标签:string 有助于 oca io性能 buffer缓冲区 取数据 因此 直接映射 了解
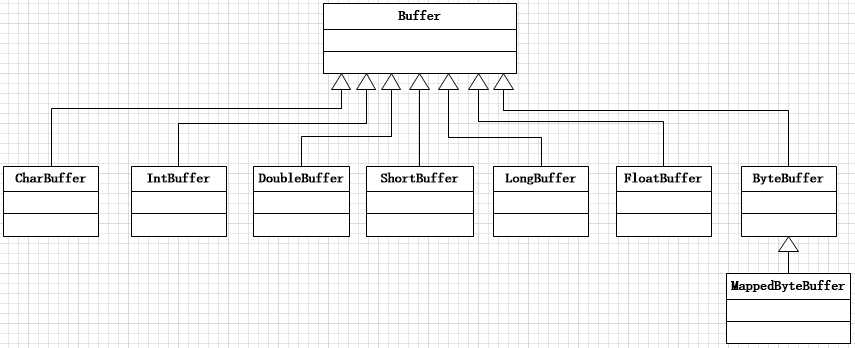
缓冲区就是固定数量数据的容器,其作用是一个存储器,或者分段运输区,在这里数据可被存储并在之后用于检索。缓冲区像上一篇文章I/O 模型那样被写满和释放,对于每个非布尔原始数据类型都有一个缓冲区类,尽管缓冲区作用于它们存储的原始数据类型,但缓冲区十分倾向于处理字节,非字节缓冲区可以在后台从字节或者到字节的转换,这取决于缓冲区如何创建的。所有的缓冲区都是Buffer抽象类的子类。
缓冲区的工作与通道紧密联系。通道是I/O传输发生时的入口,而缓冲区是这些数据传输的来源或者目标。也就是说数据总是从缓冲区写入到通道中,或者从通道读取数据到缓冲区。
指缓冲区能够容纳的数据元素的最大数量,这一容量在缓冲区创建时被设定,且不能够被改变。
指缓冲区的第一个不能被读写的元素数组下标索引,也可以认为缓冲区中实际元素的数量。
指下一个要被读或写的元素索引,该值会随着get()或put()调用自动更新。
指一个备忘位置,调用mark()来设定mark = position,调用reset()来设定position = mark,标记未设定前是未定义的(也就是说调用mark()方法的话,mark值将存储当前position的值,等下次调用reset()方法时,会设定position的值为之前的标记值)。
这四个属性总是遵循以下的关系:0 <= mark <= position <= limit <= capacity。
通过查看ByteBuffer的equals源码就能了解到是如何比较的:
1 public boolean equals(Object ob) { 2 if (this == ob) 3 return true; 4 if (!(ob instanceof ByteBuffer)) 5 return false; 6 ByteBuffer that = (ByteBuffer)ob; 7 if (this.remaining() != that.remaining()) 8 return false; 9 int p = this.position(); 10 for (int i = this.limit() - 1, j = that.limit() - 1; i >= p; i--, j--) 11 if (!equals(this.get(i), that.get(j))) 12 return false; 13 return true; 14 }
1.两个对象类型相同。包含不同数据类型的buffer永远不会相等,而且buffer对象绝不会等于非buffer对象。
2.两个对象都剩余同样数量的元素。buffer的容量不需要相同,而且缓冲区中剩余数据的索引也不必相同。但每个缓冲区中剩余元素的数目(从位置到上界)必须相同。
3.在每个缓冲区中应被get()方法返回的剩余数据序列必须一致。
缓冲区设计的目的就是为了高效的传输数据。一次移动一个数据元素,这种方式并不高效,Buffer API提供了向缓冲区内外批量移动数据元素的函数:
public abstract class CharBuffer extends Buffer implements Comparable<CharBuffer>, Appendable, CharSequence, Readable { ... public CharBuffer get(char[] dst){...} public CharBuffer get(char[] dst, int offset, int length){...} public final CharBuffer put(char[] src){...} public CharBuffer put(char[] src, int offset, int length){...} public CharBuffer put(CharBuffer src){...} public final CharBuffer put(String src){...} public CharBuffer put(String src, int start, int end){...} ... }
