标签:后端 补救措施 集中 cto 分配 服务 nes 两种 处理
在上一篇文章中,我们已经知道了 VSAN 是如何处理容量设备和缓存设备磁盘故障的,那么,如果vsan主机发生故障,会如何呢?我们再来看看下面这幅图: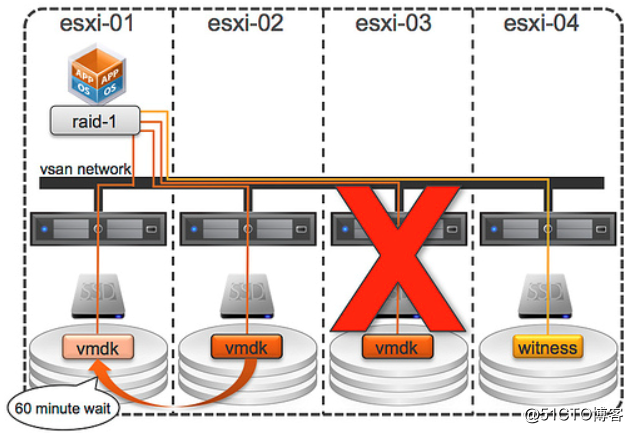
这种情况与“磁盘故障”稍有不同。发生磁盘故障时,VSAN 会注意到所发生的情况,它会注意到磁盘无法恢复,会触发组件重构。但发生主机故障时,VSAN 不会注意到所发生的情况。这种故障状态称为“不存在”。一旦 VSAN 注意到组件(在上述示例中为 VMDK)不存在,计时器就会开始 60 分钟计时。如果组件在 60 分钟内恢复,VSAN就会同步镜像副本。如果组件无法恢复,则 VSAN 就会创建新的镜像副本。请注意,您可以通过更改高级设置“VSAN.ClomRepairDelay”来减少此超时值。
如果原先故障的主机恢复并重新加入了群集,VSAN会检查对象重构状态。如果对象已经在其他一个或多个节点上完成了重构,就不会有其他动作。如果对象重构仍在进行中,原先故障主机的组件仍将被重新同步,以防新的组件会出现问题。当所有对象同步完成,原先主机的组件会被丢弃,而新创建的副本会被启用。不过,如果新组件因为某种原因无法完成同步,那么原先主机上原来的组件会被继续使用。
注:当主机发生了故障,其上运行的所有虚拟机会被VSPHERE HA重启。vsphere ha可能会在群集中任何可用的主机上重启虚拟机,而不管这些主机是否拥有VSAN组件。
补充优化资料:(来自http://blog.51cto.com/roberthu/2049330)
vsan6.2高级参数优化
esxcfg-advcfg -s 1024 /LSOM/heapSize
esxcfg-advcfg -s 180 /VSAN/ClomMaxComponentSizeGB
esxcfg-advcfg -s 512 /LSOM/blPLOGCacheLines 默认值为 128 K,增加至 512 K
esxcfg-advcfg -s 32 /LSOM/blLLOGCacheLines 默认值为 128,增加至 32 K
附录学习:
拥堵表明的含义
拥堵是一种反馈机制,它反映了从 vSAN DOM 客户端层传入 vSAN 磁盘组所服务的级别的入站 IO 请求速率降低。这种入站 IO 请求速率降低的行为是由 IO 延迟引起的,而底层的瓶颈会导致发生 IO 延迟。因此,一个有效的方法是,将滞后时间从底层转移到输入流量,而无需更改系统的总吞吐量。这可避免在 vSAN LSOM 层中出现不必要的排队以及尾丢队列,于是避免了在处理最终可能丢弃的 IO 请求时浪费大量的 CPU 周期。因此,无论何种类型的拥堵,临时和较小的拥堵值通常没问题,但对系统性能无益。不过,持续和较大的拥堵值可能会导致滞后时间延长和吞吐量降低的程度超出预期,因此应进行关注并解决以提高基准性能。
拥堵的报告方式
vSAN 衡量并以介于 0 至 255 之间的标量值报告拥堵。引入的 IO 延迟会随拥堵值的增加呈指数增长。
处理拥堵的可行方法
检查拥堵是否持续且居高不下 (> 50)。许多情况下,高拥堵值是系统配置错误或系统性能不佳造成的。如果一直呈现高拥堵值,请检查以下项:
1.IO 控制器和设备中支持的最大队列深度。支持的最大队列深度低于 100 可能会导致问题。请检查控制器是否已经过认证并列在 vSAN HCL 列表中。
2.固件或设备驱动程序软件的不正确版本。请参考 VMware HCL,了解 vSAN 兼容的软件。
3.不正确的大小设置。缓存层磁盘和内存的大小设置不正确可能会导致拥堵值较高。
如果问题不是上述任何状况,必须进行调试,确定是否可以更好地调整基准,以减少拥堵。您必须注意,是:
4.所有磁盘组都出现拥堵,还是
5.一个或两个磁盘组的拥堵值异常高于其他磁盘组。
