标签:训练 转换 nbsp 出现 不同 上下文 目的 cti 解决
词向量:
无论是一段话或是一篇文章,词都是最基本的组成单位。
如何让计算机利用这些词?
重点是如何把一个词转换成一个想向量

如果在一个二维空间中,had,has,have意思相同,所以要离的比较近。
need,help也是离的比较近
要表现出相同,相关。
比如说下面的例子:
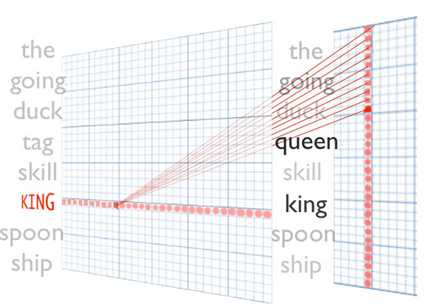
哪些词离青蛙frog比较近?同义词

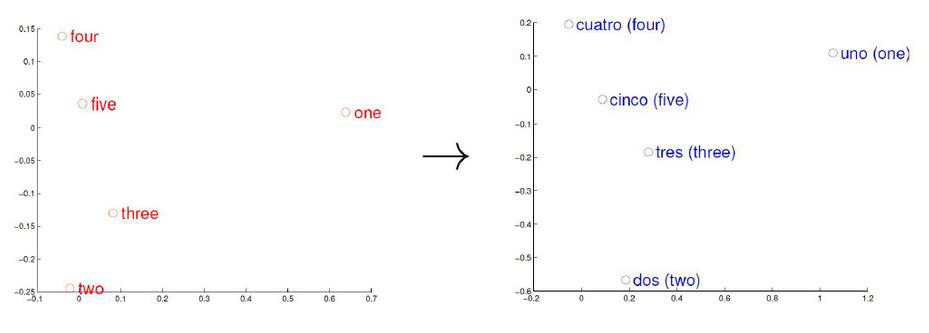
对于两种不同语言,建模之后语言空间也是很接近的,
所以可以说构建出来的词向量跟语言类别无关,只是根据语义环(上下文的逻辑)境来建模。
神经网络模型:
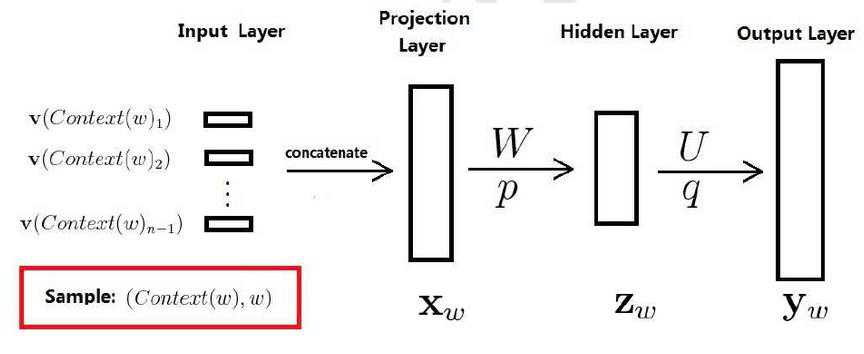
将输入词向量进行首尾相接(projection Layer 投影层),在传给神经网络进行参数优化,
这里的输入向量也需要被优化。
训练样本: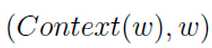 包括前n-1个词分别的向量,假定每个词向量大小m
包括前n-1个词分别的向量,假定每个词向量大小m
投影层:(n-1)*m 首尾拼接起来的大向量
输出: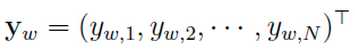
表示上下文为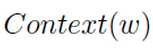 时,下一个词恰好为词典中第i个词的概率
时,下一个词恰好为词典中第i个词的概率
归一化: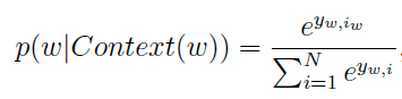
目的就是要求出每一个词的词向量是什么。
神经网络的优势:
S1 = ‘’我今天去网咖’’ 出现了1000次
S2 = ‘’我今天去网吧’’ 出现了10次
对于N-gram模型:P(S1) >> P(S2)
而神经网络模型计算的P(S1) ≈ P(S2)

