标签:gen 说明 处理 pga 架构设计 使用 核心 避免 源码
寄存器堆(Register File)是微处理的关键部件之一。寄存器堆往往具有多个读写端口,其中写端口往往与多个处理单元相对应。传统的方法是使用集中式寄存器堆,即一个集中式寄存器堆匹配N个处理单元。随着端口数量的增加,集中式寄存器堆的功耗、面积、时序均会呈幂增长,进而可能降低处理器总体性能。
下图所示为传统的集中式寄存器堆结构:
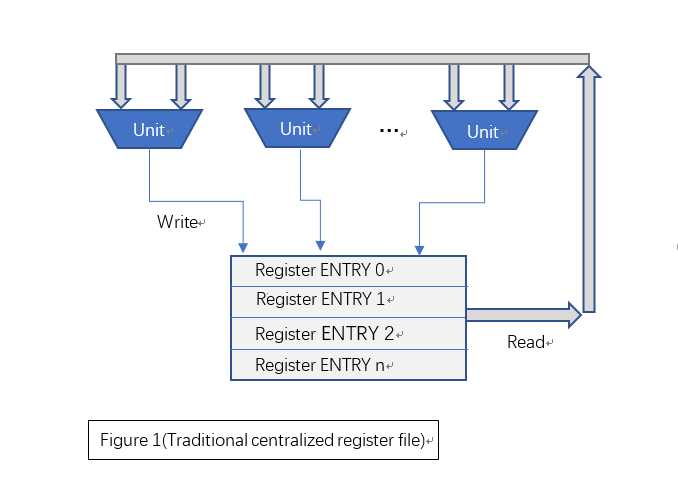
本文讨论一种基于分布存储和面积与时序互换原则的多端口寄存器堆设计,我们暂时称之为“分布式寄存器堆”。该种寄存器从端口使用上,仍与集中式寄存器堆完全兼容,但该寄存器堆使用多个寄存器簇和块分布式地存储操作数。当并行写入时,各寄存器簇分布式地存储写入结果;当读出时,由相应的仲裁算法在多个寄存器簇的结果中选取确定的一个簇作为最终输出。图二显示了这种分布式寄存器堆的逻辑结构。
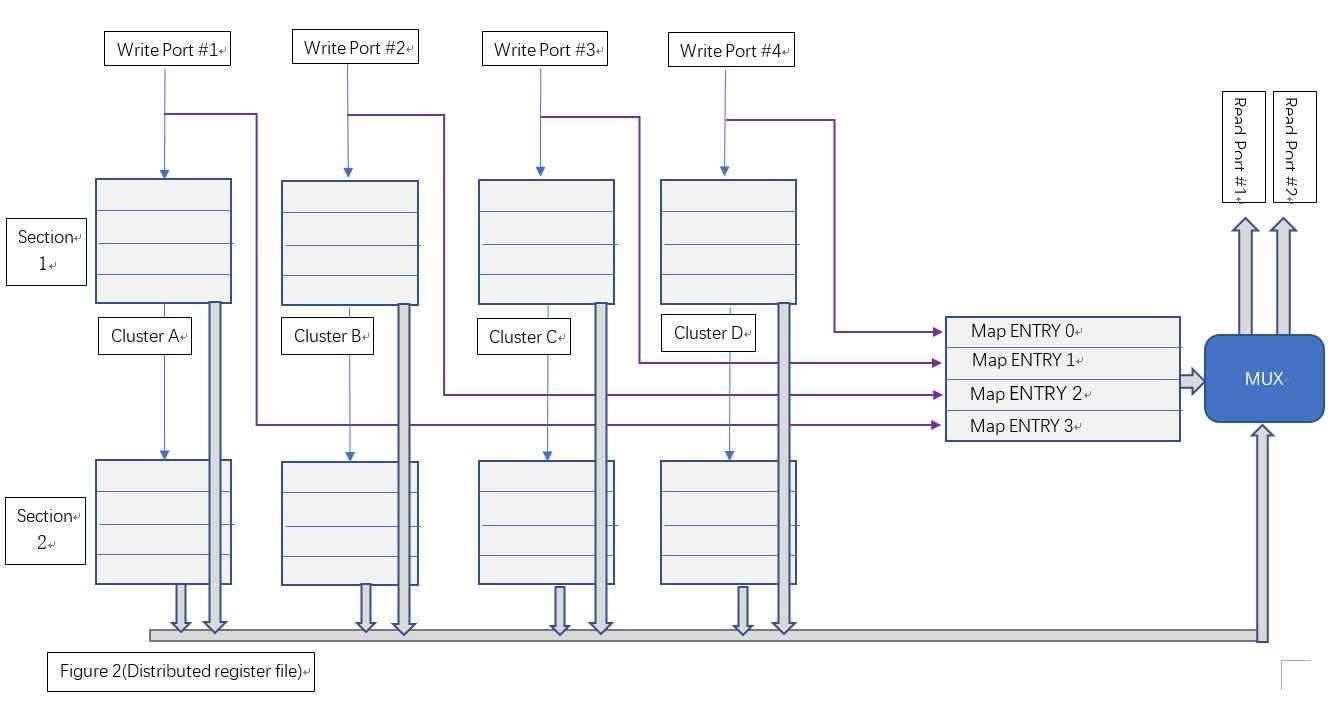
该结构主要由区块(Section)和簇(Cluster)两个维度组织寄存器:
(1)、从Section层面看,Section 1和Section 2是两个完全相同的组成结构(相当于逻辑的复制),同时两个Section中寄存器所持有的操作数也完全相同。一个Section只能处理一个读端口的操作。Section1负责处理读端口#1,而Section2负责处理读端口#2。
(2)、从Cluster层面看,Cluster A、B、C、D是几个分别独立的集中式寄存器堆,其具体结构可等价为一个双口RAM。写入时,Clusters分别独立地写入各自要求的地址。读出时,各Cluster从相同的读出地址读出各自的数据,最后将4个数据送到MUX进行最后的仲裁。
综上,单个Section负责单个读端口操作,单个Cluster负责单个写端口操作。
分布式寄存器堆的设计关键在于仲裁调度算法。由于一个Section只负责处理一个读端口的操作,我们首先从单个Section维度考虑。虽然单个周期内需要同时处理4个写端口,但读端口是唯一的。事先记录每个写端口的地址所对应的Cluster编号,在读出时,通过读出地址反向获取对应的Cluster,进而从该Cluster取出最终结果。
其次再考虑多个读端口并行操作。考虑复制两个相同的Section逻辑,并将所有写端口并联起来,则可以保证两个Section所持有的操作数完全相同。对两个Section同时进行读操作,这样便实现了并行地读出两个不同地址的数据。
接下来设计两个关键部件:Cluster寄存器堆和数据仲裁器。
一、Cluster寄存器的设计
上文已经提到过,Cluster寄存器可等价为双端口RAM。关于DPRAM的具体结构可参考相关资料,本文不再赘述。DPRAM容量根据最为通用的配置,采用32x32bit设计,可通过例化参数设置地址总线和数据总线的宽度。利用Verilog描述一个同步时钟DPRAM的源码如下:

1 module dpram_sclk 2 #( 3 parameter ADDR_WIDTH = 32, 4 parameter DATA_WIDTH = 32, 5 parameter CLEAR_ON_INIT = 1, // Whether to rest the RAM while initialization (for simulation only) 6 parameter ENABLE_BYPASS = 1 // Whether enable data bypass 7 ) 8 (/*AUTOARG*/ 9 // Outputs 10 dout, 11 // Inputs 12 clk, rst, raddr, re, waddr, we, din 13 ); 14 15 // Port List 16 input clk; 17 input rst; 18 input [ADDR_WIDTH-1:0] raddr; 19 input re; 20 input [ADDR_WIDTH-1:0] waddr; 21 input we; 22 input [DATA_WIDTH-1:0] din; 23 output [DATA_WIDTH-1:0] dout; 24 25 reg [DATA_WIDTH-1:0] mem[(1<<ADDR_WIDTH)-1:0]; 26 reg [DATA_WIDTH-1:0] rdata; 