标签:根目录 rtp .com efault 命令行 字段 过程 ref span
一.安装依赖库
此处请确认你的python版本,如果你使用的是python3,那么在pip的时候和进入python命令行的时候要使用pip3和python3的命令
pip3 install django
pip3 install djangorestframework
二.创建项目
进入到pycharm的terminal下,运行如下命令创建一个新的项目
django-admin.py startproject myProject
我们创建一个新的APP,名字就叫api吧。随后会发现根目录下会多一个文件夹,这就是我们创建好的名为api的应用,我们会把api所需要用到的文件放在这个应用的文件夹当中。
python3 manage.py startapp api
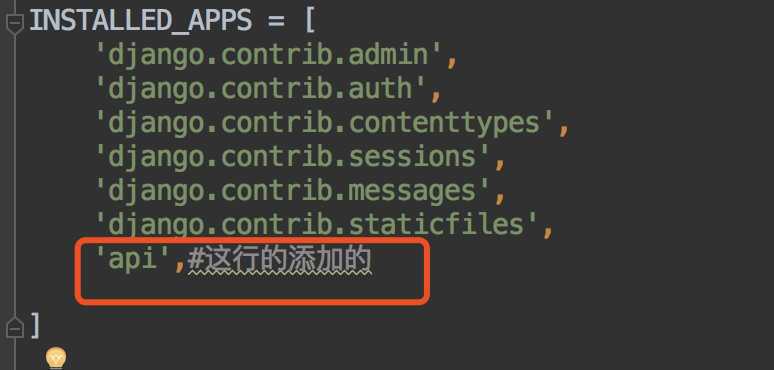
创建完app后,去myProject(或者你的自己命名的项目)文件夹下,找到setting.py,INSTALLED_APPS列表下添加APP.添加内容如下:
‘api‘,
创建一个管理员
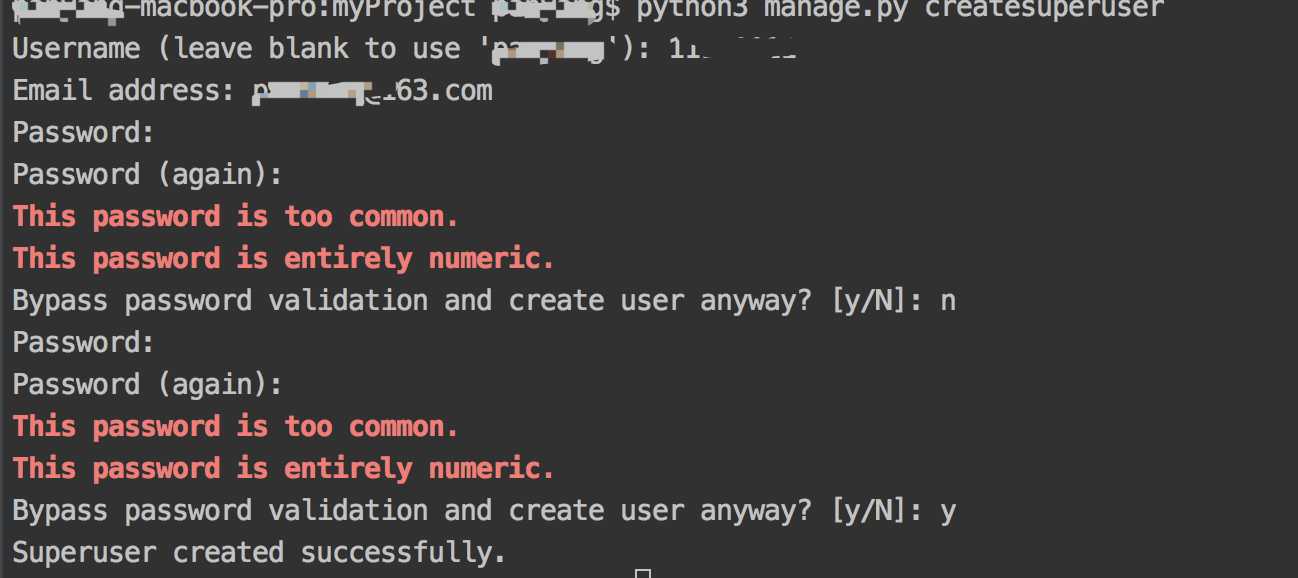
python3 manage.py createsuperuser
坑1:
此处如果运行这个命令报如下错误.这个错误表示没有这个app应用对应的数据表
![]()
