标签:css track 启动器 模式 生命周期 pre 文件 ast 交互
Spark是一个用来实现快速而通用的集群计算的平台。扩展了广泛使用的MapReduce计算模型,而且高效地支持更多的计算模式,包括交互式查询和流处理。在处理大规模数据集的时候,速度是非常重要的。Spark的一个重要特点就是能够在内存中计算,因而更快。即使在磁盘上进行的复杂计算,Spark依然比MapReduce更加高效。Spark与Hadoop紧密集成,他可以在YARN上运行,并支持Hadoop文件格式及其储存后端HDFS
| Mapreduce | Spark |
| 数据存储结构:hdfs文件系统的split |
使用内存构建弹性分布式数据集RDD,对数据进行运算和cache |
| 编程范式:Map+Reduce | 计算中间数据在内存中的维护,存取速度是磁盘的多个数量级 |
| Task以进程的方式维护,任务启动就要几秒钟 | Task以线程的方式维护,对小数集的读取能达到亚秒级的延迟 |
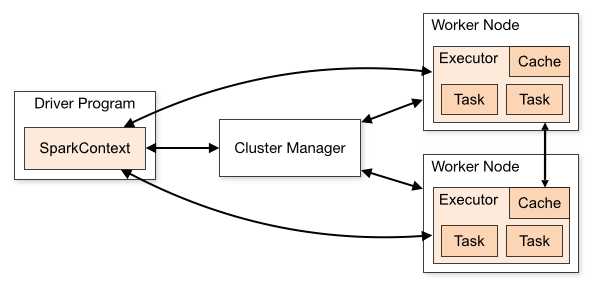
组件的功能
ClusterManager:在Standalone模式中即为Master节点(主节点),控制整个集群,监控Worker.在YARN中为ResourceManagerWorker:从节点,负责控制计算节点,启动Executor或Driver。在YARN模式中为
NodeManager:负责计算节点的控制。
Driver:运行Application的main()函数并创建SparkContect。
Executor:执行器,在worker node上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executor。
SparkContext:整个应用的上下文,控制应用的生命周期。
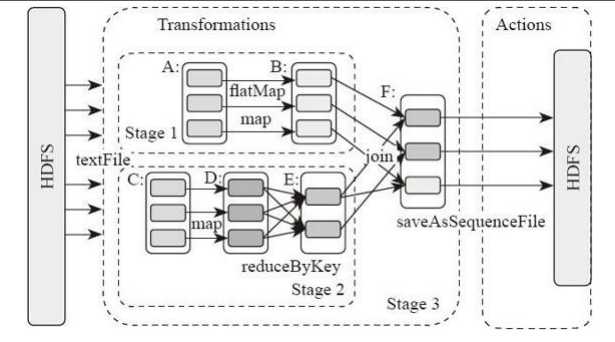
RDD:Spark的计算单元,一组RDD可形成执行的有向无环图RDD Graph。
DAG Scheduler:根据作业(Job)构建基于Stage的DAG,并提交Stage给TaskScheduler。
TaskScheduler:将任务(Task)分发给Executor。
SparkEnv:线程级别的上下文,存储运行时的重要组件的引用。
SparkEnv内构建并包含如下一些重要组件的引用:
1、MapOutPutTracker:负责Shuffle元信息的存储。
2、BroadcastManager:负责广播变量的控制与元信息的存储。
3、BlockManager:负责存储管理、创建和查找快。
4、MetricsSystem:监控运行时性能指标信息。
5、SparkConf:负责存储配置信息。
组件的执行流程
1. 每个Spark应用都由一个驱动器程序(Driver Program)来发起集群上的各种并行操作。启动器包含应用的main函数,驱动器负责创建SparkContext(上下文);SparkContext可以与不同种类的集群资源管理器(Cluster Manager),例如Yarn进行通信。
2. SparkContext 获取到集群进行所需的资源后,将得到集群中工作阶段(Worker Node)上对应的 Executor(不同的Spark程序有不同的Executor,他们之间是互相独立的进程,Executor为应用程序提供分布式计算以及数据存储功能)
3. 之后SparkContext将应用程序代码发送到各个Executor,最后将Task(任务)分配给Executors执行
1、Client提交应用。
2、Master找到一个Worker启动Driver
3、Driver向Master或者资源管理器申请资源,之后将应用转化为RDD Graph
4、再由DAGSchedule将RDD Graph转化为Stage的有向无环图提交给TaskSchedule。
5、再由TaskSchedule提交任务给Executor执行。
6、其它组件协同工作,确保整个应用顺利执行。
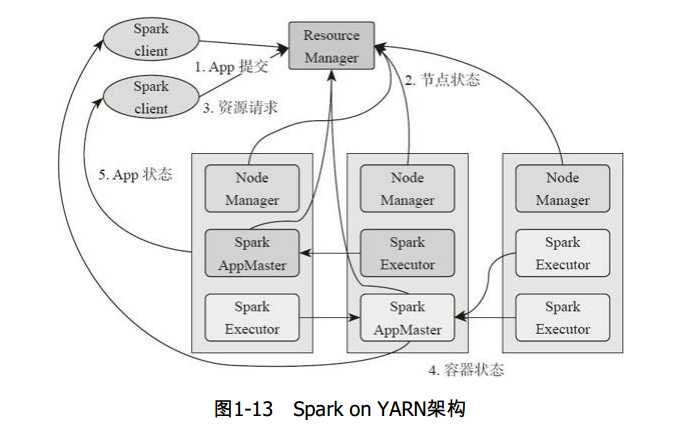
1、基于YARN的Spark作业首先由客户端生成作业信息,提交给ResourceManager。
2、ResourceManager在某一NodeManager汇报时把AppMaster分配给NodeManager。
3、NodeManager启动SparkAppMaster。
4、SparkAppMastere启动后初始化然后向ResourceManager申请资源。
5、申请到资源后,SparkAppMaster通过RPC让NodeManager启动相应的SparkExecutor。
6、SparkExecutor向SparkAppMaster汇报并完成相应的任务。
7、SparkClient会通过AppMaster获取作业运行状态。
标签:css track 启动器 模式 生命周期 pre 文件 ast 交互
原文地址:https://www.cnblogs.com/Thomas-blog/p/9838150.html