27 reg re_r; 28 wire [DATA_WIDTH-1:0] dout_w; 29 30 generate 31 if(CLEAR_ON_INIT) begin :clear_on_init 32 integer entry; 33 initial begin 34 for(entry=0; entry < (1<<ADDR_WIDTH); entry=entry+1) // reset 35 mem[entry] = {DATA_WIDTH{1‘b0}}; 36 end 37 end 38 endgenerate 39 40 // bypass control 41 generate 42 if (ENABLE_BYPASS) begin : bypass_gen 43 reg [DATA_WIDTH-1:0] din_r; 44 reg bypass; 45 46 assign dout_w = bypass ? din_r : rdata; 47 48 always @(posedge clk) 49 if (re) din_r <= din; 50 51 always @(posedge clk) 52 if (waddr == raddr && we && re) 53 bypass <= 1; 54 else 55 bypass <= 0; 56 end else begin 57 assign dout_w = rdata; 58 end 59 endgenerate 60 61 // R/W logic 62 always @(posedge clk) 63 re_r <= rst ? 1‘b0 : re; 64 65 assign dout = re_r ? dout_w : {DATA_WIDTH{1‘b0}}; 66 67 always @(posedge clk) begin 68 if (we) 69 mem[waddr] <= din; 70 if (re) 71 rdata <= mem[raddr]; 72 end 73 74 endmodule
值得注意的是,实现中加入了数据旁通机制,保证当发生同时读写且地址相同时,写入数据能在单个操作周期内送达读端口。
二、数据仲裁器的设计
数据仲裁器的核心是维护一个写入地址→Cluster编号的映射表。假设分布式寄存器堆总共有32个寄存器(以5bit地址总线寻址),则我们需要一个表项数为32的列表,存储每个地址对应的Cluster编号。Verilog描述如下:
reg [1:0] sel_map[(1<<ADDR_WIDTH)-1:0];
对于每个写端口,在写操作周期维护映射表,记录下写入地址对应的Cluster,实现如下:
1 // Maintain the selection map 2 always @(posedge clk) begin 3 if (we1) 4 sel_map[waddr1] <= 2‘d0; 5 if (we2) 6 sel_map[waddr2] <= 2‘d1; 7 if (we3) 8 sel_map[waddr3] <= 2‘d2; 9 if (we4) 10 sel_map[waddr4] <= 2‘d3; 11 end
对于读端口,先从映射表获取实际存储目标操作数的Cluster,然后利用多路复用器选取其输出,作为该Section的最终读取结果。
1 // mux 2 assign dout = sel_map[raddr]==2‘d0 ? dout0 : 3 sel_map[raddr]==2‘d1 ? dout1 : 4 sel_map[raddr]==2‘d2 ? dout2 : 5 sel_map[raddr]==2‘d3 ? dout3 : 6 {DATA_WIDTH{1‘b0}}; /* never got this */
由此,我们可以得出单个Section的完整设计:
