标签:style blog http color io os 使用 ar java
对于xml的解析和生成,我们在实际应用中用的比较多的是JDOM和DOM4J,下面通过例子来分析两者的区别(在这里我就不详细讲解怎么具体解析xml,如果对于xml的解析看不懂的可以先去看下我之前关于dom跟sax解析xml的随笔http://www.cnblogs.com/zhi-hao/p/3985720.html,其实理解了解析xml的原理,要想学习jdom跟dom4j就比较简单了,jdom跟dom4j只是基于底层api的更高级的封装,而dom和sax是解析xml的底层接口),我们在使用jdom和dom4j时要导入相应的包,这些包可以到jdom和dom4j的官网去下载。
首先通过jdom来生成xml
1 package xmlTest; 2 /** 3 * @author CIACs 4 */ 5 import java.io.FileOutputStream; 6 7 import org.jdom.Document; 8 import org.jdom.Element; 9 import org.jdom.output.Format; 10 import org.jdom.output.XMLOutputter; 11 12 public class Jdom { 13 14 public static void main(String[] args) throws Exception{ 15 Document doc = new Document(); 16 Element root = new Element("root"); 17 doc.addContent(root); 18 19 Element name = new Element("name"); 20 root.addContent(name); 21 root.setAttribute("author","CIACs").setAttribute("url", "http://www.cnblogs.com/zhi-hao/"); 22 name.addContent("CIACs"); 23 24 XMLOutputter out = new XMLOutputter(); 25 Format format = Format.getPrettyFormat(); 26 format.setIndent(" "); 27 out.setFormat(format); 28 out.output(doc,new FileOutputStream("jdom.xml")); 29 30 } 31 32 }
生成的xml
1 <?xml version="1.0" encoding="UTF-8"?> 2 <root author="CIACs" url="http://www.cnblogs.com/zhi-hao/"> 3 <name>CIACs</name> 4 </root>
这里生成的xml比较简单,这是为了容易理解,简单的理解了,复杂的其实也就会了。
接下来通过jdom对xml进行解析
1 package xmlTest; 2 /** 3 * @author CIACs 4 */ 5 import java.io.File; 6 import java.io.FileOutputStream; 7 import java.util.List; 8 9 import org.jdom.Attribute; 10 import org.jdom.Document; 11 import org.jdom.Element; 12 import org.jdom.input.SAXBuilder; 13 import org.jdom.output.XMLOutputter; 14 15 public class Jdom2 { 16 17 public static void main(String[] args) throws Exception { 18 //通过SAXBuilder解析xml 19 SAXBuilder builder = new SAXBuilder(); 20 21 Document doc = builder.build(new File("jdom.xml")); 22 23 Element root = doc.getRootElement(); 24 25 System.out.println(root.getName()); 26 27 String name = root.getChild("name").getText(); 28 29 System.out.println("name: "+name); 30 31 List attrs = root.getAttributes(); 32 33 for(int i = 0; i < attrs.size();i++) 34 { 35 String attrName; 36 String attrValue; 37 Attribute attr = (Attribute)attrs.get(i); 38 attrName = attr.getName(); 39 attrValue = attr.getValue(); 40 System.out.println(attrName+":"+attrValue); 41 42 } 43 //删除属性url,并保存到jdom2.xml 44 root.removeAttribute("url"); 45 46 XMLOutputter out = new XMLOutputter(); 47 out.output(doc, new FileOutputStream("jdom2.xml")); 48 49 50 } 51 }