对于情况 (1),很有可能 vSAN 群集后端无法处理 IO 工作负载。如果可能,可以通过以下方法调整基准:
6.关闭某些虚拟机或
7.减少每个虚拟机中的未完成 IO/线程数,或者
8.对于写入工作负载,减小工作集的大小。
对于情况 (2),即,一个磁盘组上的拥堵远远高于系统中的其他磁盘组,这表明磁盘组间的写入 IO 活动不平衡。如果持续发生这种情况,请尝试增加用于创建虚拟机磁盘的 vSAN 存储策略中的磁盘带数。
报告的常见拥堵类型以及解决方法
下面列出了拥堵类型和每种类型的补救措施:
9.SSD 拥堵:特定磁盘组的写入 IO 的活动工作集显著大于该磁盘组缓存层的大小时,通常会引发 SSD 拥堵。在混合和全闪存 vSAN 群集中,数据首先写入到写入缓存(也称为写入缓冲区)。一个称为降级转储的进程会将数据从写入缓冲区移至容量磁盘。写入缓存承受较高的写入速率,从而确保写入性能不受容量磁盘的限制。不过,如果基准以非常快的速率填充写入缓存,降级转储进程可能跟不上到达 IO 速率。在这种情况下,会引发 SSD 拥堵,以指示 vSAN DOM 客户端层将 IO 减速到 vSAN 磁盘组可以处理的速率。
补救措施:要避免 SSD 拥堵,请调整基准所用的虚拟机磁盘的大小。为达到最佳效果,我们建议虚拟机磁盘(活动工作集)的大小不超过所有磁盘组写入缓存累计大小的 40%。请注意,对于混合 vSAN 群集,写入缓存的大小为缓存层磁盘大小的 30%。在全闪存群集中,写入缓存的大小是缓存层磁盘的大小,但不应超过 600 GB。
2.日志拥堵:vSAN LSOM 日志(存储未降级转储的 IO 操作的元数据)消耗写入缓存中的大量空间时,通常会引发日志拥堵。
通常情况下,小工作集上的大量小规模写入会导致出现大量 vSAN LSOM 日志条目,于是会导致出现这种类型的拥堵。此外,如果基准不发出 4K 对齐 IO,则 vSAN 堆栈上的 IO 数将增加,从而引发 4K 对齐。IO 数增加可能会导致日志拥堵。
补救措施:检查基准是否与 4K 边界上的 IO 请求一致。如果不一致,请检查基准是否使用一个非常小的工作集(访问虚拟机磁盘的总大小低于缓存层大小的 10% 时,则认为工作集较小。请参见上文有关如何计算缓存层大小的内容)。如果是,请将工作集增加到缓存层大小的 40%。如果以上两个条件都不成立,将需要通过以下两种方法减少写入流量:减少基准发出的未完成 IO 数或减少基准创建的虚拟机数量。
3.组件拥堵:这种拥堵表明,由于某些组件的 IO 请求排入队列,致使这些组件存在大量的未完成提交操作。这可能会导致延长滞后时间。通常情况下,几个虚拟机磁盘的大量写入会导致出现这种拥堵。
补救措施:增加基准所用的虚拟机磁盘数。确保基准不向少量虚拟机磁盘发出 IO。
4.内存和 Slab 拥堵:内存和 slab 拥堵通常意味着 vSAN LSOM 层所用的堆内存空间或 slab 空间不足,无法维持其内部数据结构。vSAN 会为内部操作置备一定量的系统内存。但是,如果基准积极地发出 IO,而没有任何限制,则可能会导致 vSAN 用光所有为其分配的内存空间。
补救措施:减小基准的工作集。或者,在体验基准时提高以下设置以增加为 vSAN LSOM 层预留的内存量。请注意,这些设置是针对每个磁盘组的。此外,我们不建议在生产群集上使用这些设置。可以通过 esxcli 更改这些设置(请参见 知识库文章 1038578),如下所示:
/LSOM/blPLOGCacheLines,默认值为 128 K,增加至 512 K
/LSOM/blPLOGLsnCacheLines,默认值为 4 K,调整为 32 K
/LSOM/blLLOGCacheLines,默认值为 128,增加至 32 K
标签:后端 补救措施 集中 cto 分配 服务 nes 两种 处理
原文地址:http://blog.51cto.com/xjsunjie/2304347