标签:sys mis mon 行修改 pareto 插入 开始时间 大于 没有
一、查找:在查找池中查找目标元素或确定查找池中不存在该目标元素
二、排序:基于一个标准,将一组项目按照某个顺序排列
排序算法
顺序排序:选择排序、插入排序、冒泡排序
对数排序:快速排序、归并排序
n个元素排序:顺序排序大约n^2次比较,对数排序大约nlog2 n次比较
n较小时,这两类算法几乎不存在实际差别
选择排序:
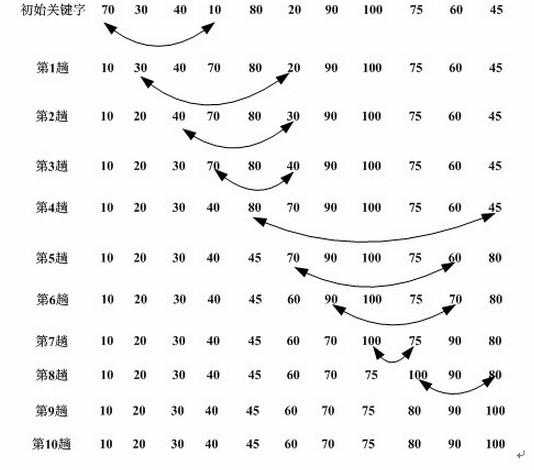
第1趟排序,在待排序数据arr[1]~arr[n]中选出最小的数据,将它与arrr[1]交换;
第2趟,在待排序数据arr[2]~arr[n]中选出最小的数据,将它与r[2]交换;
以此类推,第i趟在待排序数据arr[i]~arr[n]中选出最小的数据,将它与r[i]交换,直到全部排序完成。

反复地将某一特定值插入到元素列表的已排序的子集中来完成排序
需要注意的是,每次插入可能需要元素移位,并且每插入一次已排序子集都将多一个元素
n个元素,每一轮排序都将最大值移到最终位置,需比较n-1轮;
每一轮过后,下一轮需要比较的值就会少一个
冒泡排序的算法似乎还可以设计两边一起冒。。。
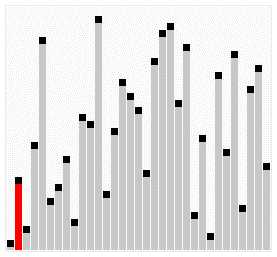
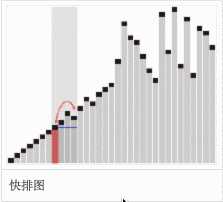
分区元素的选择是任意的,但最好选择列表的第一个元素,从而第一轮快速排序分区元素能把列表大致分为两半
持续对两个分区进快速排序,直至分区只含有一个元素,排序即完成
值得注意的是,决定放置好了初始分区元素,就不会对其进行考虑和移动了
归并排序包括"从上往下"和"从下往上"2种方式
如图所示:
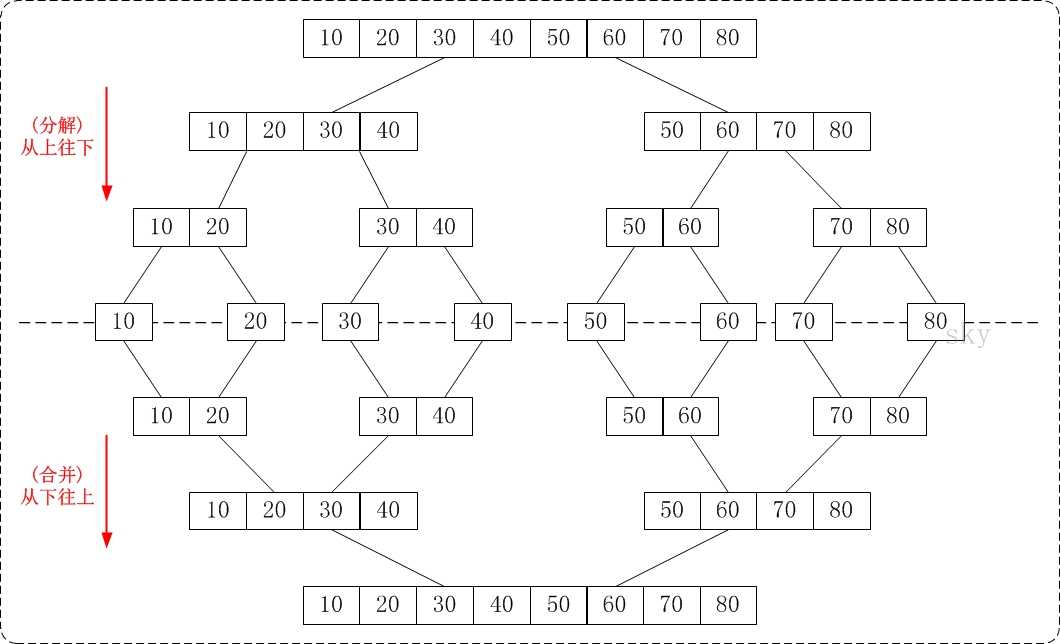
首先看到这个排序算法的时候,有一个疑惑:算法好像只是一半一半地将原列表元素分成只含有一个元素的子列表,然后再将只含有一个元素的子列表归并成一个新的已排好序的列表,即完成了排序。
那问题是,归并的时候是怎么把序排好的?
