标签:生成 需要 技术分享 速度 href 文件 内容 新建 .com
此次是做一个豆瓣的top250信息的抓取
首先打开pycharm
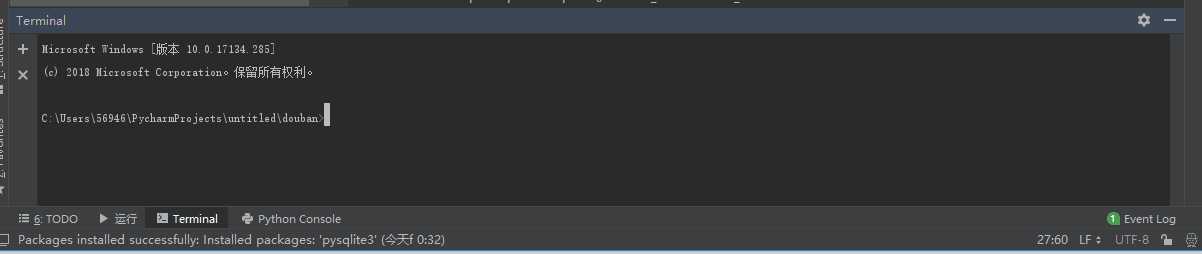
在pycharm的下端的Terminal中输入scrapy startproject douban
此时系统就生成了以下文件(spiders文件下自带一个_init_.py)还有一个_init_.py items.py middlewares.py piplines.py settings.py
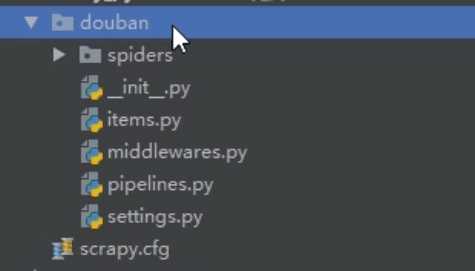
