标签:class info tab bubuko img 分布式 ddc time 最后一天
文章提出了一种分布式聚类的算法,这是第一个有理论保障的考虑离群点的分布式聚类算法(文章里自己说的).与之前的算法对比有以下四个优点:
1.耗时短O(max{k,logn}*n),
2.传递信息规模小:对抗分区O(klogn+t),随机分区O(klogn+t/s)
3.算法有良好的近似保证,
4.能够有效的检测出离群点.
其中,k聚类中心个数,n数据集大小,t离群点个数,s站点数(分区个数)
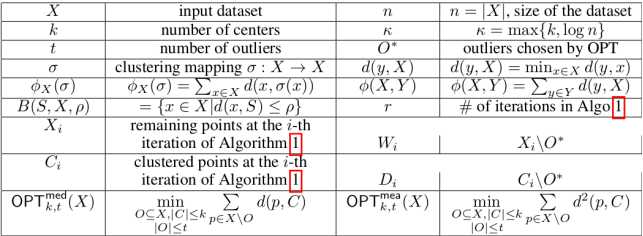
符号说明:
算法总体描述:
文中提出的算法分为两个阶段,第一阶段的算法是在[1]中改进,将[1]中纯净的数据集替换成了带离群点的数据集,算法中增加了离群点的考虑.第二阶段使用的是[2]中提出的k-means—算法.由于第二阶段的算法是现成的,文章重点讲述第一阶段的算法.

算法1输入数据集X,聚类中心个数k,离群点个数t,得到与X(x1,x2,…,xn)相关的权重数据集Q((x1,w1),(x2,w2),…,(xm,wm))...其中m<n
首先,定义三个常数alpha,beta,kappa.当剩下的数据集Xi的个数大于8t的时候,继续下述循环:
6从数据集Xi中随机选取alpha*kappa个元素,构成一个新的数据集Si(选出的元素放回数据集Xi中),
7对于Xi中的每个元素,计算它与Si的距离(Xi中的一个元素与Si中所有元素计算距离,其中最短的即为这个元素与Si的距离)
8选取一个最小半径,使得Xi中距离Si小于半径的元素个数恰好不小于beta*|Xi|,这些元素整合称为集合Ci.其中|Xi|为数据集Xi中的元素个数
9显然,对于集合Ci中的任一元素x,都可以在Si中找到一点y与其最近,我们得到一个最近映射theta(x)=y
10数据集Xi扣除已经找到最近映射的元素集合Ci,剩下的数据集Xi+1考虑新一轮迭代
循环直到不满足循环条件|Xi|>8t,剩下的数据集标记为Xr,Xr中的元素也给一个自映射作为最近映射theta(x)=x
这时,初始数据集X中的每个元素都有最近映射,而Xr和Si中的元素都有被最近映射,w为被最近映射的次数.考虑Xr和Si中的每个元素x和其被映射次数w,则可以得到权重数据集Q.
这么说可能难懂,举个栗子..有X0个人随机分布在空间中固定不动,第一天,一个外星人路过,随机选取了S0个人,给这些选中的孩子每人一个装置,这个装置能将一定范围内的人救上飞船,由于飞船载重有限,确定最小的范围使得救的人最多且不超重.这样,就救了C0个人,剩下X1=X0/C0个人等待救援..第二天第三天第n天,外星人路过做了同样的事情.到最后一天,剩下等待救援的人不足8t个了,外星人给剩下的每个人一个装置.全员获救故事结束.最后我们要得到的Q就是每个获得装置的人和他们的救人数目(这个数目至少为1,至少救了自己).而救人数为1的就是所谓的离群点.

考虑到离群点数目远远大于聚类中心数目的情况,文章对算法1扩充成算法2,先经过算法1,得到了数据集Xr和S,这时Xr的个数远大于S,从C1UC2U…UCr中随机选取|Xr|-|S|个元素构成数据集S’,重新计算C1UC2U…UCr-1中元素到SUS’的最近距离,得到新的最近映射π(x)=y,x∈C1UC2U…UCr-1,y∈SUS’.这样Q中的元素组就从原来的|Xr|+|S|变成|Xr|+|S|+|S’|=2|Xr|.聚类中心的数目和离群点的数目就相同了(实际上S中也存在w=1的元素,离群点数目应该会比聚类中心多一丁点).