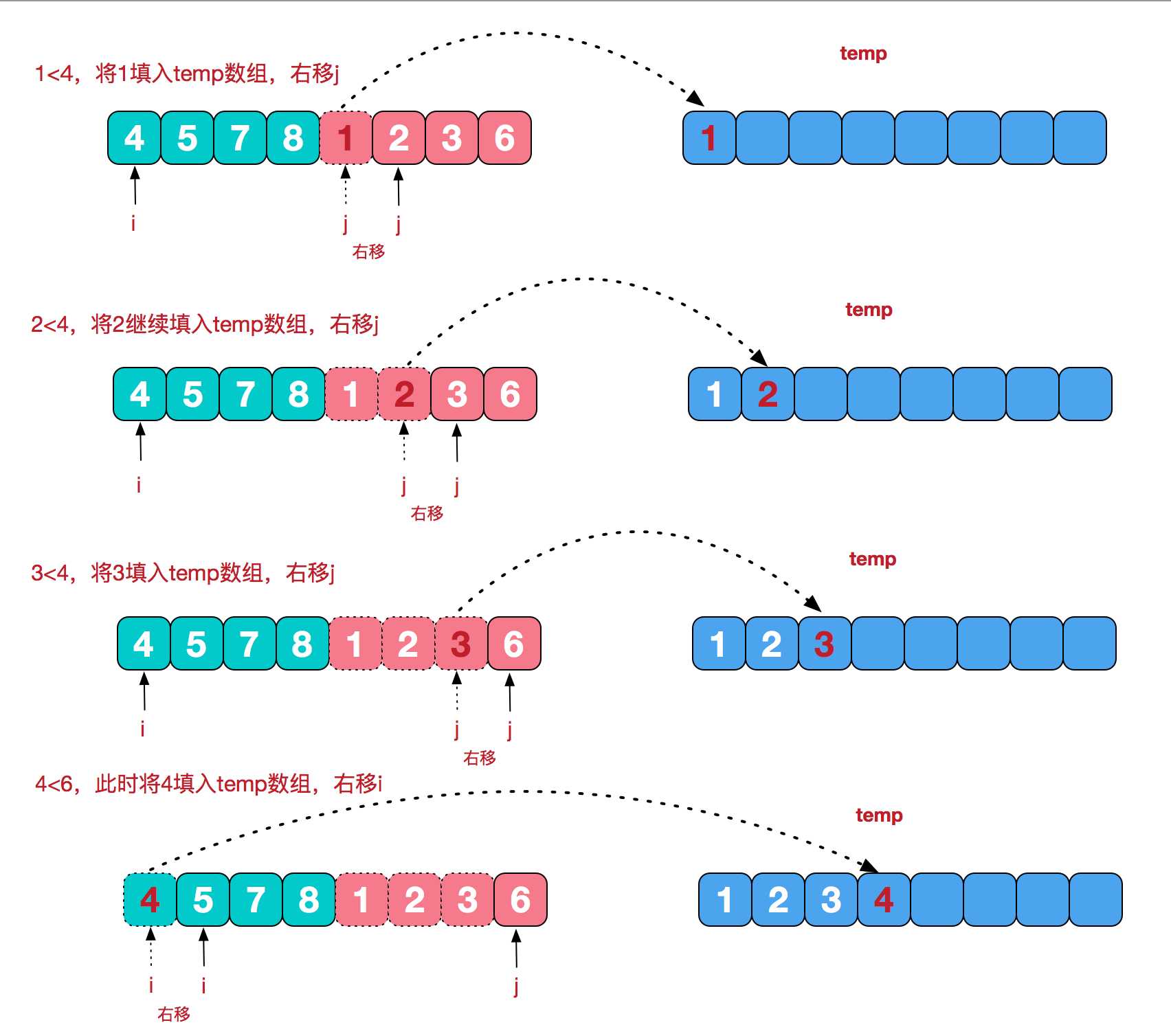
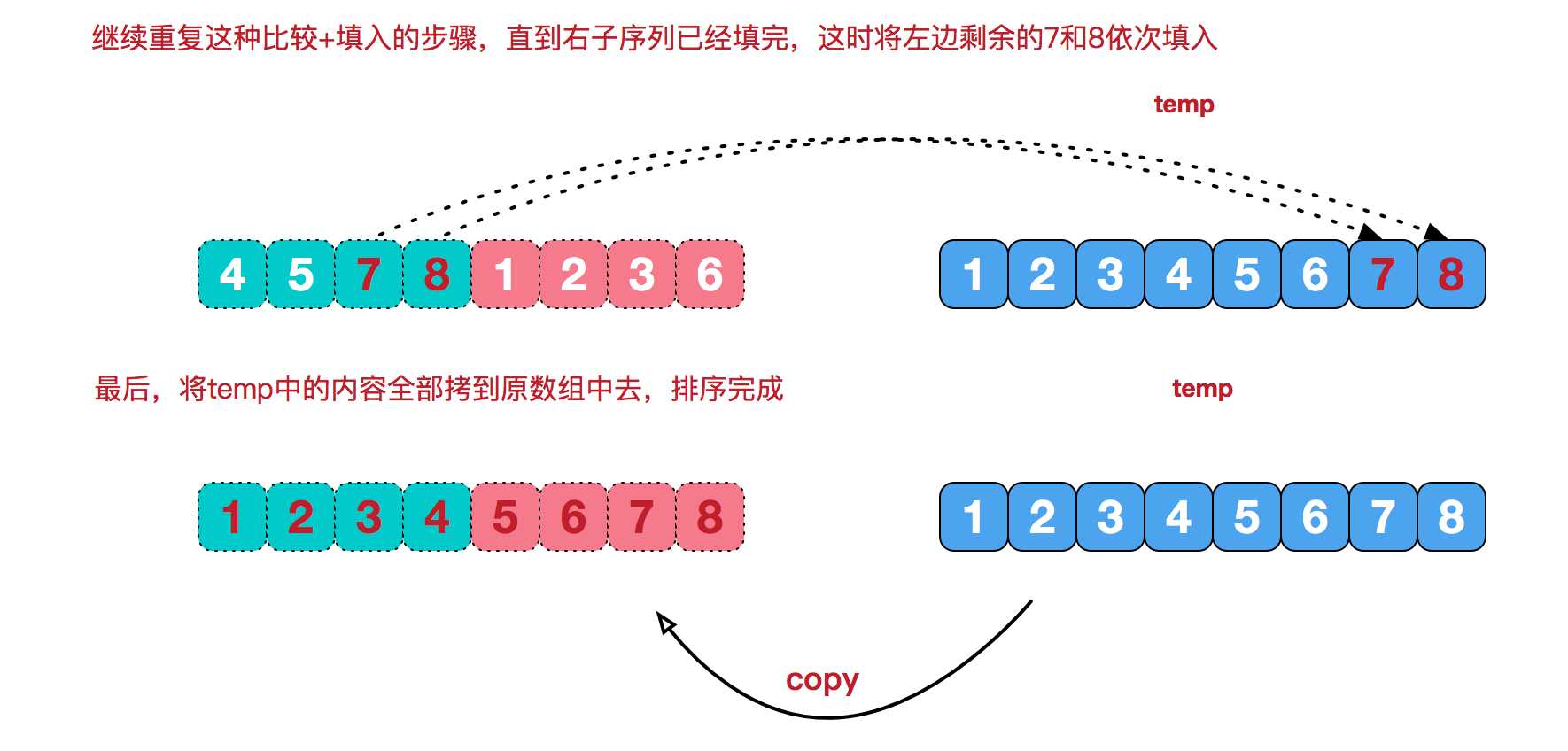
将两个已经有序的子序列合并成一个有序序列,比如下图中的一次合并,要将[4,5,7,8]和[1,2,3,6]两个已经有序的子序列,
合并为最终序列[1,2,3,4,5,6,7,8],步骤为:
【参考资料】
图解排序算法(四)之归并排序
【参考资料】
这里会出现的问题就是,间隔的元素i加上去之后可能超过数组的长度,即不存在这个元素,就会出现如图的错误:
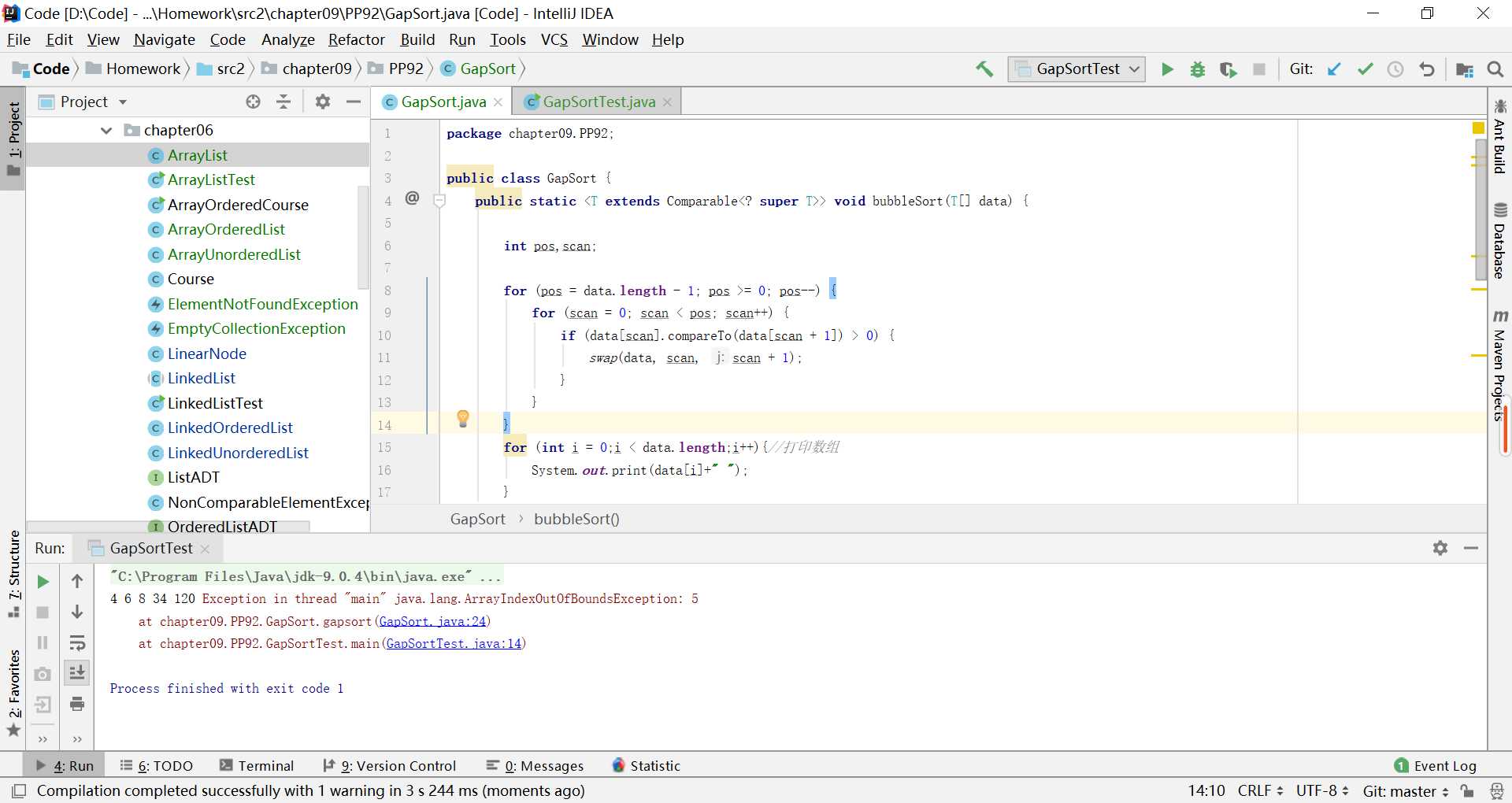