神经网络看来,类似的句子和词都是一个东西
只要语料库中出现其中一个,其他句子的概率也会相应的增大
Hierarchical Softmax:
分层的softmax
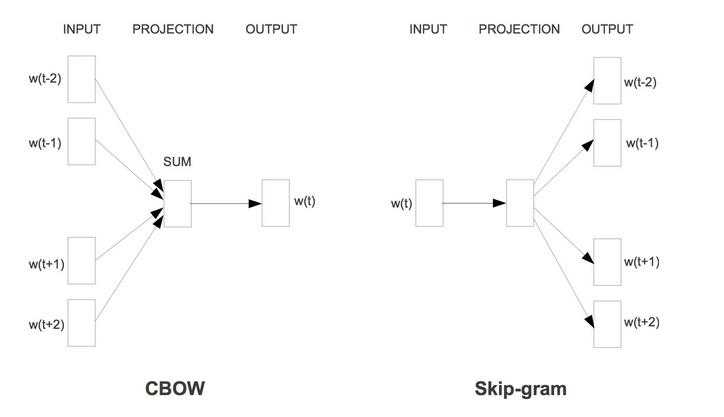
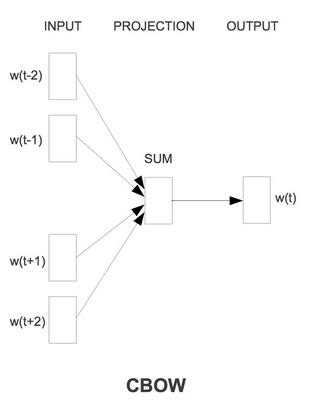
CBOW:根据上下文得到当前词
skip-gram:根据当前词得到上下文。
CBOW:
CBOW 是Continuous Bag-of-Words Model 的缩写,是一种根据上下文的词语预测当前词语的出现概率的模型
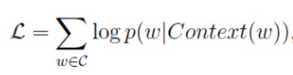
如果出现上下文,词w我们希望它出现的概率应该是越大越好的
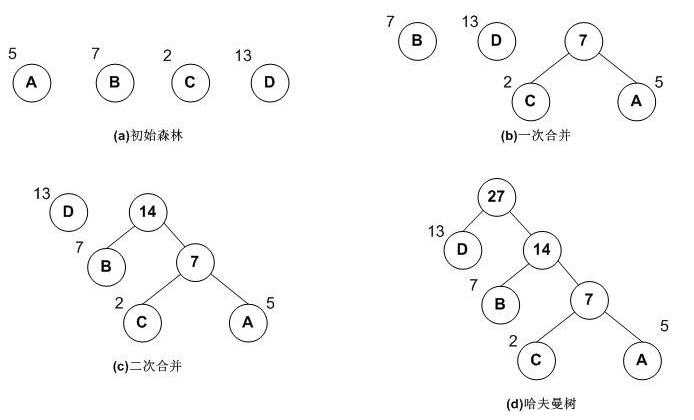
我们需要先了解一个叫做哈夫曼树的东西
哈夫曼树:
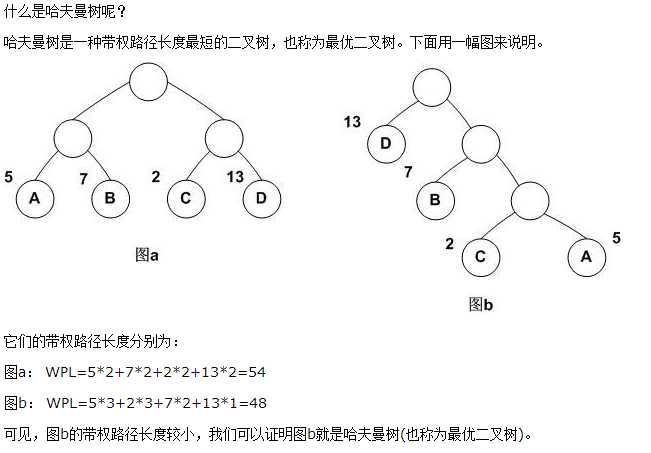
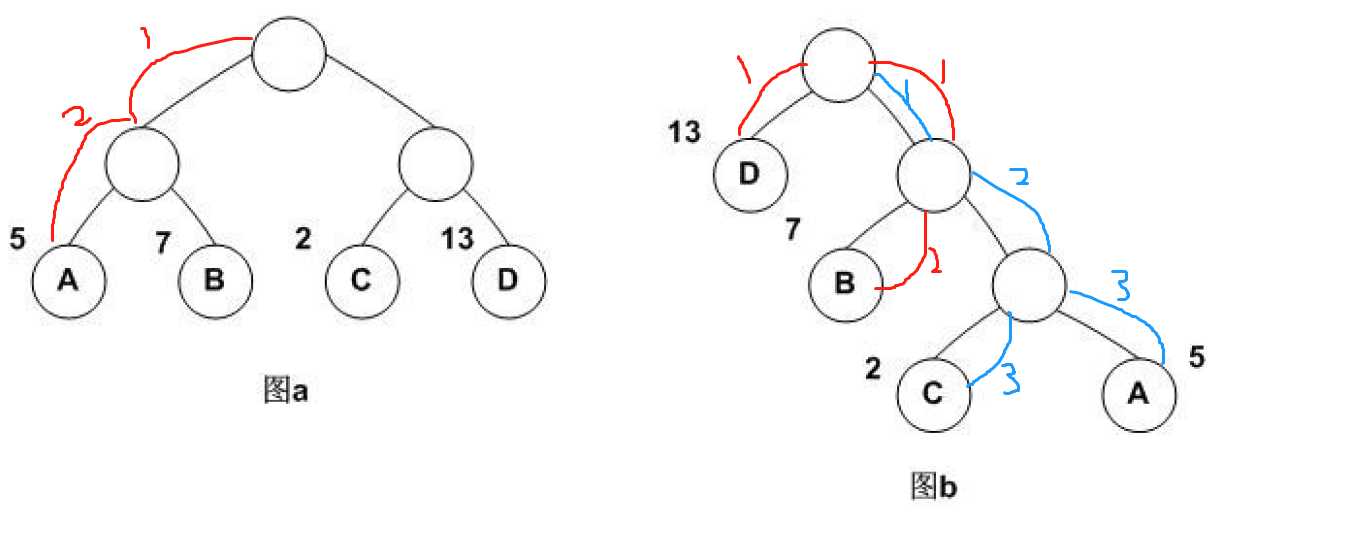
相当于权值乘以步长,把权值最大的放在最前面,在word2vec中,我们可以把词频(概率)当做这个权值。
