标签:增加 方式 nic 成功 运行 div script 加强 alt
Requests模块是一个用于网络访问的模块,其实类似的模块有很多,比如urllib,urllib2,httplib,httplib2,他们基本都提供相似的功能。
在上一篇我们已经使用urllib模块
而Requests会比urllib更加方便,可以节约我们大量的工作,它更加强大,所以更建议使用Requests。
requests里提供个各种请求方式
HTTP定义了与服务器进行交互的不同方式, 其中, 最基本的方法有四种: GET, POST, PUT, DELETE; 一个URL对应着一个网络上的资源, 这四种方法就对应着对这个资源的查询, 修改, 增加, 删除四个操作.上面的程序用到的requests.get()来读取指定网页的信息, 而不会对信息就行修改, 相当于是"只读". requests库提供了HTTP所有基本的请求方式, 都是一句话搞定
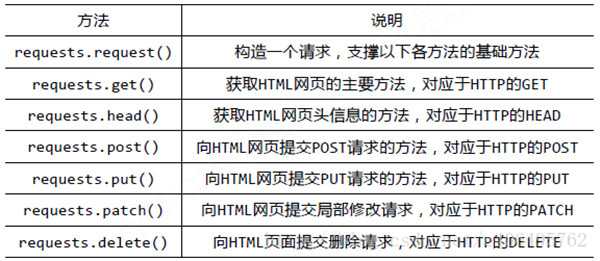
以上方法均是在此方法的基础上构建
requests.request(method, url, **kwargs)
import requests response = requests.get(‘http://httpbin.org/get‘) # 返回一个实例,包含了很多的信息
print(response.text) # 所请求网页的内容
通常我们会通过httpbin.org/get?key=val方式传递。Requests模块允许使用params关键字传递参数,以一个字典来传递这些参数。
比如我们想传递key1=value1,key2=value2到http://httpbin.org/get里面
构造的url:http://httpbin.org/get?key1=value1&key2=value2
import requests
data = {
"key1":"key1",
"key2":"key2"
}
response = requests.get("http://httpbin.org/get",params=data)
print(response.url)
运行结果如下
C:\Pycham\venv\Scripts\python.exe C:/Pycham/demoe3.py http://httpbin.org/get?key1=key1&key2=key2 Process finished with exit code 0
可以看到,参数之间用&隔开,参数名和参数值之间用=隔开
上述两种的结果是相同的,通过params参数传递一个字典内容,从而直接构造url
注意:通过传参字典的方式的时候,如果字典中的参数为None则不会添加到url上
requests.post()用法与requests.get()完全一致,特殊的是requests.post()有一个data参数,用来存放请求体数据
注意:同样的在发送post请求的时候也可以和发送get请求一样通过headers参数传递一个字典类型的数据
import requests
data = {
"name":"zhaofan",
"age":23
}
response = requests.post("http://httpbin.org/post",data=data)
print(response.text)
运行结果如下:
可以看到参数传成功了,然后服务器返回了我们传的数据。
C:\Pycham\venv\Scripts\python.exe C:/Pycham/demoe3.py
{
"args": {},
"data": "",
"files": {},
"form": {
"age": "23",
"name": "zhaofan"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "19",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.19.1"
},
"json": null,
"origin": "218.200.145.68",
"url": "http://httpbin.org/post"
}
有时候我们需要传送的信息不是表单形式的,需要我们传JSON格式的数据过去,所以我们可以用 json.dumps() 方法把表单数据序列化
import json
import requests
url = ‘http://httpbin.org/post‘
data = {‘some‘: ‘data‘}
r = requests.post(url, data=json.dumps(data))
print r.text
运行结果如下:
C:\Pycham\venv\Scripts\python.exe C:/Pycham/demoe3.py
{
"args": {},
"data": "{\"some\": \"data\"}",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "16",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.19.1"
},
"json": {
"some": "data"
},
"origin": "218.200.145.68",
"url": "http://httpbin.org/post"
}
如果想要上传文件,那么直接用 file 参数即可
import requests
url = ‘http://httpbin.org/post‘
files = {‘file‘: open(‘test.txt‘, ‘rb‘)}
r = requests.post(url, files=files)
print r.text
运行结果如下
{
"args": {},
"data": "",
"files": {
"file": "Hello World!"
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "156",
"Content-Type": "multipart/form-data; boundary=7d8eb5ff99a04c11bb3e862ce78d7000",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.9.1"
},
"json": null,
"url": "http://httpbin.org/post"
}
import requests import json response=requests.get(‘http://httpbin.org/get‘)
res1=json.loads(response.text) #太麻烦 res2=response.json() #直接获取json数据 print(res1 == res2) #True
import requests
respone=requests.get(‘http://www.jianshu.com‘)
# respone属性
print(respone.text)# 所请求网页的内容
print(respone.content)
print(respone.status_code) #返回状态码
print(respone.headers)# 网页的头
print(respone.cookies)# 网页的cookie内容
print(respone.cookies.get_dict())
print(respone.cookies.items())
print(respone.url) # 实际的网址
print(respone.history)
print(respone.encoding) # 所请求网页的编码方式
那r.text和r.content的区别是什么呢?
r.text是unicode编码的响应内容(r.text is the content of the response in unicode)
r.content是字符编码的响应内容(r.content is the content of the response in bytes)
text属性会尝试按照encoding属性自动将响应的内容进行转码后返回,如果encoding为None,requests会按照chardet(这是什么?)猜测正确的编码
如果你想取文本,可以通过r.text, 如果想取图片,文件,则可以通过r.content
针对响应内容是二进制文件(如图片)的场景,content属性获取响应的原始内容(以字节为单位)
标签:增加 方式 nic 成功 运行 div script 加强 alt
原文地址:https://www.cnblogs.com/-wenli/p/9792455.html