标签:信息 ssm sadd ecif 建立 ESS 9.png user 激活
undo的作用
使用undo表空间存放从数据文件读出的数据块的前镜像,提供以下4种情况所需的信息:
1.回滚事物:rollback
2.读一致性:当长查询发出后,如果需要保存在undo的前镜像可能需要undo构造CR块
3.实例的恢复:实例恢复(undo—>rollback)
4.闪回技术:flashback query、flashback table等
undo的管理模式
1.manaual 手工:roll segment(淘汰)
2.auto自动:undo tablespace(init parameter:undo_management=auto)
查看undo表空间被哪个表空间激活
SQL>show parameter undo

查看undo表空间下的段表
SQL>select * from v$rollname;
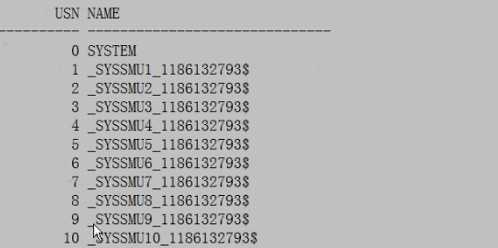
undo表空间管理
1.可以建立多个undo表空间,但一个时刻只有一个处于active;
2.处于active状态的undo tablespace不能offline和drop;
SQL>select tablespace_name,status,contents from dba_tablespace;
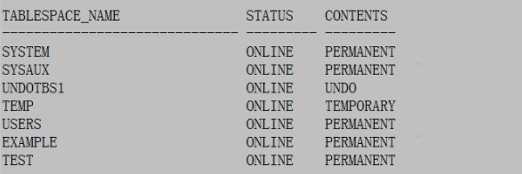
创建undo表空间:开始是100M,空间不够可以自动扩展,直到磁盘被撑爆(一般要给自动扩展的表空间做最大空间限制)
SQL>create undo tablespace undotbs2 datafile ‘/u01/oradata/timran11g/undotbs02.dbf‘ size 100m autoextend on;
原先undotbs01.dbf处于active状态,新添加的undotbs02.dbf是备用:
SQL>select tablespace_name,status,contents from dba_tablespace;
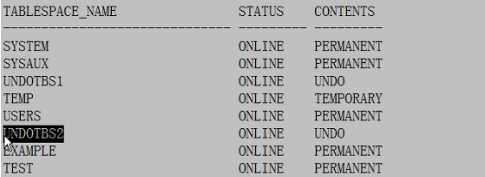
切换undo表空间:
SQL>alter system set undo_tablespace=‘undotbs2‘;
删除undo表空间:
处于激活状态的undo表空间无法删除:
SQL>drop tablespace undotbs2 including contents and datafiles;

处于未激活状态的undo表空间可以删除:
SQL>drop tablespace undotbs1 including contents and datafiles;
undo表空间的4种状态
1.active:表示transaction(事物)还没有commit,不可覆盖;
2.unexpired:已经commit,但是还在undo_retention(保留期:单位S)内,不可以覆盖(非强制),加GUARANTEE属性后强制undo_retention内不覆盖。(事物已提交,但是再保留一段时间:1.保证一致性读;2.闪回)
SQL>show parameter undo