(1)对i进行限制,先把i定义成数组的长度少一,然后在每一轮比较前先对扫描到的索引处+i是否超过数组长度,不超过则进行比较,超过则对i递减1,直到不超过数组长度
(2)也可对加i之后超过数组长度的索引处元素不予比较,紧接着比较下一索引处元素(当然这就更不可能啦。。。),也可以遇到超过数组长度的索引处元素,直接将i减1,进行下一轮循环
思路(1)代码如下:
int i,scan;
for (i = data.length - 1;i>0;i--){
for (scan = 0; scan < data.length - 1; scan++) {
if (scan + i < data.length) {
if (data[scan].compareTo(data[scan + i]) > 0)
swap(data, scan, scan + i);
}
}
}运行结果如图:
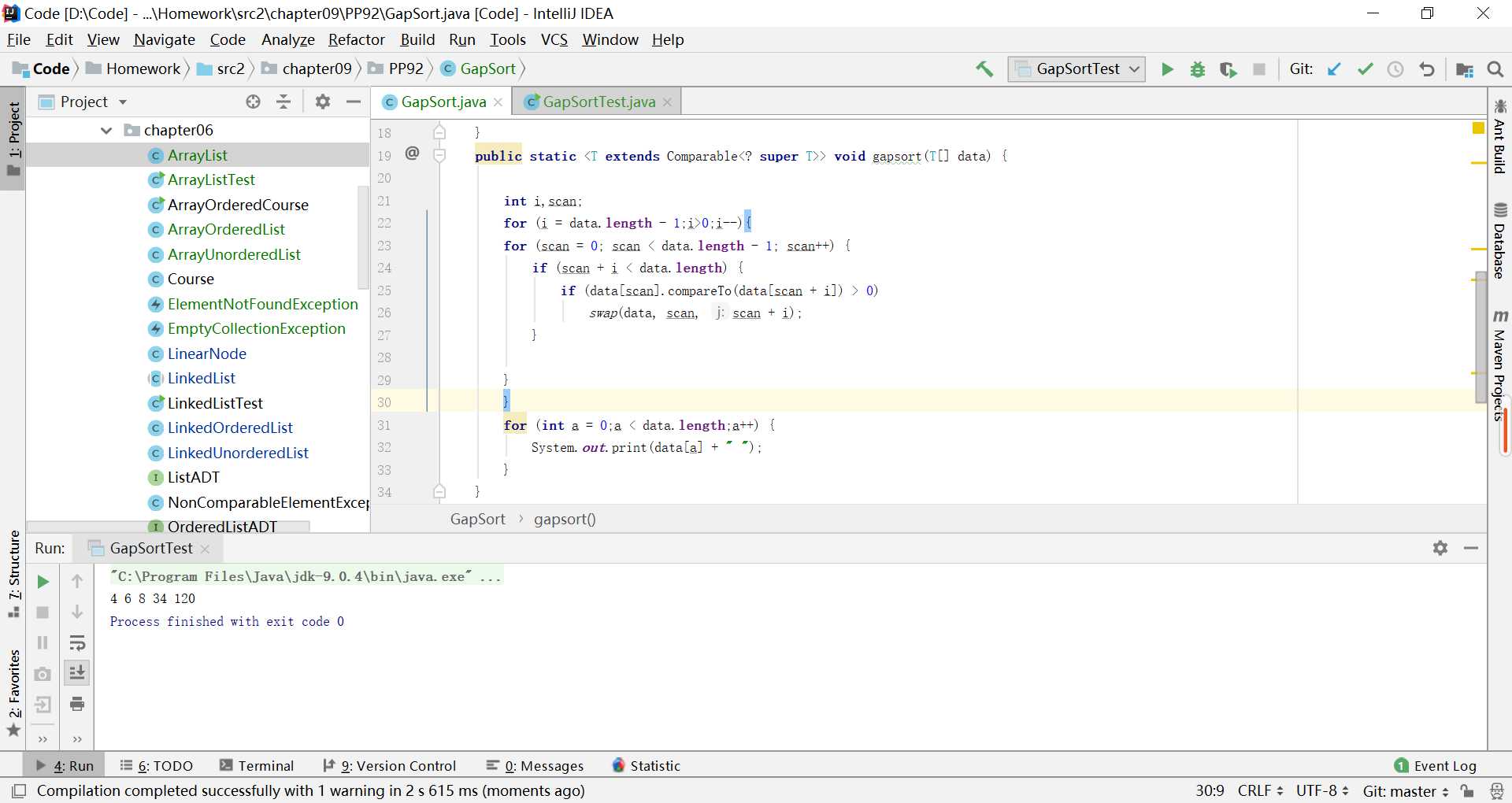
思路(2)的代码如下:
int i,scan;
for (i = data.length - 1;i>0;i--){
for (scan = 0; scan < data.length - 1; scan++) {
if (scan + i >= data.length)
continue;