这个二分类可以做softmax分层的判断,判断是不是后面要出现的词,然后把重要的放在第1位,第2位。。。。。。
哈夫曼树的构造流程
利用哈夫曼树编码:
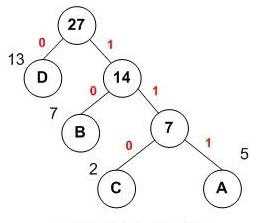
A:111
C:110
B:10
D:0
在哈夫曼树中,如何决定走向呢?(决定左右)
用以前的知识:逻辑回归
sigmoid函数
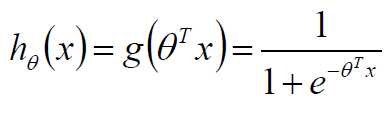
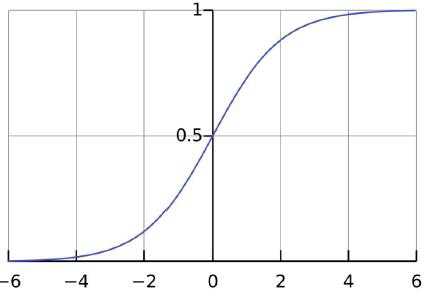
任意数值输入,得到0~1的输出,那么就可以根据这个输出分类往左还是往右
接着说前文的CBOW
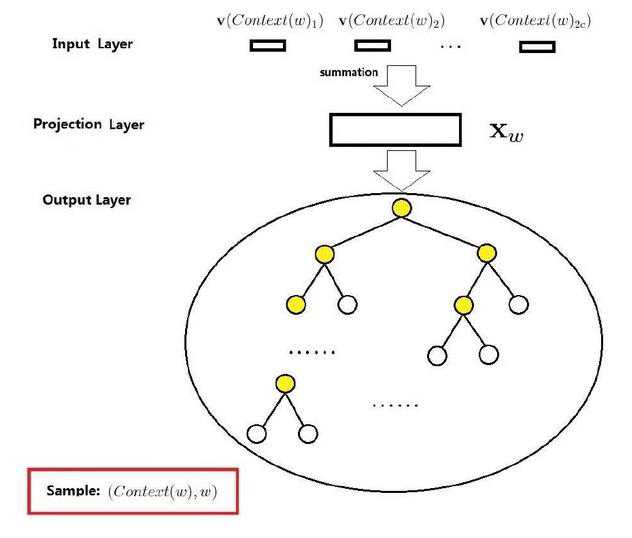
输入层是上下文的词语的词向量,在训练CBOW模型,词向量只是个副产品,确切来说,是CBOW模型的一个参数。训练开始的时候,词向量是个随机值,随着训练的进行不断被更新)。
投影层对其求和,所谓求和,就是简单的向量加法。
输出层输出最可能的w。由于语料库中词汇量是固定的|C|个,所以上述过程其实可以看做一个多分类问题。给定特征,从|C|个分类中挑一个。