SQL>select tablespace_name,status,contents,retention from dba_tablespaces;
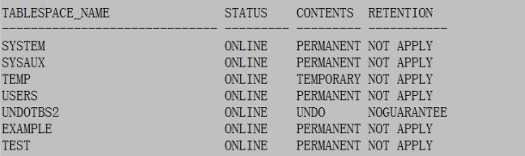
为表空间设置GUARANTEE属性:
SQL>alter tablespace undotbs2 retention guarantee;
3.expired:已经commit,且时间超过了undo_retention,随时可以覆盖
4.free:分配了但未使用过
undo_retention参数和undo autoextend on特性
undo_retention:参数规定了unexpired commit数据的保留期,它是保证一致性读和大多数闪回技术成功的关键。
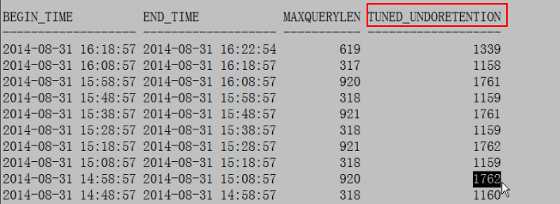
10R2以后,只要undo_management参数为auto,oracle会启用undo自动调优(AUM),它根据收集到的数据库中最长查询及撤销生成率自动调整undo_retention。在视图v$undostat中增加了一个字段TUNED_UNDORETENTION(每10分钟计算一次)就是自动调优undo_retention的预估值。如果想关闭AUM,可设置遗憾参数_undo_autotune-false。
将undo表空间设为autoextend on,这是DBCA创建数据库时的缺省设置,这一个特性将在undo空间不足时优先扩展新的空间,其次才是覆盖unexpired commit。如果autoextend on受物理限制不能成功,undo会在noguarantee的情况下盗用unexpired commit的空间,如果盗用不成,oracle报ORA-30036错误:“the specified undo tablespace has no more space available”解决的办法就是增加datafile扩展undo tablespace。另一个关于undo错误是ORA-01555:“rollback records needed by a reader for consistent read are overwritten by other writers” 它是由于无法在undo中构造一致性读时出现的错误。
避免上述报错:undo_managment=auto;打开表空间自动扩展。
SQL>select begin_time,end_time,maxquerylen,tuned_undoretention from v$undostat;
undo guarantee特性
SQL>select tablespace_name,status,contents,retention from dba_tablespaces;
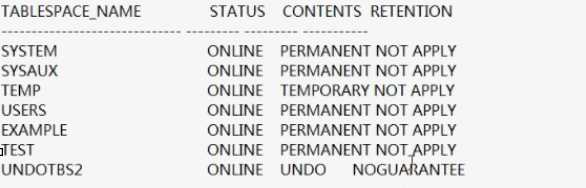
guarantee属性随undo表空间建立,可以修改:
SQL>alter tablespace undotbs2 retention guarantee; //保证在retention期间不允许被覆盖,缺省配置下,undo retention是noguarantee
undo信息的查询
1.v$session 查看用户建立的session,一般来说,一个session同时只能承载一个事务,建立了session未必有事务,只有事务处于活动状态时,v$transaction才能看到这个事务。换句话说,如果看到了事务(在v$transaction 里),那一定有个session和它对应,将两个视图连在一起,信息看的更为清楚。
SQL>select username,sid,serial# from v$session where username is not null; //SID和SERIAL#组合可以唯一定位一个session

2.v$transaction 查看当前处于活跃状态的事物
SQL>select * from v$transaction;
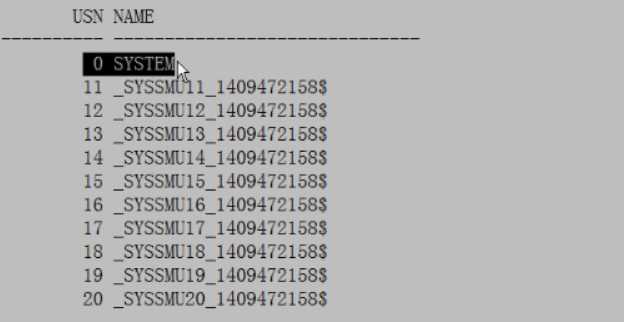
3.v$rollname undo段的名称
SQL>select * from v$rollname;
一般来说,一个session同时只能承载一个事务,建立了session未必有事务,只有事务处于活动状态时,v$transaction才能看到这个事务。换句话说,如果看到了事务(在v$transaction 里),那一定有个session和它对应,将两个视图连在一起,信息看的更为清楚。
示例:
1.打开一个cmd会话s1,scott用户登陆数据库
2.打开另一个会话s2,sys用户登陆数据库,查看此时有多少个会话连接上来
SQL>select username,sid,serial# from v$session where username is not null;

3.s1会话下产生一个事物
SQL>update emp1 set sal=1000 where empno=7788;
4.查看事物:哪些session上产生哪些事物
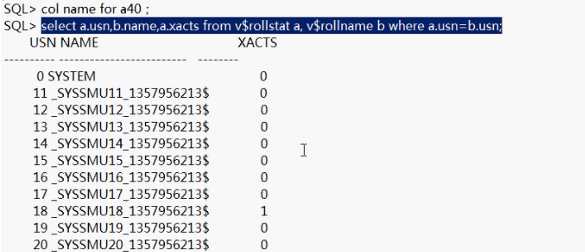
SQL>select a.sid,a.serial,a.username,b.xidusn,b.xidslot,b.ubablk,b.status from v$session a,v$transaction b where a.saddr=b.ses_addr;

