标签:内核 bubuko 实际应用 enc hold jvm 程序 变更 评分
master节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data节点可以关闭http功能。
这里node.master : true 是说明你是有资格成为master,并不是指你就是master。是皇子,不是皇帝。假如有10个皇子,这里应该设置为(10/2)+1=6,这6个皇子合谋做决策,选出新的皇帝。另外的4个皇子,即使他们全聚一起也才四个人,不足合谋的最低人数限制,他们不能选出新皇帝。假如discovery.zen.minimum_master_nodes 设置的个数为5,有恰好有10个master备选节点,会出现什么情况呢?5个皇子组成一波,选一个皇帝出来,另外5个皇子也够了人数限制,他们也能选出一个皇帝来。此时一个天下两个皇帝,在es中就是脑裂。
我还是用皇子的例子来说明。假如先皇在位的时候规定,必须他的两个皇子都在的时候,才能从中2选1 继承皇位。万一有个皇子出意外挂掉了,就剩下一个皇子,天下不就没有新皇帝了么。
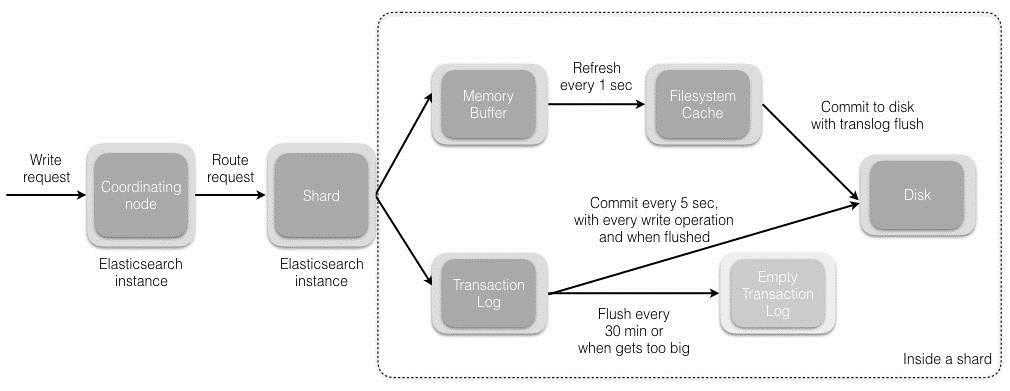
shard = hash(document_id) % (num_of_primary_shards)
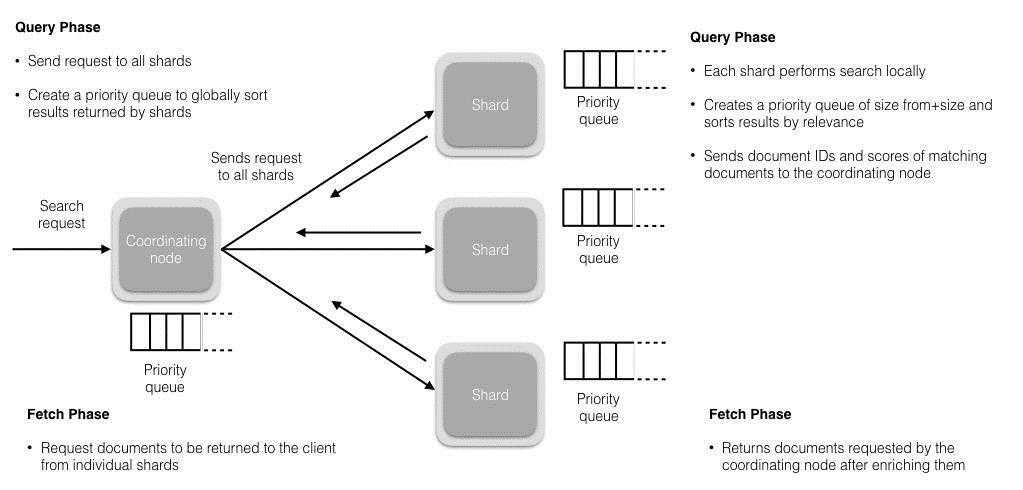
Query Then Fetch的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch增加了一个预查询的处理,询问Term和Document frequency,这个评分更准确,但是性能会变差。
标签:内核 bubuko 实际应用 enc hold jvm 程序 变更 评分
原文地址:https://www.cnblogs.com/yangwenbo214/p/9831479.html