分别这行以下两条命令
python3 manage.py makemigrations python3 manage.py migrate
然后按提示进行设置用户名密码就可以了
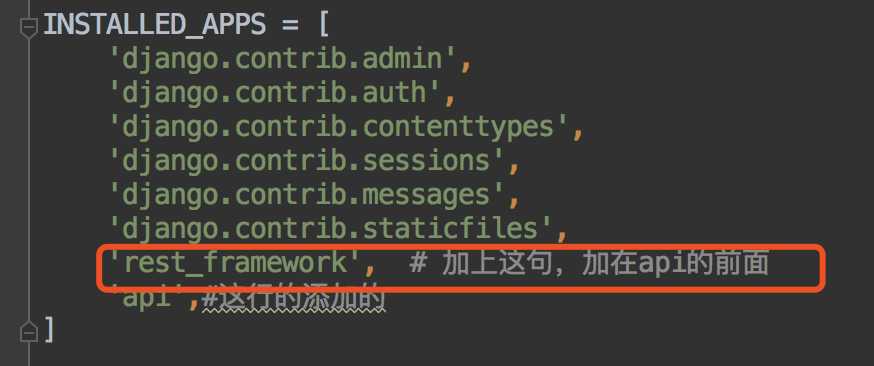
添加REST framework的依赖,在第一步的时候已经添加过了,现在我们去setting.py中添加下载好的依赖应用
‘rest_framework‘, #加上这句,加在api的前面
三.创建模型
我们以最经典的“学生类”来当我们本次试验的一个模型类。学生类暂且具有姓名、性别、学号等属性。
由于只是一个demo,为了方便我们就不再创建APP,直接在Api文件下的models.py文件内创建模型吧
from django.db import models
# Create your models here.
class Student(models.Model):
name=models.CharField(u‘姓名‘,max_length=100,default=‘no_name‘)
sex=models.CharField(u‘性别‘,max_length=50,default=‘male‘)
sid=models.CharField(u‘学号‘,max_length=100,default=‘0‘)
def __unicode__(self):
return ‘%d:%s‘%(self.pk,self.name)
django模型是与数据库相关的,与数据库相关的代码一般写在models.py中。Django中Models以类的形式表现,它包含了一些基本字段以及数据的一些行为。