//两表联查,sid和serial#在v$session里,在v$transaction里xidusn是undo segment的id,xidslot是事物槽的id,ubablk是undo块号。对照上面看,下面语句显示出——SYSSMU18是一个活动段,与xinusn=18吻合,说明这个段被读进buffer了。
注意:一个事务只能在一个undo段上扩展,不能跨其它段。
测试:模拟数据库open下的undo数据文件损坏或修复
如果数据库打开时,当前undo坏掉的话,比如现在undotbs2出现了介质损坏,那么数据库就不能继续DML操作。如果这时undotbs2表空间上还有active状态的事物(未提交的事物),oracle会将其下的所有段都标志位NEEDS RECOVERY,这时如果有备份可用恢复这个undotbs2,但如果没有备份,只能使用新建的undo替代损坏的undo,那么损坏undo上未提交的事物也将丢弃。但oracle没有提供自动解决NEEDS RECOVERY的机制,如果想删除这损坏的UNDO表空间,必须另做处理(需要系统择时重启)。下面将举例模拟这种情况:
存在一个事物:
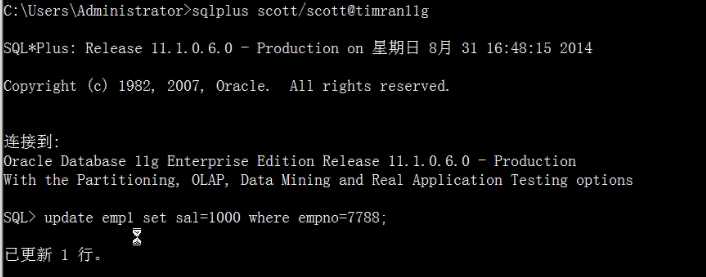
删除undo表空间的数据文件,再做update操作会报错:
$rm -f undotbs02.dbf
$sqlplus / as sysdba
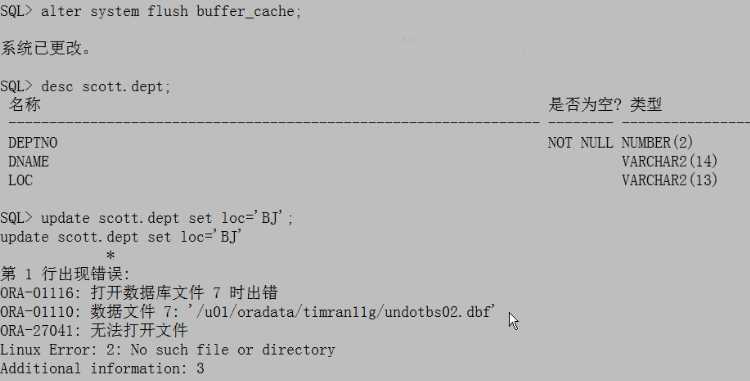
SQL>shutdown abort
SQL>startup mount
SQL>select file#,checkpoint_change#,name from v$datafile;
7 968161 /u01/oradata/timran11g/undotbs02.dbf
上述checkpoint_change#从控制文件中读出,底层文件损坏,数据库不知道,所以在这里还能看到undo数据文件;
查看数据文件,这时候undo数据文件删除,所以SCN为0,与上述报错7号文件相同:
SQL>select file#,checkpoint_change#,name from v$datafile_header;

在mount阶段可以只读控制文件,并不检测SCN一致性,要想打开数据库必须要把7号文件offline:
SQL>alter database datafile 7 offline;
数据库已更改
SQL>alter database open;
数据库已更改
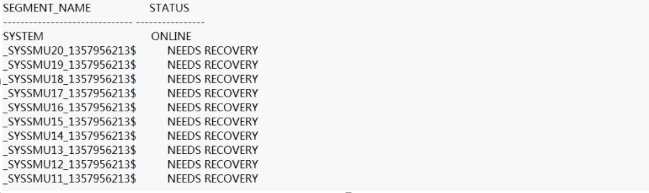
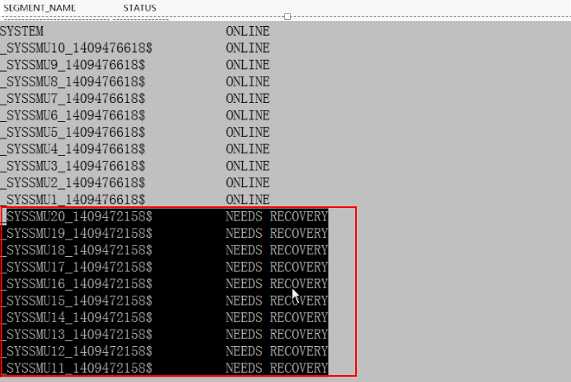
这时只有system的undo段,其它段缺失(needs recovery:表示这些段需要修复),无法执行DML操作:
SQL>select * from v$rollname;
USN NAME
0 SYSTEM
SQL>select segment_name,status from dba_rollback_segs; //该静态视图可用列出所有(online或offline)undo信息
新建一个undo表空间:
SQL>create undo tablespace undotbs1 datafile ‘/u01/oradata/timran11g/undotbs01.dbf‘ size 100m autoextend on;
SQL>show parameter undo

