标签:下载 .so www master top 技术 park 安全 tap
1 package sogolog 2 3 import org.apache.spark.rdd.RDD 4 import org.apache.spark.{SparkConf, SparkContext} 5 6 /** 7 * 统计每小时搜索次数 8 */ 9 /* 10 搜狗日志示例 11 访问时间(时:分:秒) 用户ID [查询词] 该URL在返回结果中的排名 用户点击的顺序号 用户点击的URL 12 00:00:00 2982199073774412 [360安全卫士] 8 3 download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html 13 00:00:00 07594220010824798 [哄抢救灾物资] 1 1 news.21cn.com/social/daqian/2008/05/29/4777194_1.shtml 14 00:00:00 5228056822071097 [75810部队] 14 5 www.greatoo.com/greatoo_cn/list.asp?link_id=276&title=%BE%DE%C2%D6%D0%C2%CE%C5 15 00:00:00 6140463203615646 [绳艺] 62 36 www.jd-cd.com/jd_opus/xx/200607/706.html 16 */ 17 object CountByHours { 18 def main(args: Array[String]): Unit = { 19 20 //1、启动spark上下文、读取文件 21 val conf = new SparkConf().setAppName("sougo count by hours").setMaster("local") 22 val sc = new SparkContext(conf) 23 var orgRdd = sc.textFile("C:\\Users\\KING\\Desktop\\SogouQ.reduced\\SogouQ.reduced") 24 println("总行数:"+orgRdd.count()) 25 26 //2、map操作,遍历处理每一行数据 27 var map:RDD[(String,Integer)] = orgRdd.map(line=>{ 28 //拿到小时 29 var h:String = line.substring(0,2) 30 (h,1) 31 }) 32 33 //3、reduce操作,将上面的 map结果按KEY进行合并、叠加 34 var reduce:RDD[(String,Integer)] = map.reduceByKey((x,y)=>{ 35 x+y 36 }) 37 38 //打印出按小时排序后的统计结果 39 reduce.sortByKey().collect().map(println) 40 } 41 }
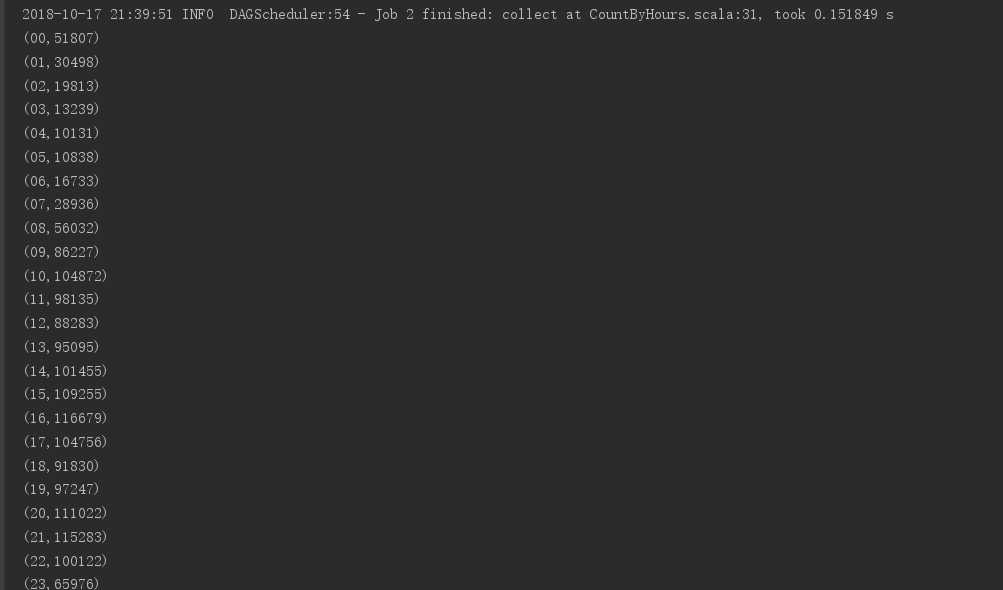
运行结果:
搜狗日志下载地址:http://www.sogou.com/labs/resource/q.php
标签:下载 .so www master top 技术 park 安全 tap
原文地址:https://www.cnblogs.com/wbh1000/p/9807437.html