控制台窗口输出的结果:
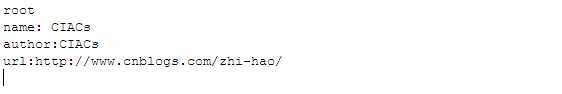
写入jdom2.xml的内容
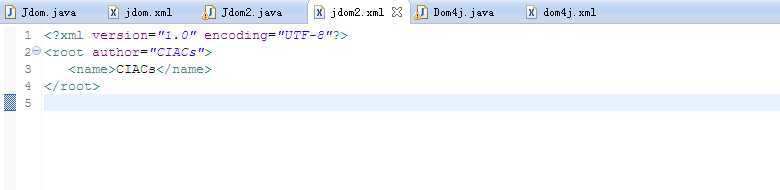
下面是用dom4j来操作xml

1 package xmlTest; 2 /** 3 * @author CIACs 4 */ 5 import java.io.File; 6 import java.io.FileOutputStream; 7 import java.util.List; 8 9 import javax.xml.parsers.DocumentBuilder; 10 import javax.xml.parsers.DocumentBuilderFactory; 11 12 import org.dom4j.Attribute; 13 import org.dom4j.Document; 14 import org.dom4j.DocumentFactory; 15 import org.dom4j.DocumentHelper; 16 import org.dom4j.Element; 17 import org.dom4j.io.DOMReader; 18 import org.dom4j.io.OutputFormat; 19 import org.dom4j.io.SAXReader; 20 import org.dom4j.io.XMLWriter; 21 22 public class Dom4j { 23 public static void main(String[] args) throws Exception { 24 //创建文档跟节点 25 Document doc = DocumentFactory.getInstance().createDocument(); 26 Element root = DocumentHelper.createElement("root"); 27 doc.setRootElement(root); 28 29 Element name = DocumentHelper.createElement("name"); 30 name.setText("CIACs"); 31 name.addAttribute("age", "22"); 32 root.add(name); 33 root.addElement("address").addAttribute("province", "guangdong").addElement("country").setText("guangzhou"); 34 35 //生成的xml输出到命令行窗口 36 OutputFormat format = new OutputFormat(" ",true); 37 XMLWriter writer = new XMLWriter(format); 38 writer.write(doc); 39 40 XMLWriter writer2 = new XMLWriter(new FileOutputStream(new File("dom4j.xml")),format); 41 //生成的xml写到内存中 42 writer2.write(doc); 43 44 45 System.out.println("-----------通过SAXReader来解析xml文档-----------"); 46 SAXReader reader = new SAXReader(); 47 Document doc2 = reader.read(new File("dom4j.xml")); 48 Element root2 = doc2.getRootElement(); 49 50 parse(root2); 51 52 System.out.println("---------通过DOMReader来解析xml文档-------------"); 53 54 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); 55 DocumentBuilder db = dbf.newDocumentBuilder(); 56 //当一个程序中引用同名不同包的两个Document,其中一个必须要加包名加以区别 57 org.w3c.dom.Document doc3 = db.parse(new File("dom4j.xml")); 58 DOMReader domReader = new DOMReader(); 59 //将JAXP的document转换为dom4j的document 60 Document doc4 = domReader.read(doc3); 61 //获得根元素的名称 62 String rootName = doc4.getRootElement().getName(); 63 System.out.println(rootName); 64 65 } 66 67 public static void parse(Element element) 68 { 69 List<Attribute> list = element.attributes(); 70 if(!list.isEmpty()) 71 { 72 for(Attribute attr:list) 73 { 74 System.out.println("属性:"+attr.getName()+"="+attr.getText()); 75 } 76 } 77 List<Element> list2 = element.elements(); 78 for(int i=0;i<list2.size();i++) 79 { 80 81 82 83 if(list2.get(i).elements().size()>=1) 84 { 85 System.out.println(list2.get(i).getName()); 86 parse(list2.get(i)); 87 } 88 else 89 { 90 System.out.println(list2.get(i).getName()+": "+list2.get(i).getText()); 91 } 92 93 94 List<Attribute> list3 = list2.get(i).attributes(); 95 if(!list3.isEmpty()) 96 { 97 for(Attribute attr:list3) 98 { 99 System.out.println("属性:"+attr.getName()+"="+attr.getText()); 100 } 101 } 102 103 104 } 105 106 } 107 108 }
1 package xmlTest; 2 /** 3 * @author CIACs 4 */ 5 import java.io.File; 6 import java.io.FileOutputStream; 7 import java.util.List; 8 9 import javax.xml.parsers.DocumentBuilder; 10 import javax.xml.parsers.DocumentBuilderFactory; 11 12 import org.dom4j.Attribute; 13 import org.dom4j.Document; 14 import org.dom4j.DocumentFactory; 15 import org.dom4j.DocumentHelper; 16 import org.dom4j.Element; 17 import org.dom4j.io.DOMReader; 18 import org.dom4j.io.OutputFormat; 19 import org.dom4j.io.SAXReader; 20 import org.dom4j.io.XMLWriter; 21 22 public class Dom4j { 23 public static void main(String[] args) throws Exception { 24 //创建文档跟节点 25 Document doc = DocumentFactory.getInstance().createDocument(); 26 Element root = DocumentHelper.createElement("root"); 27 doc.setRootElement(root); 28 29 Element name = DocumentHelper.createElement("name"); 30 name.setText("CIACs"); 31 name.addAttribute("age", "22"); 32 root.add(name); 33 root.addElement("address").addAttribute("province", "guangdong").addElement("country").setText("guangzhou"); 34 35 //生成的xml输出到命令行窗口 36 OutputFormat format = new OutputFormat(" ",true); 37 XMLWriter writer = new XMLWriter(format); 38 writer.write(doc); 39 40 XMLWriter writer2 = new XMLWriter(new FileOutputStream(new File("dom4j.xml")),format); 41 //生成的xml写到内存中 42 writer2.write(doc); 43 44 System.out.println("-----------通过SAXReader来解析xml文档-----------"); 45 SAXReader reader = new SAXReader(); 46 Document doc2 = reader.read(new File("dom4j.xml")); 47 Element root2 = doc2.getRootElement(); 48 49 parse(root2); 50 51 System.out.println("---------通过DOMReader来解析xml文档-------------"); 52 53 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); 54 DocumentBuilder db = dbf.newDocumentBuilder(); 55 //当一个程序中引用同名不同包的两个Document,其中一个必须要加包名加以区别 56 org.w3c.dom.Document doc3 = db.parse(new File("dom4j.xml")); 57 DOMReader domReader = new DOMReader(); 58 //将JAXP的document转换为dom4j的document 59 Document doc4 = domReader.read(doc3); 