SQL>alter system set undo_tablespace=‘undotbs1‘;
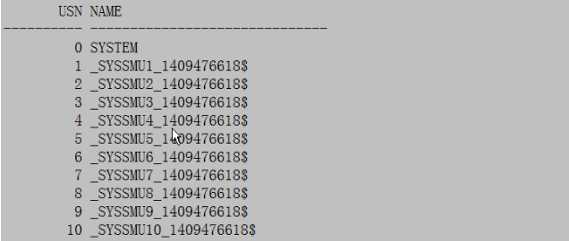
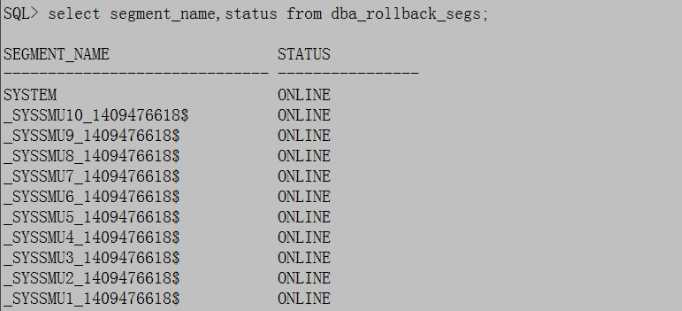
此时提供视图查看undo已经恢复:
SQL>select * from v$rollname;
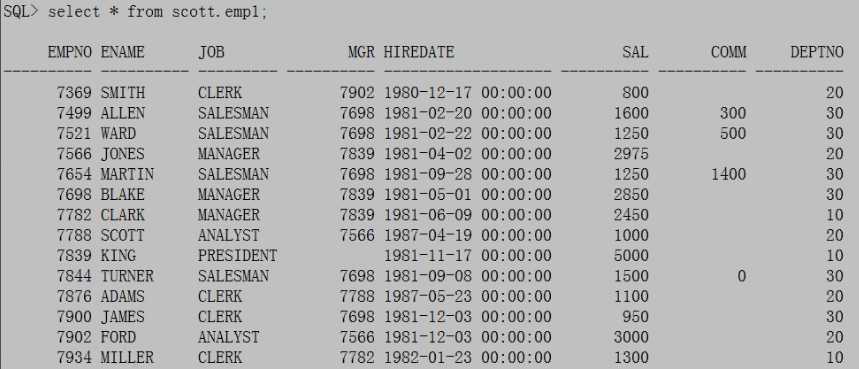
提供另外的一个视图会发现原来未提交事物对应的undo段未解决,将导致表被锁定无法对表进行DML操作:
SQL>select * from scott.emp1;

SQL>select segment_name,status from dba_rollback_segs; //该静态视图可以列出(online和offline)undo段信息
删除表空间undotbs2报存在活跃段,无法删除:
SQL>drop tablespace undotbs2 including contents and datafiles;

解决办法:
解决办法有两个:1.使用备份恢复。2.使用oracle提供的隐含参数_CORRUPTED_ROLLBACK_SEGMENTS。
假设没有备份,使用修改系统隐含参数的方法(即告诉数据库这几个段是坏段)
SQL>create pfile from spfile;
SQL>shutdown abort
#vi /u01/oracle/dbs/inittimran11g.ora //在静态参数文件里第一行插入以下内容

然后使用静态参数文件启动数据库
SQL>startup pfile=‘/u01/oracle/dbs/inittimran11g.ora‘
SQL>drop rollback segment ‘_SYSSMU11_1357956213$‘; //将换段进行删除
SQL>drop rollback segment ‘_SYSSMU12_1357956213$‘;
.....
此时表空间段处于正常状态:
此时scott.emp1就可以进行正常的DML操作:
注意:特殊情况下若还是无法删除undo段,则测试修改字典:
SQL>select * from v$tablespace; //记下要删除的undo对应的ts#号,比如ts#=2则执行以下语句
SQL>update seg$ set type#=3 where ts#=2;
标签:信息 ssm sadd ecif 建立 ESS 9.png user 激活
原文地址:https://www.cnblogs.com/lriwu/p/9504245.html
{kind=link}