如果我最后需要得到足球这个词,那么流程就是:
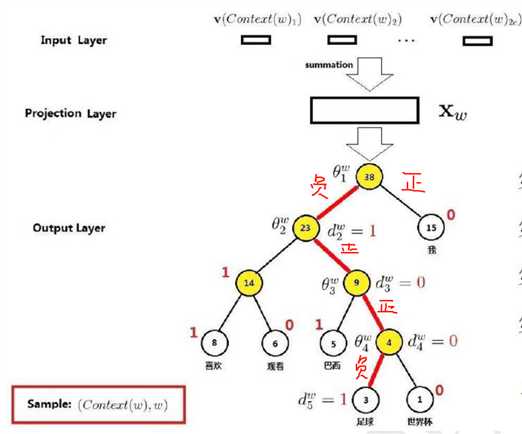 .
.

如何求解:
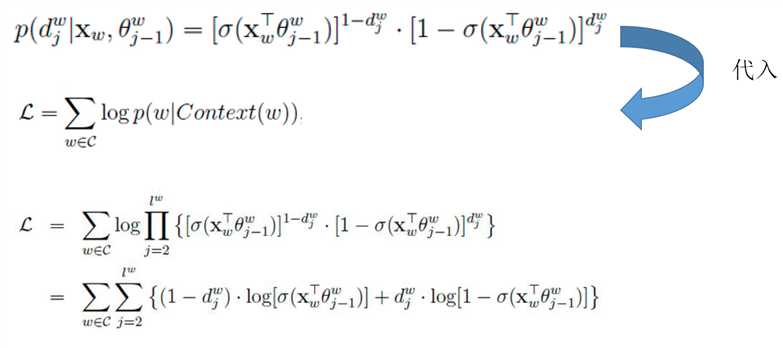
目标函数:
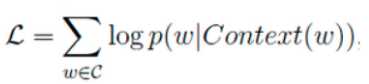
越大越好
求它的最大值也就是求一个梯度上升的问题。


因为和向量和每一个词向量是线性相关的,所以对和向量更新可以应用到每一个词向量当中
skip-gram:
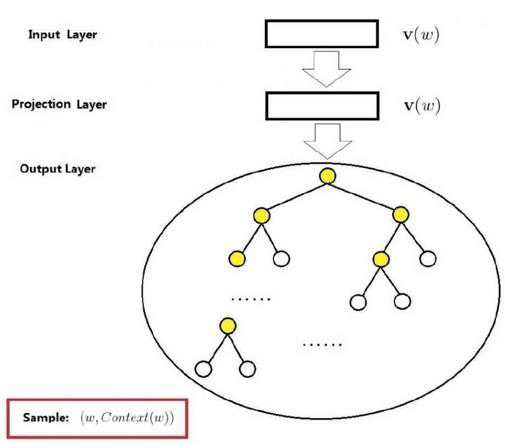

还需要考虑的一个问题,如果语料库非常大,即使用了哈夫曼树的话,常见的排在最前面,那么有很多不常见的排在后面,这样就会使计算复杂度变得非常大。
有一种解决方法叫做Negative Sampling(负采样):