if (data[scan].compareTo(data[scan + i]) > 0)
swap(data, scan, scan + i);
}
}用一个if语句来判断是否间隔i个元素后过界,然后直接continue跳出循环,进行下一轮循环
运行结果跟上图一致。
【更新】
经过与侯泽洋同学的一番探讨,我发现我看题有点不仔细:
每一轮迭代中,i减少的数量是一个大于1的数
这样的话,在外层循环对i进行修改操作就没问题了;
百度了方法之后很简单,代码如下:
long startTime=System.nanoTime(); //获取开始时间
doSomeThing(); //测试的代码段
long endTime=System.nanoTime(); //获取结束时间
System.out.println("程序运行时间: "+(endTime-startTime)+"ns"); 一开始用的是毫秒计算,但是结果显示都是0ms,于是换了纳秒计算;
有一个很有趣的现象,就是已经排好序的列表排序的时间甚至比没排好序的列表花费的时间还要多,如图:
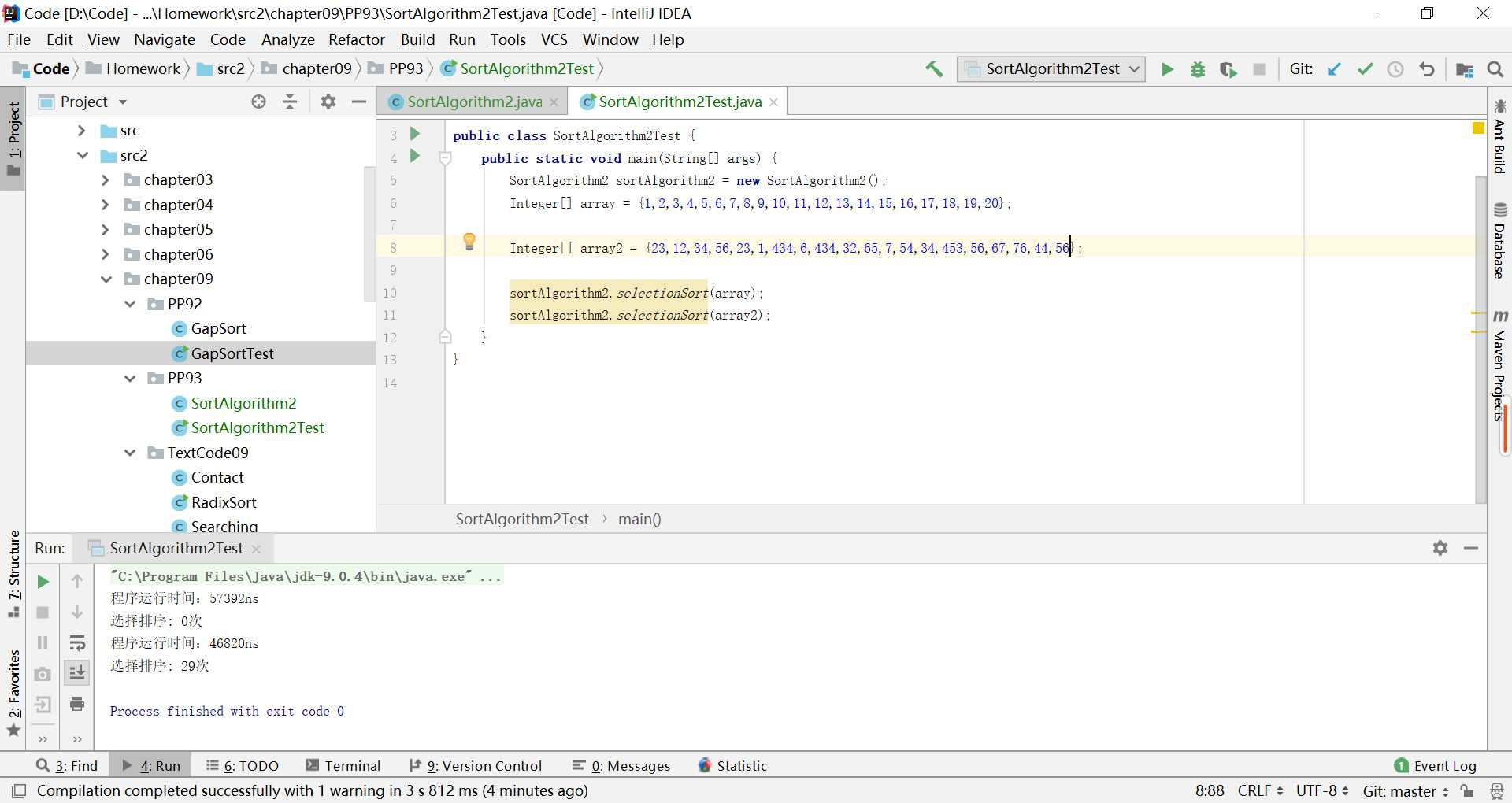
又尝试运行了几十次程序,也有乱序的运行时间长于顺序的情况,但大多数情况还是顺序花费的时间更多
这是跟电脑有关系还是一种巧合,还是其它的什么原因?
