标签:bubuko ima arch col .com 遍历 ati 双向 under
深度学习做NLP的方法,基本上都是先将句子分词,然后每个词转化为对应的词向量序列。(https://kexue.fm/archives/4765)

第一个思路是RNN层,递归进行,但是RNN无法很好地学习到全局的结构信息,因为它本质是一个马尔科夫决策过程。
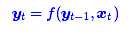
第二个思路是CNN层,其实CNN的方案也是很自然的,窗口式遍历,比如尺寸为3的卷积,就是
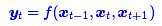
在FaceBook的论文中,纯粹使用卷积也完成了Seq2Seq的学习,是卷积的一个精致且极致的使用案例,CNN方便并行,而且容易捕捉到一些全局的结构信息,
Google的大作提供了第三个思路:纯Attention!单靠注意力就可以!RNN要逐步递归才能获得全局信息,因此一般要双向RNN才比较好;CNN事实上只能获取局部信息,是通过层叠来增大感受野;Attention的思路最为粗暴,它一步到位获取了全局信息!它的解决方案是:

关于注意力机制(《Attention is all you need》)
标签:bubuko ima arch col .com 遍历 ati 双向 under
原文地址:https://www.cnblogs.com/Ann21/p/9784444.html