交额
settings.py加上:
from scrapy.exporters import JsonItemExporter #默认显示的中文是阅读性较差的Unicode字符 #需定义子类显示出原来的字符集(将父类的ensure——ascii属性设置为False即可) class CustomJsonLinesItemExporter(JsonItemExporter): def __init__(self,file,**kwargs): super(CustomJsonLinesItemExporter,self).__init__(file,ensure_ascii=False,**kwargs) #启用新定义的Exporter类 FEED_EXPORTERS = { ‘json‘:‘stockstar.settings.CustomJsonLinesItemExporter‘, } DOWNLOAD_DELAY = 0.25
cmd进入项目文件:
输入:scrapy genspider stock quote.stockstar.com,生产spider代码
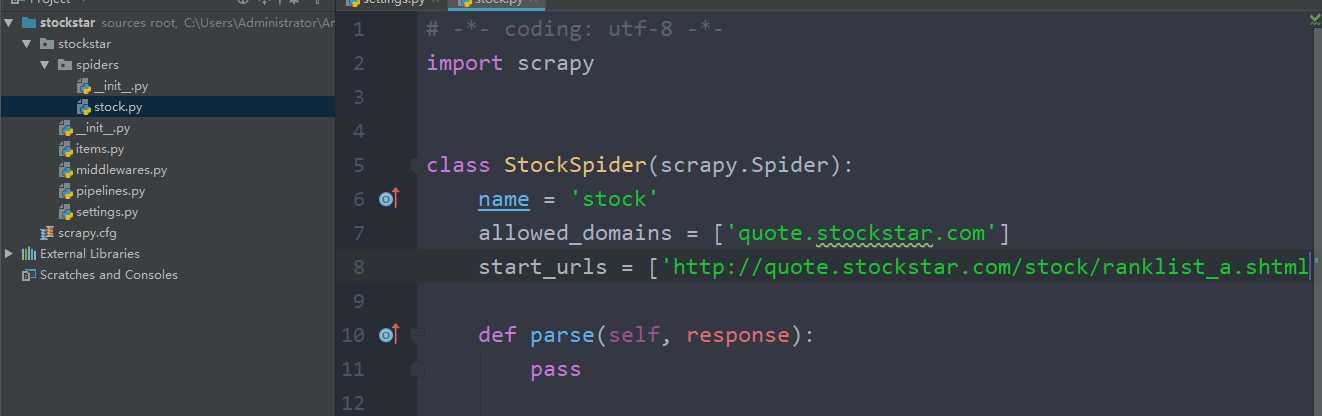
stock.py
# -*- coding: utf-8 -*- import scrapy from items import StockstarItem,StockstarItemLoader class StockSpider(scrapy.Spider): name = ‘stock‘ #定义爬虫名 allowed_domains = [‘quote.stockstar.com‘]#定义爬虫域 start_urls = [‘http://quote.stockstar.com/stock/ranklist_a_3_1_1.html‘]#定义爬虫连接 def parse(self, response):#撰写爬虫逻辑 page = int(response.url.split("_")[-1].split(".")[0])#抓取页码 item_nodes = response.css(‘#datalist tr‘) for item_node in item_nodes: #根据item文件所定义的字段内容,进行字段内容的抓取 item_loader = StockstarItemLoader(item=StockstarItem(),selector=item_node) item_loader.add_css("code","td:nth-child(1) a::text") item_loader.add_css("abbr","td:nth-child(2) a::text") item_loader.add_css("last_trade","td:nth-child(3) span::text") item_loader.add_css("chg_ratio","td:nth-child(4) span::text") item_loader.add_css("chg_amt","td:nth-child(5) span::text") item_loader.add_css("chg_ratio_5min","td:nth-child(6) span::text") item_loader.add_css("volumn","td:nth-child(7)::text") item_loader.add_css("turn_over","td:nth-child(8)::text") stock_item = item_loader.load_item() yield stock_item if item_nodes: next_page = page+1 next_url = response.url.replace("{0}.html".format(page),"{0}.html".format(next_page)) yield scrapy.Request(url=next_url,callback=self.parse)
在stockstar下添加一个main.py
from scrapy.cmdline import execute execute(["scrapy","crawl","stock","-o","items.json"]) #等价于在cmd中输入:scrapy crawl stock -o items.json
执行:
标签:put 搜索 sso add 属性 efault 项目文件 sel sci
原文地址:https://www.cnblogs.com/alex-xxc/p/9768611.html