我们从第一次的随笔中知道scrapy框架只有三个东西需要我们操作一个是items、settings、还有个是等下创建的spider文件
首先打开items.py
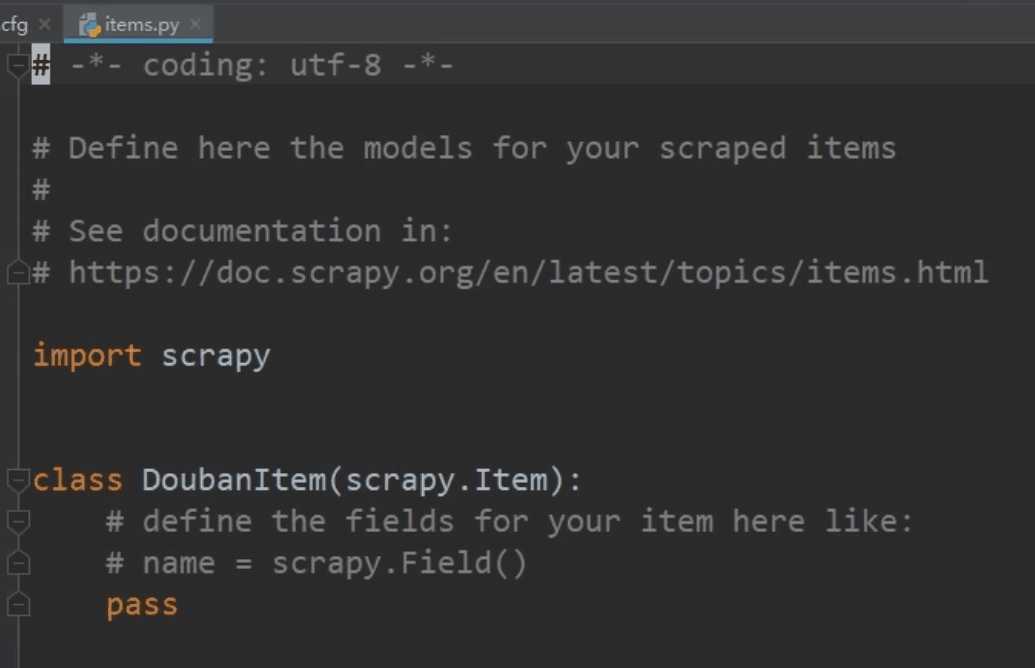
items.py是我们定义数据结构的地方 以后哪些东西要存放就现在这定义好
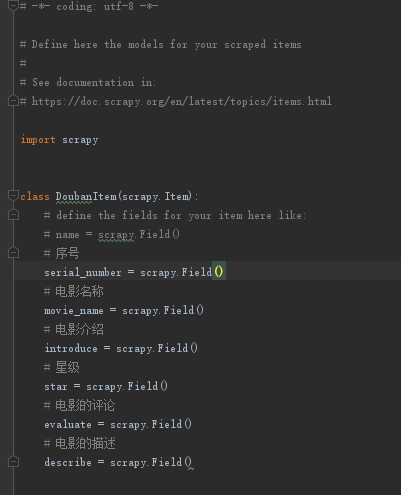
我们需要的是序号,电影名称,电影介绍,星级,电影评论,电影描述
可以模仿默认的# name = scrapy.Field()的形式创建自己需要的内容
然后我们更改settings.py