算法3是总算法,对于一个超大数据集X,将其随机划分成s个小块,每个小块的数据集为Ai,对于每一个小块运行算法1,其中初始数据集为Ai,聚类中心数目k,离群点数目2t/s,得到其加权数据集Qi.之后整合所有的加权数据集即为Q,运用现成的(k,t)-median算法即可得到聚类结果(文中使用的是k-means--).
理论证明:
首先,文章定义了加权数据集的损失函数: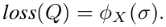
也可以以概率(1-1/n^2)写为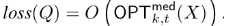
文中证明了损失函数的上界和极高概率的下界,再说明其大概率收敛.文中的证明很详细,就不贴图啰嗦了..
实验说明:
总共在四个数据集上进行实验.1.gauss-δ;2.kddFull;3.kddSp;4.susy-delta
gauss-δ是合成数据集,数据按高斯分布随机采样获得,总共100个聚类中心和1M个点.kddSp是从kddFull中过滤选取的,至于kddFull和susy-delta分别在http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html和https://archive.ics.uci.edu/ml/datasets/SUSY中有详细的解释.
本文的方法称为ball-grow,第一阶段取alpha=2,β=4.5用算法3计算.与rand,k-means++,k-means||进行对比.第二阶段统一采用k-means--.
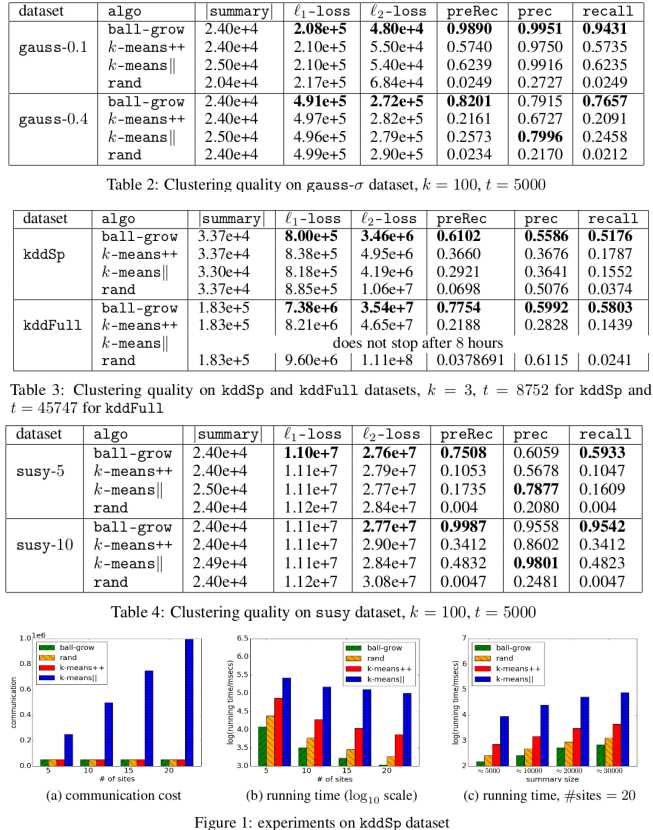
从实验结果可以看出,在给出的数据集上,本文提出的方法传递信息(加权数据集)规模小,损失小,精度\回归高.相较于k-means++,k-mean||和rand这三种方法,ball-grow具有碾压级别的优势.
[1]R. R. Mettu and C. G. Plaxton. Optimal time bounds for approximate clustering. In UAI, pages 344–351, 2002
[2]S. Chawla and A. Gionis. k-means-: A unified approach to clustering and outlier detection. In SDM, pages 189–197, 2013.
A practical algorithm for distributed clustering and outlier detection
标签:class info tab bubuko img 分布式 ddc time 最后一天
原文地址:https://www.cnblogs.com/SuperLab/p/9803022.html