标签:权重 park compareto property ack use div reac 文件中
前面我们应知道了一个任务提交会由DAG拆分为job,stage,task,最后提交给TaskScheduler,在提交taskscheduler中会根据master初始化taskscheduler和schedulerbackend两个类,并且初始化一个调度池;
根据mode初始化调度池pool
def initialize(backend: SchedulerBackend) { this.backend = backend // temporarily set rootPool name to empty 这里可以看到调度池初始化最小设置为0 rootPool = new Pool("", schedulingMode, 0, 0) schedulableBuilder = { schedulingMode match { case SchedulingMode.FIFO => new FIFOSchedulableBuilder(rootPool) case SchedulingMode.FAIR => new FairSchedulableBuilder(rootPool, conf) } } schedulableBuilder.buildPools() }
这个会根据spark.scheduler.mode 来设置FIFO or FAIR,默认的是FIFO模式;
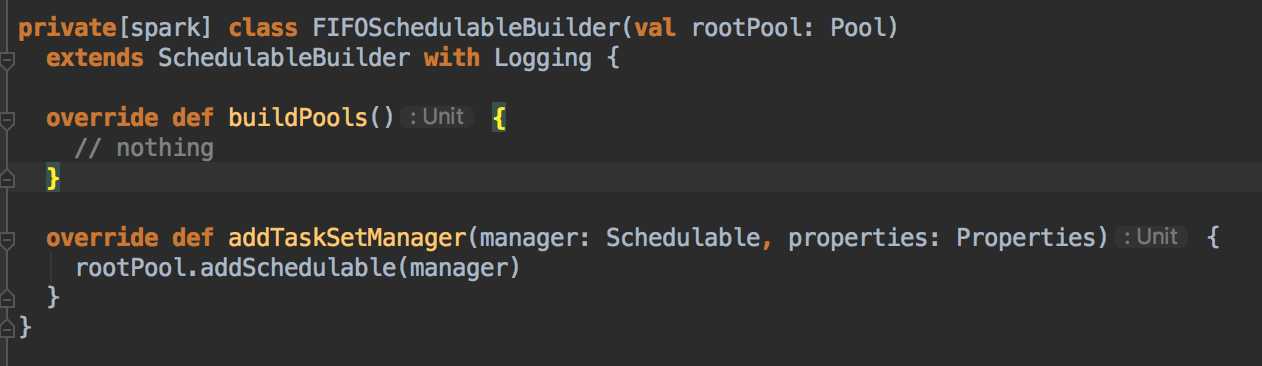
FIFO模式什么都不做,实现默认的schedulerableBUilder方法,建立的调度池也为空,addTasksetmaneger也是调用默认的;
可以简单的理解为,默认模式FIFO什么也不做。。
fair模式则重写了buildpools的方法,读取默认路径 $SPARK_HOME/conf/fairscheduler.xml文件,也可以通过参数spark.scheduler.allocation.file设置用户自定义配置文件。
文件中配置的是
poolname 线程池名
schedulermode 调度模式(FIFO,FAIR仅有两种)
minshare 初始大小的线程核数
wight 调度池的权重
override def buildPools() { var is: Option[InputStream] = None try { is = Option { schedulerAllocFile.map { f => new FileInputStream(f) }.getOrElse { Utils.getSparkClassLoader.getResourceAsStream(DEFAULT_SCHEDULER_FILE) } } is.foreach { i => buildFairSchedulerPool(i) } } finally { is.foreach(_.close()) } // finally create "default" pool buildDefaultPool() }
同时也重写了addtaskmanager方法
override def addTaskSetManager(manager: Schedulable, properties: Properties) { var poolName = DEFAULT_POOL_NAME var parentPool = rootPool.getSchedulableByName(poolName) if (properties != null) { poolName = properties.getProperty(FAIR_SCHEDULER_PROPERTIES, DEFAULT_POOL_NAME) parentPool = rootPool.getSchedulableByName(poolName) if (parentPool == null) { // we will create a new pool that user has configured in app // instead of being defined in xml file parentPool = new Pool(poolName, DEFAULT_SCHEDULING_MODE, DEFAULT_MINIMUM_SHARE, DEFAULT_WEIGHT) rootPool.addSchedulable(parentPool) logInfo("Created pool %s, schedulingMode: %s, minShare: %d, weight: %d".format( poolName, DEFAULT_SCHEDULING_MODE, DEFAULT_MINIMUM_SHARE, DEFAULT_WEIGHT)) } } parentPool.addSchedulable(manager) logInfo("Added task set " + manager.name + " tasks to pool " + poolName) }
这一段逻辑中是把配置文件中的pool,或者default pool放入rootPool中,然后把TaskSetManager存入rootPool对应的子pool;
除了初始化的调度池不一致外,其实现的调度算法也不一致
实现的调度池Pool,在内部实现方法中也会根据mode不一致来实现调度的不同
var taskSetSchedulingAlgorithm: SchedulingAlgorithm = { schedulingMode match { case SchedulingMode.FAIR => new FairSchedulingAlgorithm() case SchedulingMode.FIFO => new FIFOSchedulingAlgorithm() } }
FIFO模式的调度方式很容易理解,比较stageID,谁小谁先执行;
这也很好理解,stageID小的任务一般来说是递归的最底层,是最先提交给调度池的;
private[spark] class FIFOSchedulingAlgorithm extends SchedulingAlgorithm { override def comparator(s1: Schedulable, s2: Schedulable): Boolean = { val priority1 = s1.priority val priority2 = s2.priority var res = math.signum(priority1 - priority2) if (res == 0) { val stageId1 = s1.stageId val stageId2 = s2.stageId res = math.signum(stageId1 - stageId2) } if (res < 0) { true } else { false } } }
fair模式来说的话,稍微复杂一点;
但是还是比较容易看懂,
1.先比较两个stage的 runningtask使用的核数,其实也可以理解为task的数量,谁小谁的优先级高;
2.比较两个stage的 runningtask 权重,谁的权重大谁先执行;
3.如果前面都一直,则比较名字了(字符串比较),谁大谁先执行;
private[spark] class FairSchedulingAlgorithm extends SchedulingAlgorithm { override def comparator(s1: Schedulable, s2: Schedulable): Boolean = { val minShare1 = s1.minShare val minShare2 = s2.minShare val runningTasks1 = s1.runningTasks val runningTasks2 = s2.runningTasks val s1Needy = runningTasks1 < minShare1 val s2Needy = runningTasks2 < minShare2 val minShareRatio1 = runningTasks1.toDouble / math.max(minShare1, 1.0).toDouble val minShareRatio2 = runningTasks2.toDouble / math.max(minShare2, 1.0).toDouble val taskToWeightRatio1 = runningTasks1.toDouble / s1.weight.toDouble val taskToWeightRatio2 = runningTasks2.toDouble / s2.weight.toDouble var compare: Int = 0 if (s1Needy && !s2Needy) { return true } else if (!s1Needy && s2Needy) { return false } else if (s1Needy && s2Needy) { compare = minShareRatio1.compareTo(minShareRatio2) } else { compare = taskToWeightRatio1.compareTo(taskToWeightRatio2) } if (compare < 0) { true } else if (compare > 0) { false } else { s1.name < s2.name } }
总结:虽然了解一下spark的调度模式,以前在执行中基本都没啥用到,没想到spark还有这样的隐藏功能。。。
标签:权重 park compareto property ack use div reac 文件中
原文地址:https://www.cnblogs.com/yankang/p/9786251.html