标签:table 仓库 行数据 管理 img 原因 传统 大数据 技术分享
Hive是一个依赖于分布式存储的查询和管理大型数据集的数据仓库。传统的非大数据行业一般都是基于表进行数据存储和管理的,如果由于业务扩张或者其他原因迁移到HDFS平台上,那么需要将传统的SQL查询语句全部翻译成Map-reduce的程序实现,这个工作量是相当庞大的。好在SQL具有严谨和良好的模板式语法结构,因此Hive就应运而生了,它负责将SQL语句模板化成Map-reduce任务。对上层屏蔽了将SQL任务转化为Map-reduce任务的繁杂性。上层开发者仅仅需要像往常使用SQL语句操作传统关系型数据库一样操作HDFS就可以了。所以Hive更准确讲是一个几月HDFS的数据处理框架,隐藏了底层的复杂性。具体的过程如下:
1-接收来自上层的请求:create table tab_order(id int,name string ,money double) path hdfs://order_log
2-Hive拿到砂锅面的请求之后创建一个元数据表,并且声称相应的Map-reduce程序---编译---打成jar包---运行
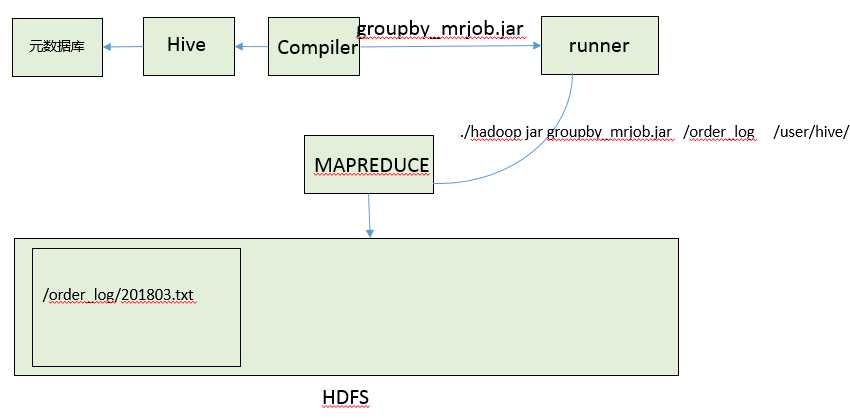
架构如下图所示:

Hive同类的产品也很多,比较有名的有:impala、spark shark、spark sql等
标签:table 仓库 行数据 管理 img 原因 传统 大数据 技术分享
原文地址:https://www.cnblogs.com/maxigang/p/9809359.html