标签:hyper systemctl 在线 下载 com 推荐 vmw 就是 tin
Nova 是 openstack 最核心的服务,负责管理和维护云环境的计算资源,虚拟机的生命周期管理就是通过 Nova 来实现的 。
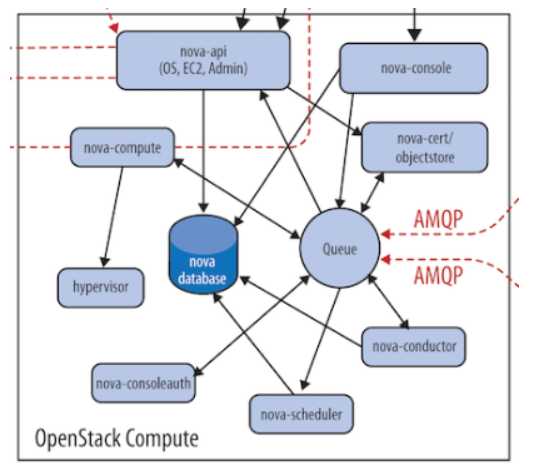
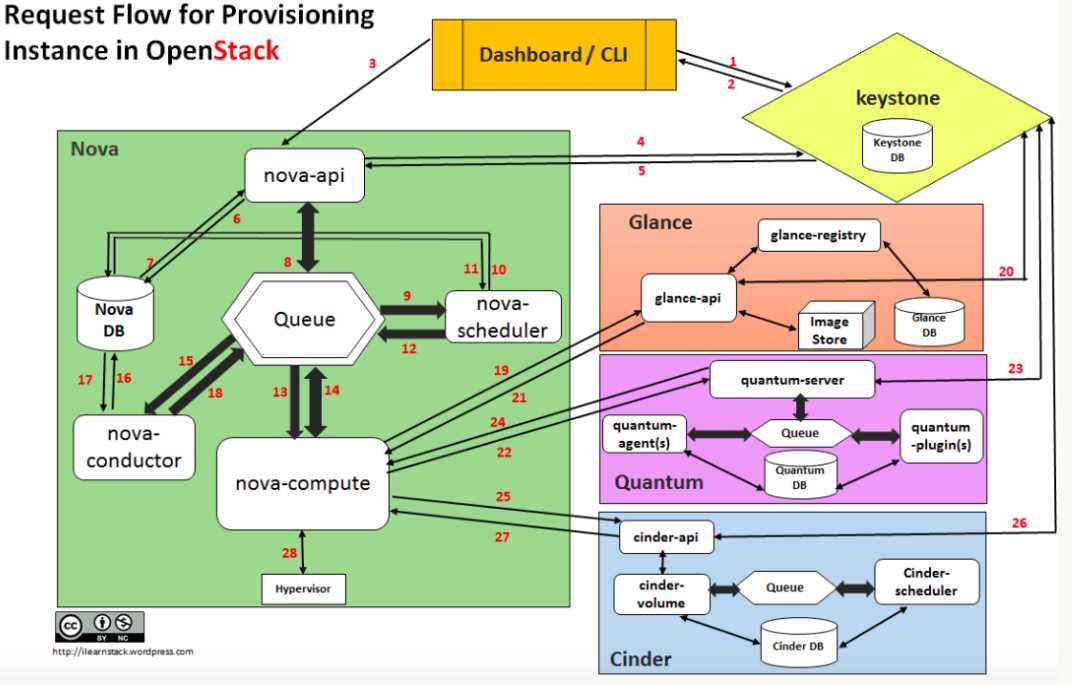
如上图所示,Nova 由多个组件构成,这些组件以子服务的形式运行 。
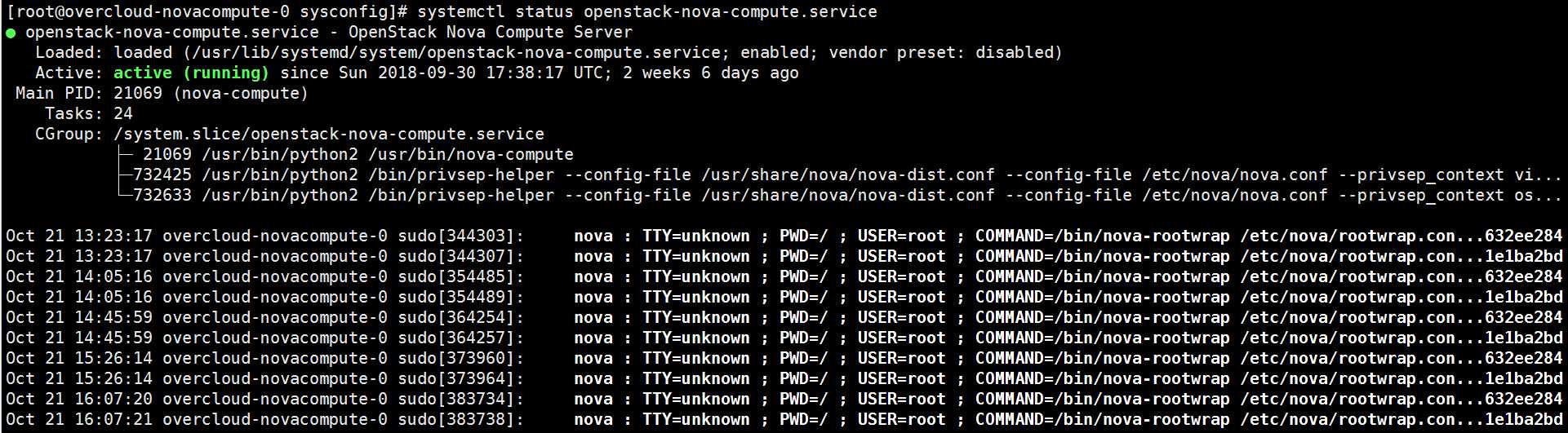
举例,通过 systemctl status openstack-nova-compute.service 判断 nova - compute 服务是否运行:
Nova 主要组件:
nova - compute 服务一般部署在计算节点上,其它子服务一般部署在控制节点上。
命令 nova service-list 显示 nova 服务运行在哪个节点上:

登陆 controller 查看 nova-scheduler 服务是否运行:

这篇文章写的非常好: https://ilearnstack.com/2013/04/26/request-flow-for-provisioning-instance-in-openstack/ ,强烈推荐,这里不做赘述 。
openstack nova 的 Log 存放路径为 /var/log/nova/ 。
日志格式为 <时间戳><日志等级><代码模块><Request ID><日志内容><源代码位置>, 分别进行介绍:

代码模块为 nova.compute.manager, 找到该模块:

nova - api 是 Nova 组件的门户,所有对 Nova 的请求首先会由 nova - api 进行处理。
关于虚机生命周期相关的操作,nova - api 都可以处理, openstack dashboard 中 Instances 栏的下拉菜单中记录着 nova -api 可执行的操作。
nova - scheduler 根据用户的资源需求进行调用,资源需求包括 VCPU, RAM, DISK 和 Metadata , 这些资源需求定义在 flavor 中。
如何根据 flavor 进行调用?
nova - scheduler 的默认调度器是 Filter scheduler , 当Filter scheduler 执行调度操作时,会让 filter 选择满足 flavor 的计算节点,当选出满足条件的计算节点之后计算各计算节点的权重以选择最优的计算节点,在该计算节点上创建 instance。
/etc/nova/nova.conf 中指明了默认的 filter:

RetryFilter: 刷掉已经调度过的节点。
AvailabilityZoneFilter: 将不属于指定 Availability Zone 的计算节点过滤掉,关于 Availability Zone 的介绍和设置可见这篇博文。
ComputeFilter: 保证只有 nova - compute 服务正常工作的计算阶段才能够被 nova - scheduler 调度。
ServerGroupAntiAffinityFilter: 尽量将 Instance 分散部署到不同的节点上,前提是将 Instance 要加入到 Group 中,如果没有指定 server group, Filter 将不做任何过滤。
nova - compute 在计算节点上运行,负责管理节点上的 instance。
openstack 对 instance 的操作,最后都是交给 nova-compute 来完成的,nova-compute 与 Hypervisor 一起实现 OpenStack 对 instance 生命周期的管理。
nova-compute 的功能可以分为两类:
Hypervisor 最清楚计算节点的信息,可以通过 virsh nodeinfo 和 virsh dominfo 命令查看计算节点和instance的信息:
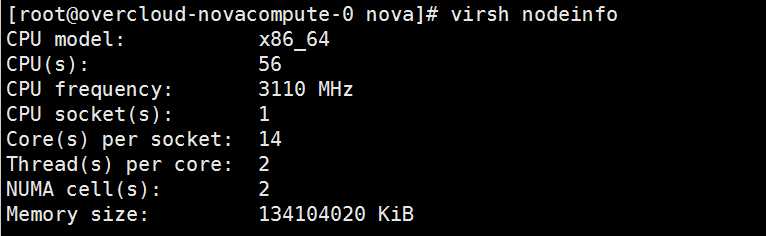
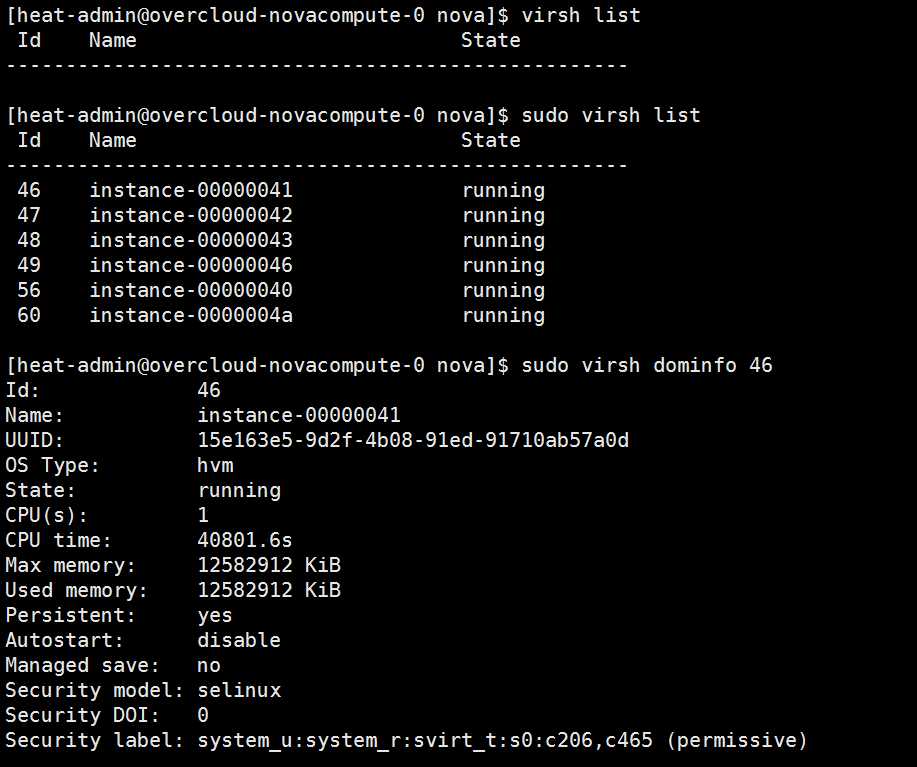
注意要查看计算节点上运行的 instance 信息,需要切换到 root 用户,否则什么都显示不出来。
通过这些命令,也可以计算出这个 instance 还能够容纳多大 flavor 的 instance 。
通过 log 来分析这一创建过程,Debug 选项没开。
步骤如下:
1. 用户向 nova - api 发送请求: "create instance"

2. nova - scheduler 完成 调度,选择 compute-0 作为 instance 部署的节点

3. nova - compute 首先根据 flavor 为 instance 分配内存,磁盘空间和 vCPU
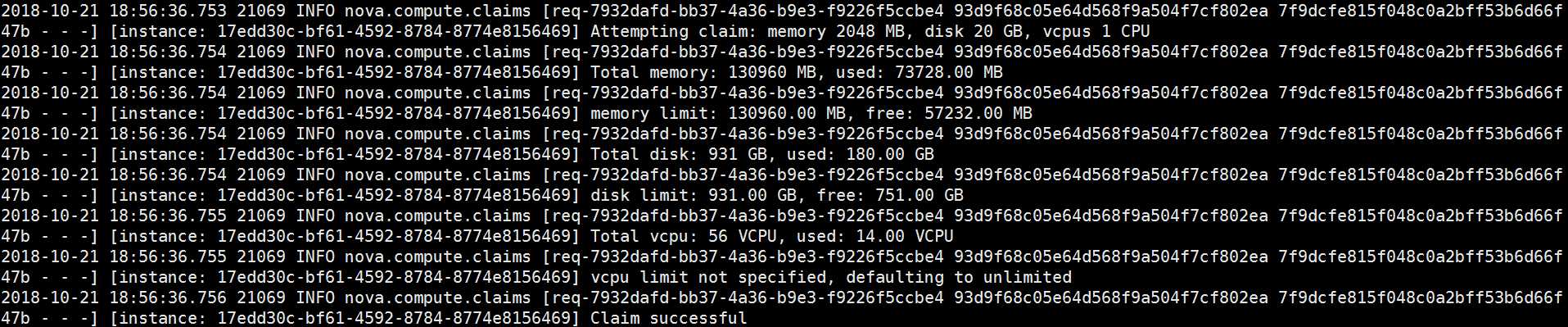
flavor 所需的资源分配好了之后再分配网络资源给 instance:

为 instance 创建 image :

要注意的是 nova - compute 会检查该 image 在 compute node 上是否存在,如果存在则直接使用,如果不存在,则 ssh 到 glance 通过 scp 下载 image 到本地:

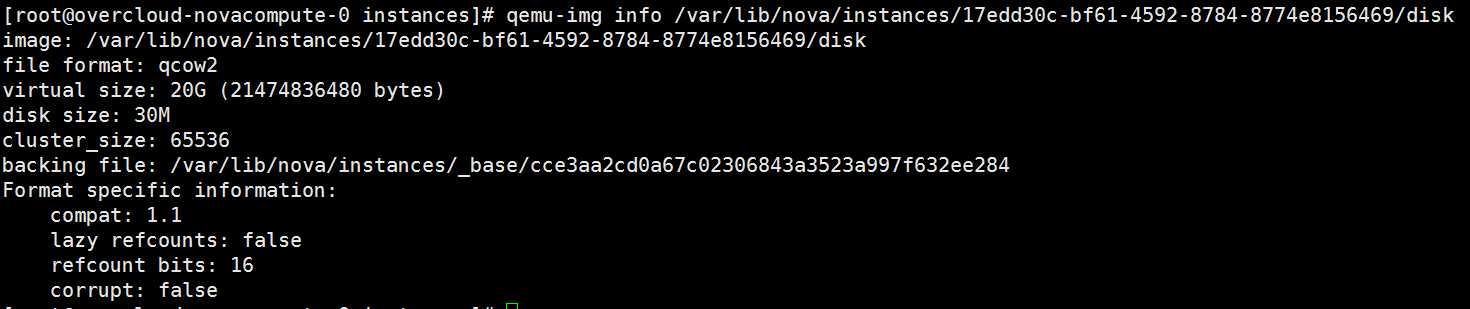
将上传的 image 下载到 /var/lib/nova/instances/_base/ 目录下,下载下来的 image uuid 为 cce3aa2cd0a67c02306843a3523a997f632ee284, 通过 qemu-img info 命令查看该 image 的格式为:

instance 的镜像为 qcow2 格式,因此还需将 raw 格式的 image 转换为 qcow2 的 image 给 instance 用,转换后的 image 在 /var/lib/nova/instances 目录下,uuid 为 17edd30c-bf61-4592-8784-8774e8156469,该uuid 即为 instance 的 uuid 。

同理,通过 qemu-img info 查看该 image 是否为 qcow2 格式:
4. instance 创建成功

Rescue: 故障恢复机制,由于误操作或者突然断电等操作使得操作系统起不来了,为了最大限度挽救数据,使用一张系统盘将系统引导起来,然后在尝试恢复。 问题如果不太严重,可以通过这种方式让系统重新正常工作。
Soft Reboot: 重启操作系统,整个过程中,instance 依然处于运行状态,相当于在 linux 中执行 reboot 命令。
Hard Reboot: 重启 instance,相当于关机之后再开机 。
Migrate: 将 instance 从当前的计算节点迁移到其他节点上,不要求源和目标节点必须共享存储,Migrate 前必须满足一个条件:计算节点间需要配置 nova 用户无密码访问。
Live Migrate: 在线迁移,instance 不会停机,分为共享存储迁移和非共享存储迁移。
关于共享存储 NFS 的内容可见这篇博文。
Resize: 调整 instance 的 vCPU、内存和磁盘资源,Migrate 是特殊的 Resize,因为迁移过程中flavor未改变。
参考文章:
https://www.cnblogs.com/CloudMan6/p/5548294.html
https://www.cnblogs.com/liuyisai/p/5992511.html
标签:hyper systemctl 在线 下载 com 推荐 vmw 就是 tin
原文地址:https://www.cnblogs.com/xingzheanan/p/9826632.html