60 //获得根元素的名称 61 String rootName = doc4.getRootElement().getName(); 62 System.out.println(rootName); 63 64 } 65 66 public static void parse(Element element) 67 { 68 List<Attribute> list = element.attributes(); 69 if(!list.isEmpty()) 70 { 71 for(Attribute attr:list) 72 { 73 System.out.println("属性:"+attr.getName()+"="+attr.getText()); 74 } 75 } 76 List<Element> list2 = element.elements(); 77 for(int i=0;i<list2.size();i++) 78 { 79 80 if(list2.get(i).elements().size()>=1) 81 { 82 System.out.println(list2.get(i).getName()); 83 parse(list2.get(i)); 84 } 85 else 86 { 87 System.out.println(list2.get(i).getName()+": "+list2.get(i).getText()); 88 } 89 90 List<Attribute> list3 = list2.get(i).attributes(); 91 if(!list3.isEmpty()) 92 { 93 for(Attribute attr:list3) 94 { 95 System.out.println("属性:"+attr.getName()+"="+attr.getText()); 96 } 97 } 98 } 99 } 100 }
输出结果
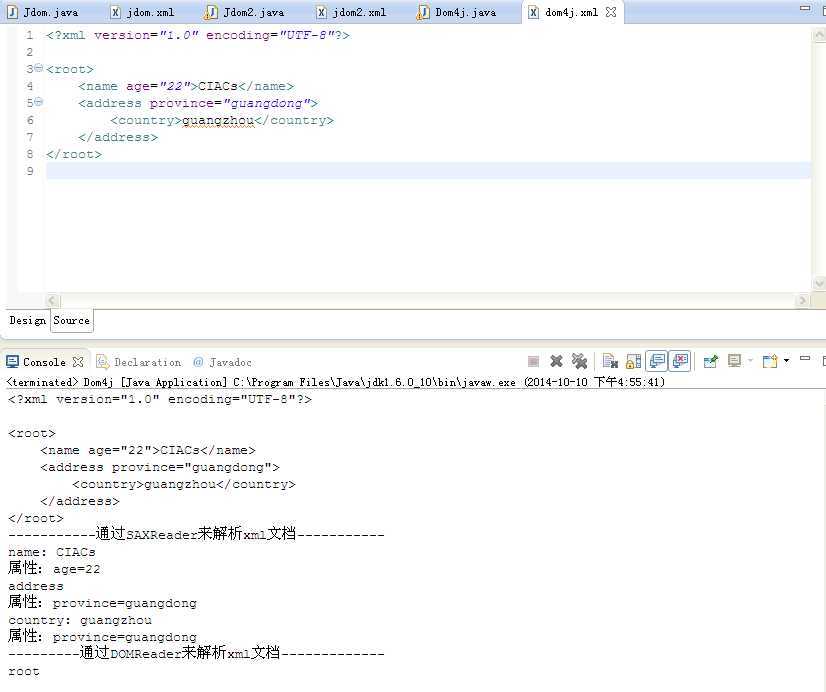
1、JDOM
JDOM的目的是成为 Java 特定文档模型,它简化与 XML 的交互并且比使用 DOM 实现更快。由于是第一个 Java
特定模型,JDOM 一直得到大力推广和促进。正在考虑通过“Java 规范请求 JSR-102”将它最终用作“Java 标准扩展”。从 2000
年初就已经开始了 JDOM 开发。
JDOM 与 DOM 主要有两方面不同。首先,JDOM 仅使用具体类而不使用接口。这在某些方面简化了 API,但是也限制了灵活性。第二,API 大量使用了 Collections 类,简化了那些已经熟悉这些类的 Java 开发者的使用。
JDOM 文档声明其目的是“使用 20%(或更少)的精力解决 80%(或更多)Java/XML 问题”(根据学习曲线假定为
20%)。JDOM 对于大多数 Java/XML 应用程序来说当然是有用的,并且大多数开发者发现 API 比 DOM 容易理解得多。JDOM
还包括对程序行为的相当广泛检查以防止用户做任何在 XML 中无意义的事。然而,它仍需要您充分理解 XML
以便做一些超出基本的工作(或者甚至理解某些情况下的错误)。这也许是比学习 DOM 或 JDOM 接口都更有意义的工作。
JDOM 自身不包含解析器。它通常使用 SAX2 解析器来解析和验证输入 XML 文档(尽管它还可以将以前构造的 DOM
表示作为输入)。它包含一些转换器以将 JDOM 表示输出成 SAX2 事件流、DOM 模型或 XML 文本文档。JDOM 是在 Apache
许可证变体下发布的开放源码。
2、DOM4J
虽然 DOM4J 代表了完全独立的开发结果,但最初,它是 JDOM 的一种智能分支。它合并了许多超出基本 XML
文档表示的功能,包括集成的 XPath 支持、XML Schema
支持以及用于大文档或流化文档的基于事件的处理。它还提供了构建文档表示的选项,它通过 DOM4J API 和标准 DOM 接口具有并行访问功能。从
2000 下半年开始,它就一直处于开发之中。
为支持所有这些功能,DOM4J 使用接口和抽象基本类方法。DOM4J 大量使用了 API 中的 Collections
类,但是在许多情况下,它还提供一些替代方法以允许更好的性能或更直接的编码方法。直接好处是,虽然 DOM4J 付出了更复杂的 API
的代价,但是它提供了比 JDOM 大得多的灵活性。
在添加灵活性、XPath 集成和对大文档处理的目标时,DOM4J 的目标与 JDOM 是一样的:针对 Java
开发者的易用性和直观操作。它还致力于成为比 JDOM 更完整的解决方案,实现在本质上处理所有 Java/XML 问题的目标。在完成该目标时,它比
JDOM 更少强调防止不正确的应用程序行为。
DOM4J 是一个非常非常优秀的Java XML
API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件。如今你可以看到越来越多的 Java 软件都在使用 DOM4J
来读写 XML,特别值得一提的是连 Sun 的 JAXM 也在用 DOM4J。
3、总述
JDOM 在性能测试时表现不佳,在测试 10M 文档时内存溢出。在小文档情况下还值得考虑使用 JDOM。
总的来说DOM4J是最好的,目前许多开源项目中也大量采用 DOM4J,例如大名鼎鼎的 Hibernate 也用 DOM4J 来读取 XML 配置文件。如果不考虑可移植性,那就采用DOM4J吧!
标签:style blog http color io os 使用 ar java
原文地址:http://www.cnblogs.com/zhi-hao/p/4016363.html