暂时并没有百度到相关的解释,等找到了再来补充
还存在一个问题,就是,递归的计数与时间计算好像跟其它排序算法不一样,不能直接一次输出结果,每次调用自己,就会又一次把结果打印一遍,像这样:
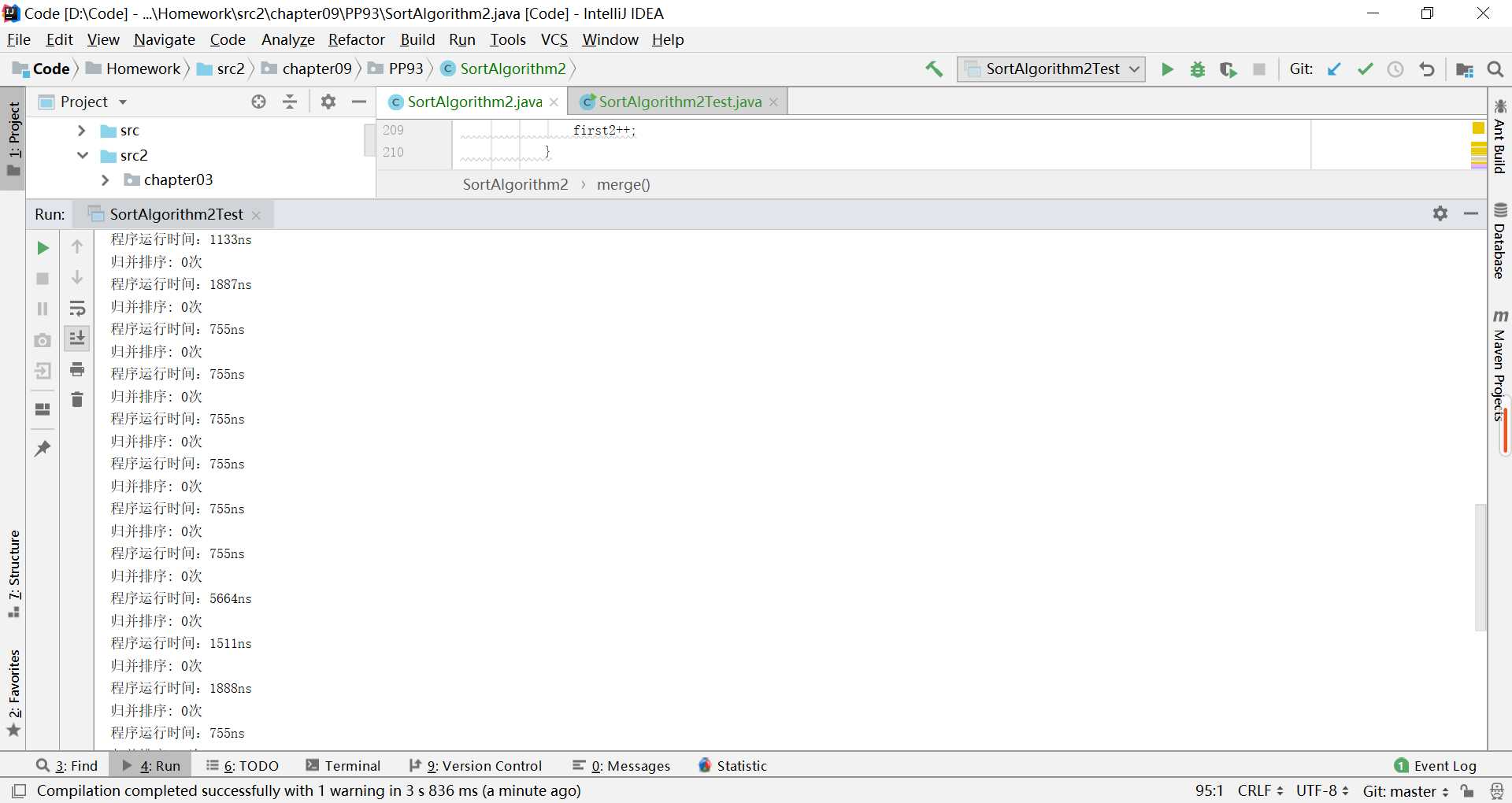
所以不能在递归方法里写计算时间差的方法,调用次数还是可以的,设一个全局变量,每次调用都会自增1,即可(但是输出还得写在测试类里)
那时间的话,可以统计开始调用这个方法到结束时计算机的时间,做差
那问题就是如何获得计算机时间(但时间精确度可能不高)
百度的方法有说可以调用这个方法1000次,然后取千分之一,但是经过前面的体验,方法的每一次调用花费的时间跟电脑的性能和状态有很大关系,因此一次计算不是很准确,1000次求平均的话,可能更有代表性,更合理;
【更新】
有百度到可以获取当前精确时间(毫秒)的方法,这样就简单了,代码如下:
Calendar Cld = Calendar.getInstance();
int YY = Cld.get(Calendar.YEAR) ;//年
int MM = Cld.get(Calendar.MONTH)+1;//月
int DD = Cld.get(Calendar.DATE);//日
int HH = Cld.get(Calendar.HOUR_OF_DAY);//时
int mm = Cld.get(Calendar.MINUTE);//分
int SS = Cld.get(Calendar.SECOND);//秒