其实这种批量移动的合成效果和上一篇文章的循环底层实现上是一样的,但是这些方法可能高效很多,因为这种缓冲区实现能够利用本地代码或其他的优化来移动数据。
非直接缓冲区通过allocate(int capacity)创建:
static ByteBuffer allocate(int capacity)
我们之前说过NIO是利用通道来连接硬件磁盘或者应用程序的,缓冲区充当中间件来存储数据并通过缓冲区进行双向的数据传输。(借图,侵删)
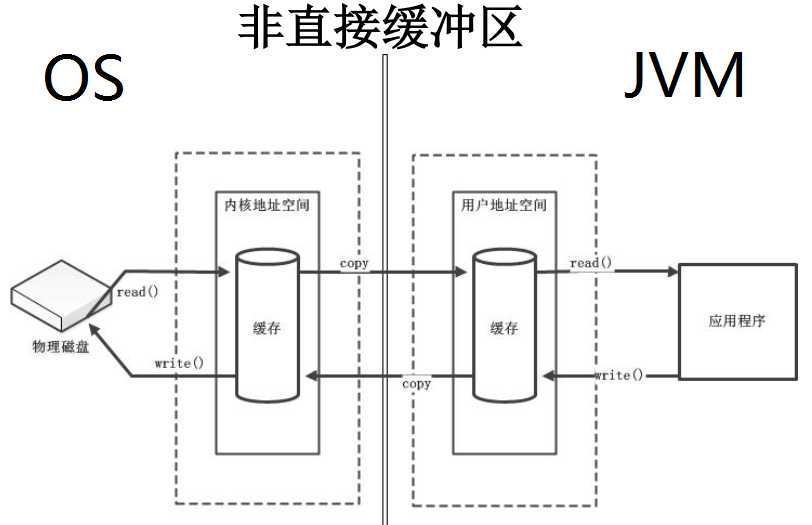
通过allocate(int capacity)创建的缓冲区是在JVM内存中创建的,由于磁盘的存取是由操作系统进行管理的,所以对于磁盘来说存取的数据只能来源于内核空间,而JVM内存缓冲区是在用户空间的,所以造成了数据会在操作系统和JVM之间来回拷贝,所以对NIO性能也有影响;同时用户空间的缓冲区在JVM内,销毁来说还很容易,但也占用了JVM内存的开销,所以对JVM的性能也有一定的影响。
非直接缓冲区的写入步骤:
1.创建一个临时的直接的ByteBuffer缓冲区对象;
2.将非直接缓冲区的数据复制到创建的临时缓冲区中;
3.在临时缓冲区中执行底层的I/O操作;
4.操作完成后,临时缓冲区的数据成为无用的等待被回收的数据。
直接缓冲区通过allocateDirect(int capacity)创建:
static ByteBuffer allocateDirect(int capacity)
直接缓冲区不再通过内核空间和用户空间复制来传递数据,而是在物理内存中申请了一块空间,这块空间能映射到内核空间和用户空间,所以应用程序和磁盘之间的数据存取可以通过这块直接申请的物理空间进行。(借图,侵删)
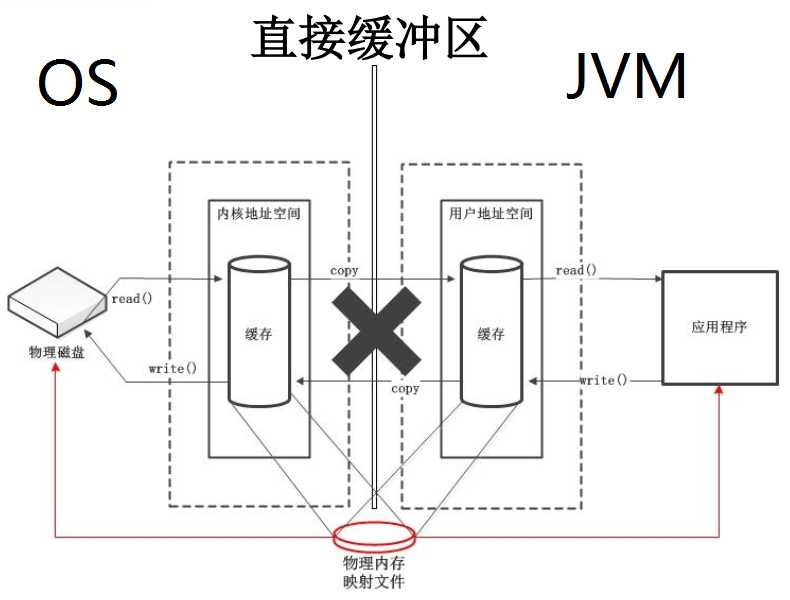
由于创建的缓冲区是在物理内存中,会少一次的复制过程,这使得JVM可以进行很高效的I/O操作,但由于使用的内存是由操作系统分配的,绕过了JVM的内存,所以直接缓冲区的建立和销毁需要比在JVM上建立和销毁缓冲区需要更大的开销。
? 字节缓冲区要么是直接的,要么是非直接的。如果为直接字节缓冲区,则Java虚拟机会尽最大的努力直接在此缓冲区上执行本机I/O操作,也就是说,在每次调用操作系统基础的一个本机I/O操作前后,虚拟机都会尽量避免将缓冲区的内容复制到中间缓冲区中(或从中间缓冲区中复制内容到缓冲区)。
? 直接字节缓冲区可以通过调用此类的allocateDirect(int capacity)工厂方法来创建,此方法返回的缓冲区进行分配和取消分配所需要的成本通常高于非直接缓冲区。直接缓冲区的内容可以驻留在常规的垃圾回收堆之外,因此,它们对应用程序的内存需求量造成的影响并不明显。所以,建议将直接缓冲区主要分配给那些易受基础系统的本机I/O操作影响的大型、持久的缓冲区。一般情况下,最好仅在直接缓冲区能在程序性能方面带来明显好处的时候分配它们。
? 直接字节缓冲区还可以通过FileChannel的map()方法将文件区域直接映射到内存中来创建。该方法返回MappedByteBuffer。Java平台的实现有助于通过JNI从本机代码创建直接字节缓冲区。如果以上这些缓冲区中的某个缓冲区实例指的是不可访问的内存区域,则试图访问该区域不会更改该缓冲区的内容,并且会在访问期间或者稍后的某个时间抛出不确定的异常。
? 字节缓冲区是直接缓冲区还是非直接缓冲区可通过调用isDirect()方法来确定。提供此方法是为了能够在性能关键型代码中执行显式缓冲区管理。
1.不安全
2.消耗更多,因为它不是在JVM中直接开辟空间,这部分的内存回收就只能依赖于垃圾回收机制,垃圾什么时候回收不受我们控制。
3.数据写入物理内存缓冲区中,程序就丧失了对这些数据的管理,即什么时候这些数据最终写入磁盘只能由操作系统来决定,应用程序无法干涉。
直接缓冲区在数据需要长时间存于内存,或者大数据量的操作时更加合适。
参考: https://my.oschina.net/happyBKs/blog/1592329 https://www.cnblogs.com/xrq730/p/5074558.html
标签:string 有助于 oca io性能 buffer缓冲区 取数据 因此 直接映射 了解
原文地址:https://www.cnblogs.com/Joe-Go/p/9848395.html