1 module cpram_sclk_4w1r #( 2 parameter ADDR_WIDTH = 5, 3 parameter DATA_WIDTH = 32, 4 parameter CLEAR_ON_INIT = 1, // Whether to rest the RAM while initialization (for simulation only) 5 parameter ENABLE_BYPASS = 1 // Whether enable data bypass 6 ) 7 (/*AUTOARG*/ 8 // Outputs 9 rdata, 10 // Inputs 11 clk, rst, we1, waddr1, wdata1, we2, waddr2, wdata2, we3, waddr3, 12 wdata3, we4, waddr4, wdata4, re, raddr 13 ); 14 15 // Ports 16 input clk; 17 input rst; 18 input we1; 19 input [ADDR_WIDTH-1:0] waddr1; 20 input [DATA_WIDTH-1:0] wdata1; 21 input we2; 22 input [ADDR_WIDTH-1:0] waddr2; 23 input [DATA_WIDTH-1:0] wdata2; 24 input we3; 25 input [ADDR_WIDTH-1:0] waddr3; 26 input [DATA_WIDTH-1:0] wdata3; 27 input we4; 28 input [ADDR_WIDTH-1:0] waddr4; 29 input [DATA_WIDTH-1:0] wdata4; 30 input re; 31 input [ADDR_WIDTH-1:0] raddr; 32 output [DATA_WIDTH-1:0] rdata; 33 34 // Internals 35 wire [DATA_WIDTH-1:0] dout; 36 wire [DATA_WIDTH-1:0] dout0; 37 wire [DATA_WIDTH-1:0] dout1; 38 wire [DATA_WIDTH-1:0] dout2; 39 wire [DATA_WIDTH-1:0] dout3; 40 reg [1:0] sel_map[(1<<ADDR_WIDTH)-1:0]; 41 42 // instance of sync dpram #1 for Cluster A 43 dpram_sclk 44 #( 45 .ADDR_WIDTH (ADDR_WIDTH), 46 .DATA_WIDTH (DATA_WIDTH), 47 .CLEAR_ON_INIT (CLEAR_ON_INIT), 48 .ENABLE_BYPASS (ENABLE_BYPASS) 49 ) 50 mem0 51 ( 52 .clk (clk), 53 .rst (rst), 54 .dout (dout0), 55 .raddr (raddr), 56 .re (re), 57 .waddr (waddr1), 58 .we (we1), 59 .din (wdata1) 60 ); 61 // instance of sync dpram #2 for Cluster B 62 dpram_sclk 63 #( 64 .ADDR_WIDTH (ADDR_WIDTH), 65 .DATA_WIDTH (DATA_WIDTH), 66 .CLEAR_ON_INIT (CLEAR_ON_INIT), 67 .ENABLE_BYPASS (ENABLE_BYPASS) 68 ) 69 mem1 70 ( 71 .clk (clk), 72 .rst (rst), 73 .dout (dout2), 74 .raddr (raddr), 75 .re (re), 76 .waddr (waddr2), 77 .we (we2), 78 .din (wdata2) 79 ); 80 // instance of sync dpram #3 for Cluster C 81 dpram_sclk 82 #( 83 .ADDR_WIDTH (ADDR_WIDTH), 84 .DATA_WIDTH (DATA_WIDTH), 85 .CLEAR_ON_INIT (CLEAR_ON_INIT), 86 .ENABLE_BYPASS (ENABLE_BYPASS) 87 ) 88 mem2 89 ( 90 .clk (clk), 91 .rst (rst), 92 .dout (dout3), 93 .raddr (raddr), 94 .re (re), 95 .waddr (waddr3), 96 .we (we3), 97 .din (wdata3) 98 ); 99 // instance of sync dpram #4 for Cluster D 100 dpram_sclk 101 #( 102 .ADDR_WIDTH (ADDR_WIDTH), 103 .DATA_WIDTH (DATA_WIDTH), 104 .CLEAR_ON_INIT (CLEAR_ON_INIT), 105 .ENABLE_BYPASS (ENABLE_BYPASS) 106 ) 107 mem3 108 ( 109 .clk (clk), 110 .rst (rst), 111 .dout (dout3), 112 .raddr (raddr), 113 .re (re), 114 .waddr (waddr4), 115 .we (we4), 116 .din (wdata4) 117 ); 118 119 // mux 120 assign dout = sel_map[raddr]==2‘d0 ? dout0 : 121 sel_map[raddr]==2‘d1 ? dout1 : 122 sel_map[raddr]==2‘d2 ? dout2 : 123 sel_map[raddr]==2‘d3 ? dout3 : 124 {DATA_WIDTH{1‘b0}}; /* never got this */ 125 126 // Read output with/without bypass controlling 127 generate 128 if (ENABLE_BYPASS) begin : bypass_gen 129 assign rdata = 130 (we1 && (raddr==waddr1)) ? wdata1 : 131 (we2 && (raddr==waddr2)) ? wdata2 : 132 (we3 && (raddr==waddr3)) ? wdata3 : 133 (we4 && (raddr==waddr4)) ? wdata4 : 134 dout; 135 end else begin 136 assign rdata = dout; 137 end 138 endgenerate 139 140 // Maintain the selection map 141 always @(posedge clk) begin 142 if (we1) 143 sel_map[waddr1] <= 2‘d0; 144 if (we2) 145 sel_map[waddr2] <= 2‘d1; 146 if (we3) 147 sel_map[waddr3] <= 2‘d2; 148 if (we4) 149 sel_map[waddr4] <= 2‘d3; 150 end 151 endmodule
值得说明的是:上述实现仍然需要考虑四个写端口与一个读端口的数据旁通路径。通过例化参数ENABLE_BYPASS可以指定是否使用数据旁通逻辑。
将两个Section写端口并联,并分别引出其读端口,即构成了一个4w 2r寄存器堆。
总结
本文讨论的数据的分布存储方法和基于面积换时序的逻辑复制方法,在集中存储式寄存器堆的优化中取得了较好的效果。但该结构缺点也十分明显:首先,对集中寄存器堆的复制无疑增加了面积和功耗,其次,随着写端口数的增加,仲裁逻辑的规模也随之增长,这将导致数据路径延迟增加,进而降低寄存器堆时钟工作频率。
相比于ASIC设计,本结构更适合于FPGA验证。理由如下:在FPGA中,寄存器是非常有限的资源。若直接实现一定规模的RAM结构,则需要大量占用寄存器资源。为此,FPGA在硬件上集成了RAM Block资源。这些RAM Blocks多可配置为双端口模式,但对于更复杂的端口配置(如本例的4w2r),则只能间接实现。
本设计完全采用RAM Blocks实现多端口寄存器堆。因为FPGA综合工具在分析verilog源码时,将自动识别出我们所采用的DPRAM,转而使用RAM Block资源,避免占用寄存器资源,为设计的其它部分留出更多可用的寄存器资源。同时,这将避免使用LUT实现复杂的RAM单元寻址和控制逻辑,从而优化时序。
2018 10.20
===================================================
本博文仅供参考,难免有疏漏之处,欢迎提出宝贵意见。
标签:gen 说明 处理 pga 架构设计 使用 核心 避免 源码
原文地址:https://www.cnblogs.com/sci-dev/p/9822994.html