int MI = Cld.get(Calendar.MILLISECOND);//毫秒
//由整型而来,因此格式不加0,如 2017/5/5-1:1:32:694
System.out.println(YY + "/" + MM + "/" + DD + "-" + HH + ":" + mm + ":" + SS + ":" + MI);emmm,好像。。。
通过重新写一个方法来调用这个排序的递归方法,然后在这个方法里面再进行时间统计,就可以避免重复打印多次了,也就不用在测试类里统计时间了,更符合题意,运行结果如图:
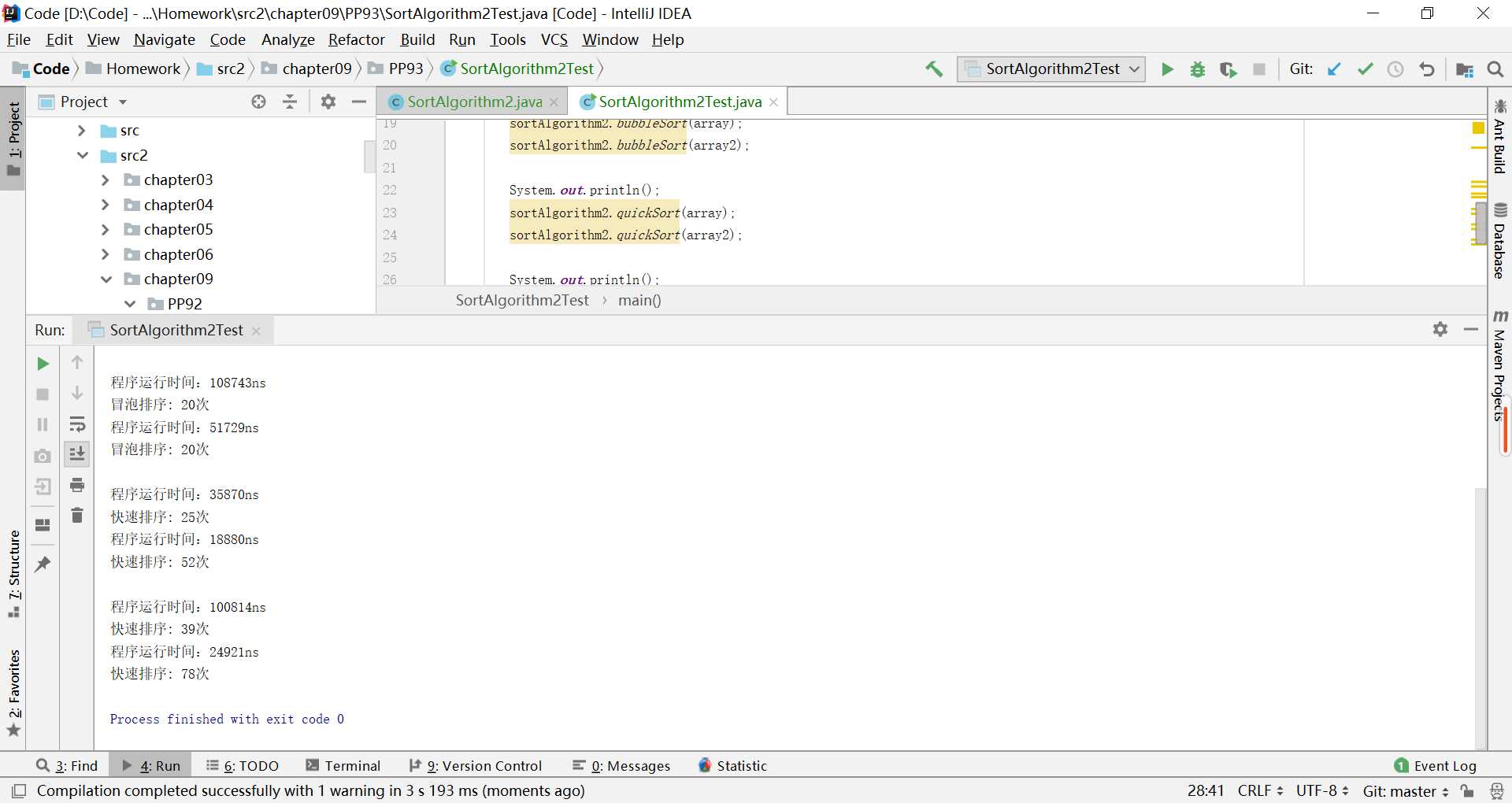
也百度到一些计算递归方法运行的时间,但可能涉及到后面的内容,也没有详细讲,看的不是很明白
【参考资料】
java如何计算程序运行时间
怎么记录递归函数的使用次数
解递归算法的运行时间的三种方法
无
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/1 | 4/4 | |
| 第二周 | 560/560 | 1/2 | 6/10 | |
| 第三周 | 415/975 | 1/3 | 6/16 | |
| 第四周 | 1055/2030 | 1/4 | 14/30 | |
| 第五周 | 1051/3083 | 1/5 | 8/38 |
标签:sys mis mon 行修改 pareto 插入 开始时间 大于 没有
原文地址:https://www.cnblogs.com/zhouyajie/p/9785559.html