models.CharField()中常用字段参数
max_length 表示字符长度,
default 表示默认值,
primary_key = True 设置为主键,
unique=True 不允许重复
auto_now 自动创建---无论添加或修改,都是当前操作的时间
auto_now_add 自动创建---永远是创建时的时间
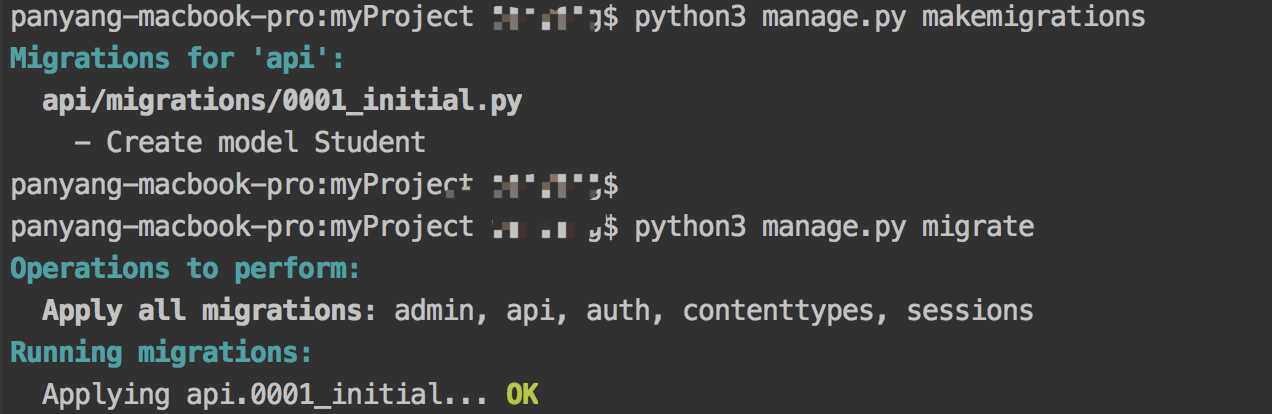
执行下面的命令
python3 manage.py makemigrations python3 manage.py migrate
我们用python自带的admin后台来测试一下。python admin后台是一个自带实现类似数据库客户端的功能,非常方便
在api文件夹下admin.py文件中,添加如下代码
from django.contrib import admin
# Register your models here.
from .models import Student
# 导入包
@admin.register(Student)
class BlogTypeAdmin(admin.ModelAdmin):
list_display=(‘pk‘,‘name‘) #在后台列表下显示的字段
添加完毕后,我们运行一下项目
在python terminal中运行
python3 manage.py runserver
在浏览器中输入:http://127.0.0.1:8000/admin 或者 http://localhost:8000/admin进入到项目中,并使用创建的用户名和密码登录,如下
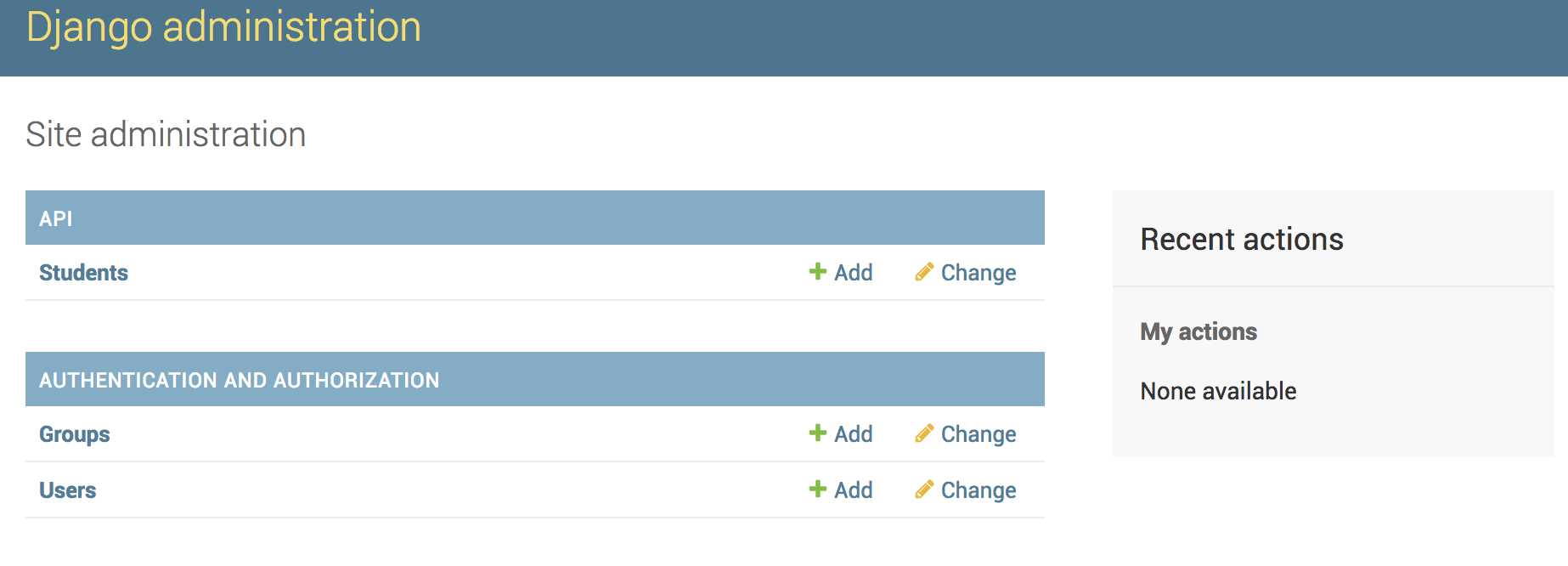
添加几条数据备用,在添加数据的时候的代码逻辑全由django帮我们处理好了,使用起来非常方便。
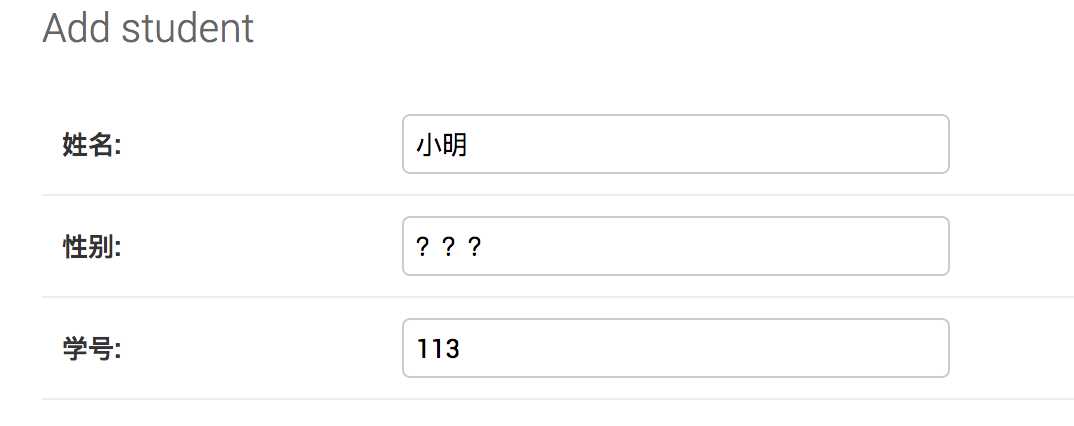
四.序列化
小知识:
在程序运行的过程中,所有的变量都是在内存中,比如,定义一个dict:
d = dict(name=‘Bob‘, age=20, score=88)
可以随时修改变量,比如把name改成‘Bill‘,但是一旦程序结束,变量所占用的内存就被操作系统全部回收。如果没有把修改后的‘Bill‘存储到磁盘上,下次重新运行程序,变量又被初始化为‘Bob‘。
我们把变量从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
在本项目中,序列化就是把我们需要查找的实体模型,从数据库中取出,并通过序列化的功能转换成通用的资源格式,也就是JSON。如如下格式
[
{
"pk": 3,
"name": "小王八",
"sex": "男",
"sid": "112"
},
{
"pk": 2,
"name": "小王",
"sex": "女",
"sid": "110"
},
]
现在我们来编写序列化功能。在api文件夹下创建一个名为serializers.py的文件。里面代码内容为:
from rest_framework import serializers
from .models import Student
class StudentSerializers(serializers.ModelSerializer):
class Meta:
model=Student
fields=(‘pk‘,‘name‘,‘sex‘,‘sid‘) # 需要序列化的属性
未完待续。。。。
标签:根目录 rtp .com efault 命令行 字段 过程 ref span
原文地址:https://www.cnblogs.com/panpan0301/p/9778629.html