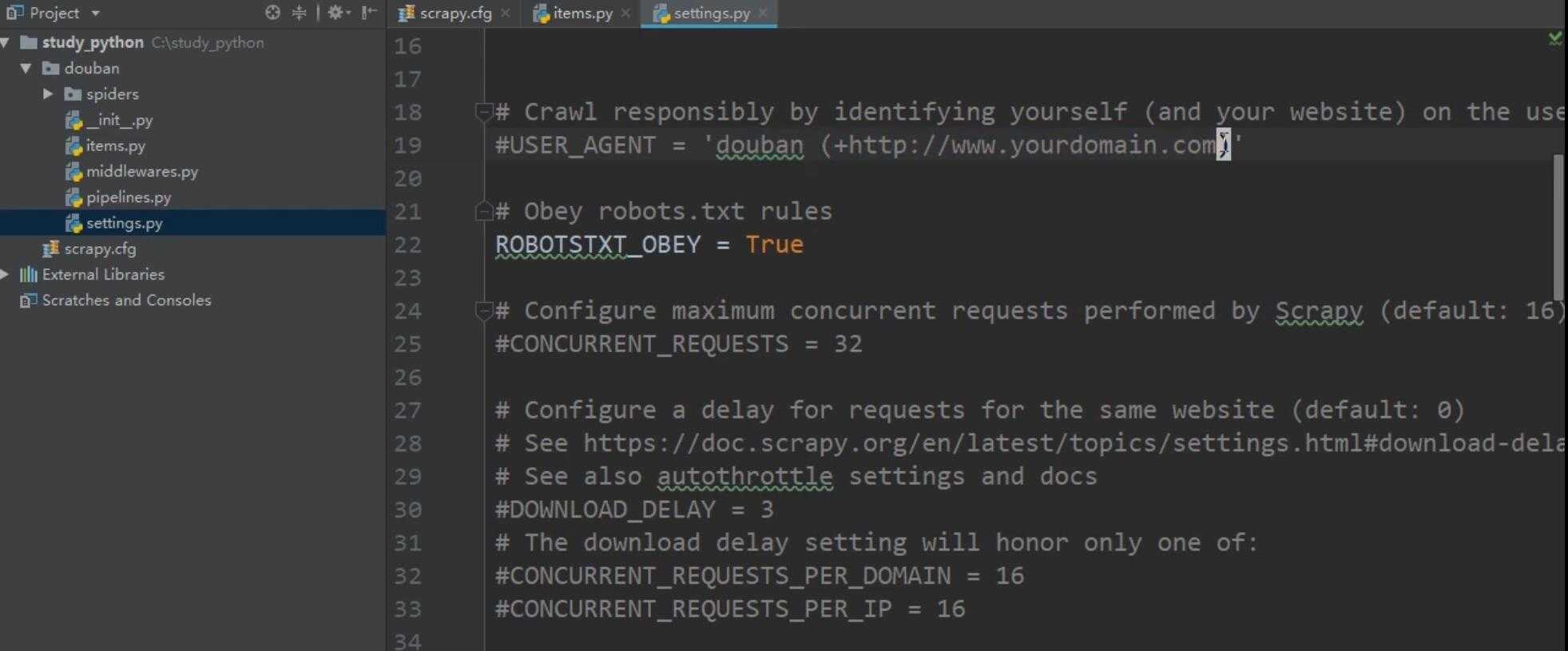
settings.py的内容比较多 首先找到ROBOTSTXT_OBEY = True
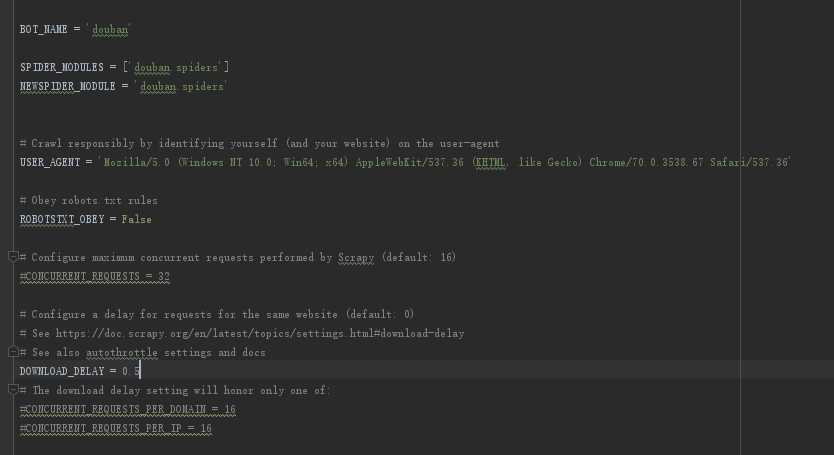
因为我们要做的事情是违背他这个规则的 所以第一件事是把True改成False
第二件事是将DOWNLOAD_DELAY = 3改成DOWNLOAD_DELAY = 0.5
因为这样我们抓取得速度可以快很多
最重要的是USER_AGENT
我们去我们目标网站:https://movie.douban.com/top250
按F12打开调试工具 按F5刷新页面 找到我们需要的top250文本查看html