我们希望预测对的就可能性达到最大化。
累乘的意思就是所有的词都可以预测对。


所求的值是一样的,只不过通过另外一种方法描述出来了,前者是通过霍夫曼树,现在是通过区间取值。
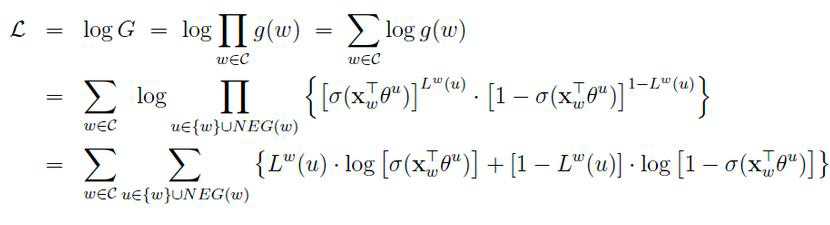
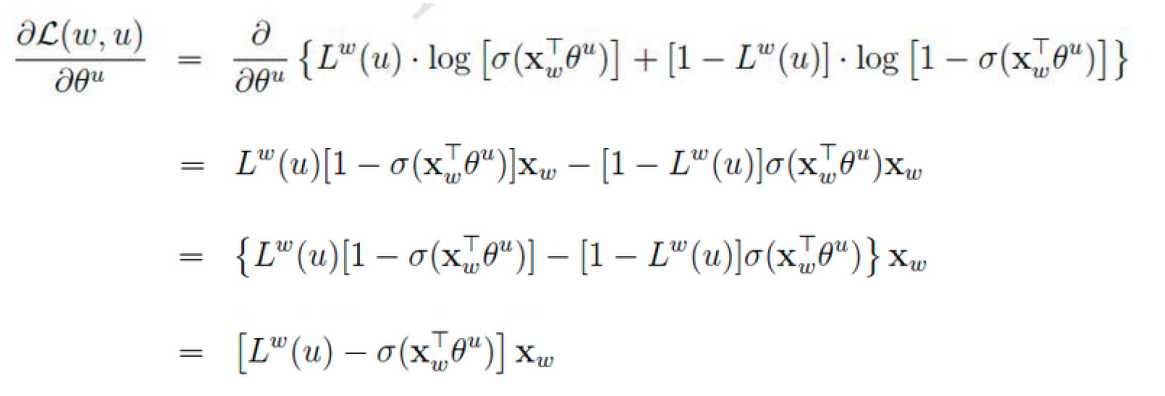
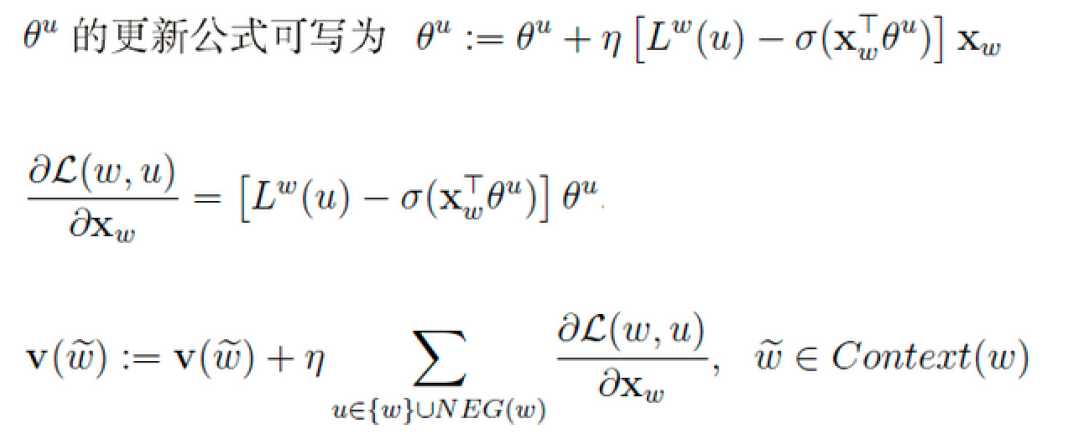
最后更新词向量
002-词向量,神经网络模型,CBOW,哈夫曼树,Negative Sampling
标签:训练 转换 nbsp 出现 不同 上下文 目的 cti 解决
原文地址:https://www.cnblogs.com/Mjerry/p/9819949.html