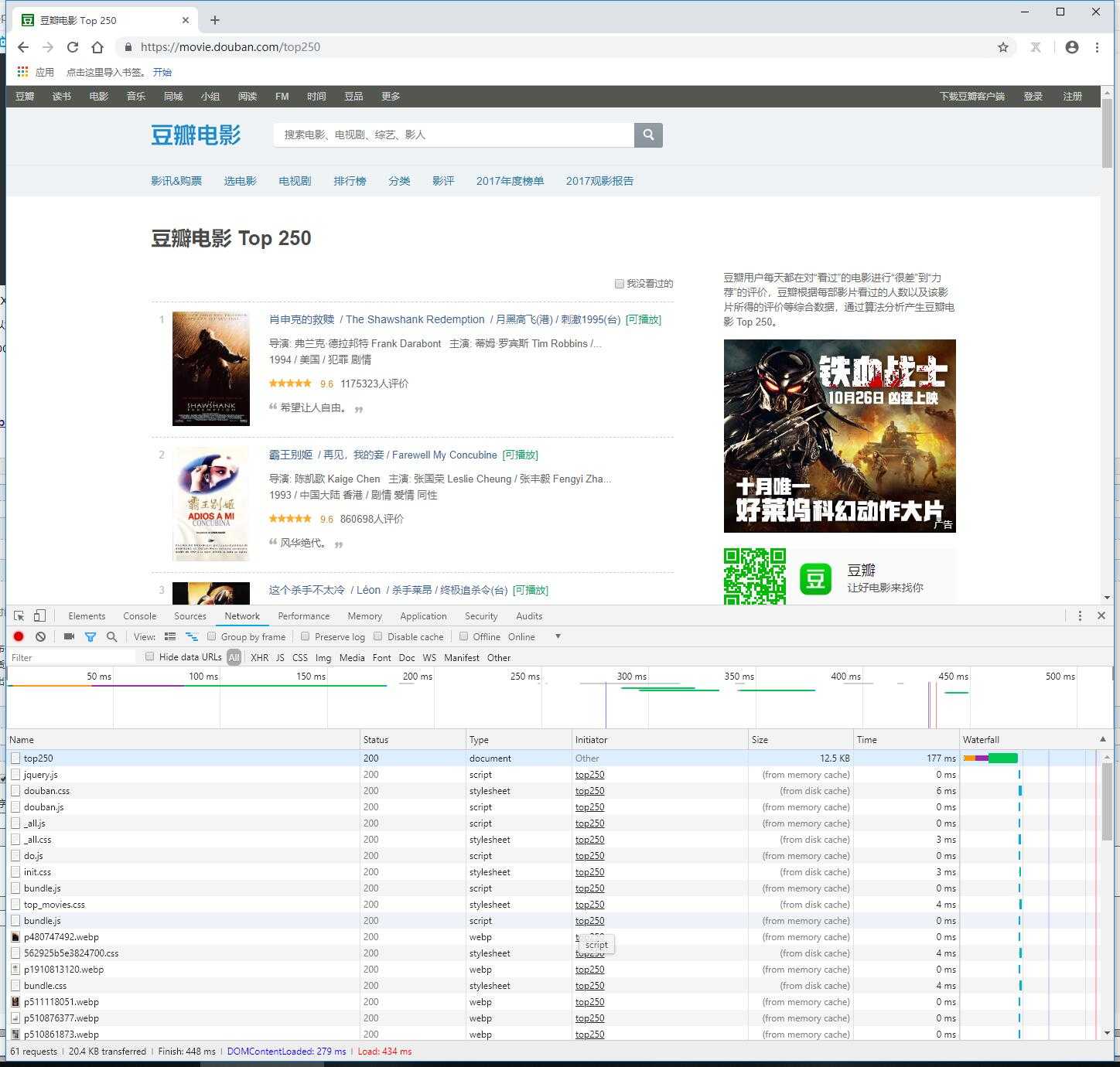
单击top250,往下拉找到USER_AGENT
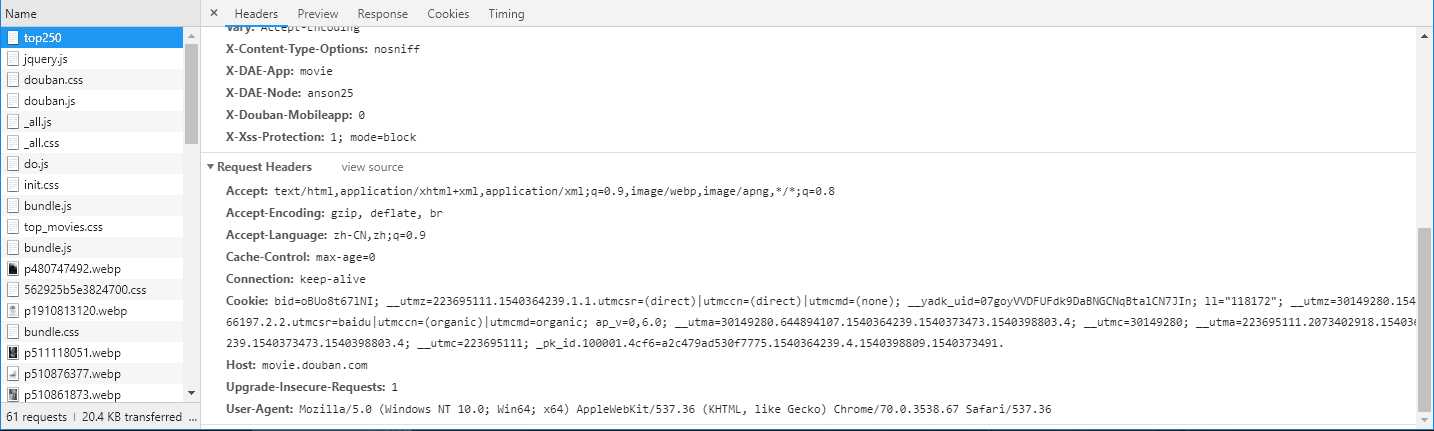
将内容拷贝到我们的settings.py中 这样我们目前setting.py就完成了
还有爬虫文件需要我们去创建 创建方式如下:
scrapy genspider 爬虫名称 域名
这时就生成了一个爬虫文件
标签:生成 需要 技术分享 速度 href 文件 内容 新建 .com
原文地址:https://www.cnblogs.com/hy123456/p/9847570.html