标签:大小 lin 最大 依据 博客 开始 center nbsp sig
1.有DNN做的word2vec,取隐藏层到softmax层的权重为词向量,softmax层的叶子节点数为词汇表大小
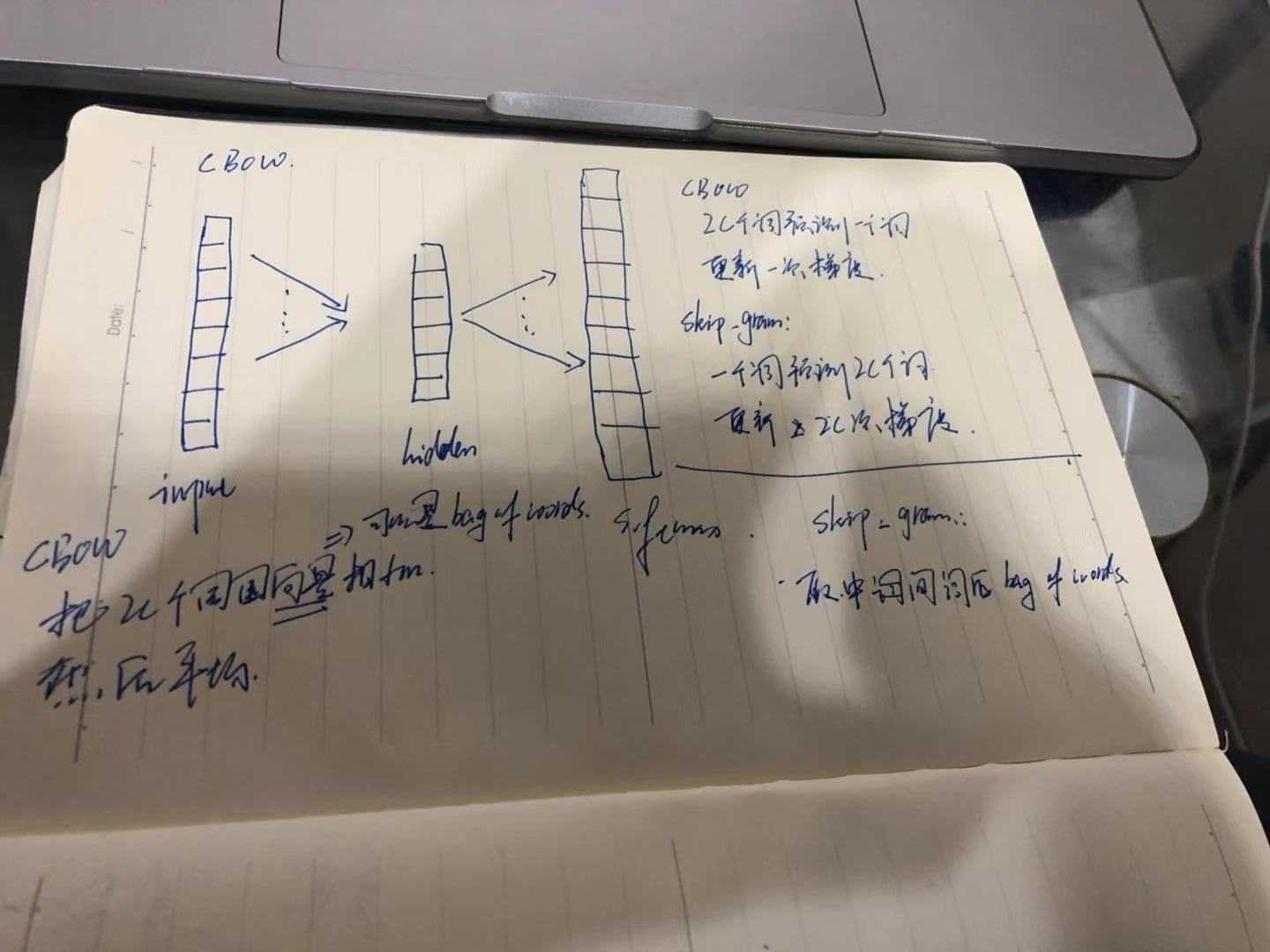
2-3的最开始的词向量是随机初始化的
2.哈夫曼树:左边走 sigmoid(当前节点的词向量*当前节点的参数) 右边走 1-sigmoid(当前节点的词向量*当前节点的参数),叶子节点为词汇表所有词,然后求根节点到叶子节点的极大似然估计,在Skip gram中,词向量也是更新2c个词
3.negative sampling: 负采样,CBOW采样的是2c个词的平均向量,而Skip gram采样的是中心词的向量;这些都叫做正例,采样不是依据正例子来采样的,而是依据特定的方法
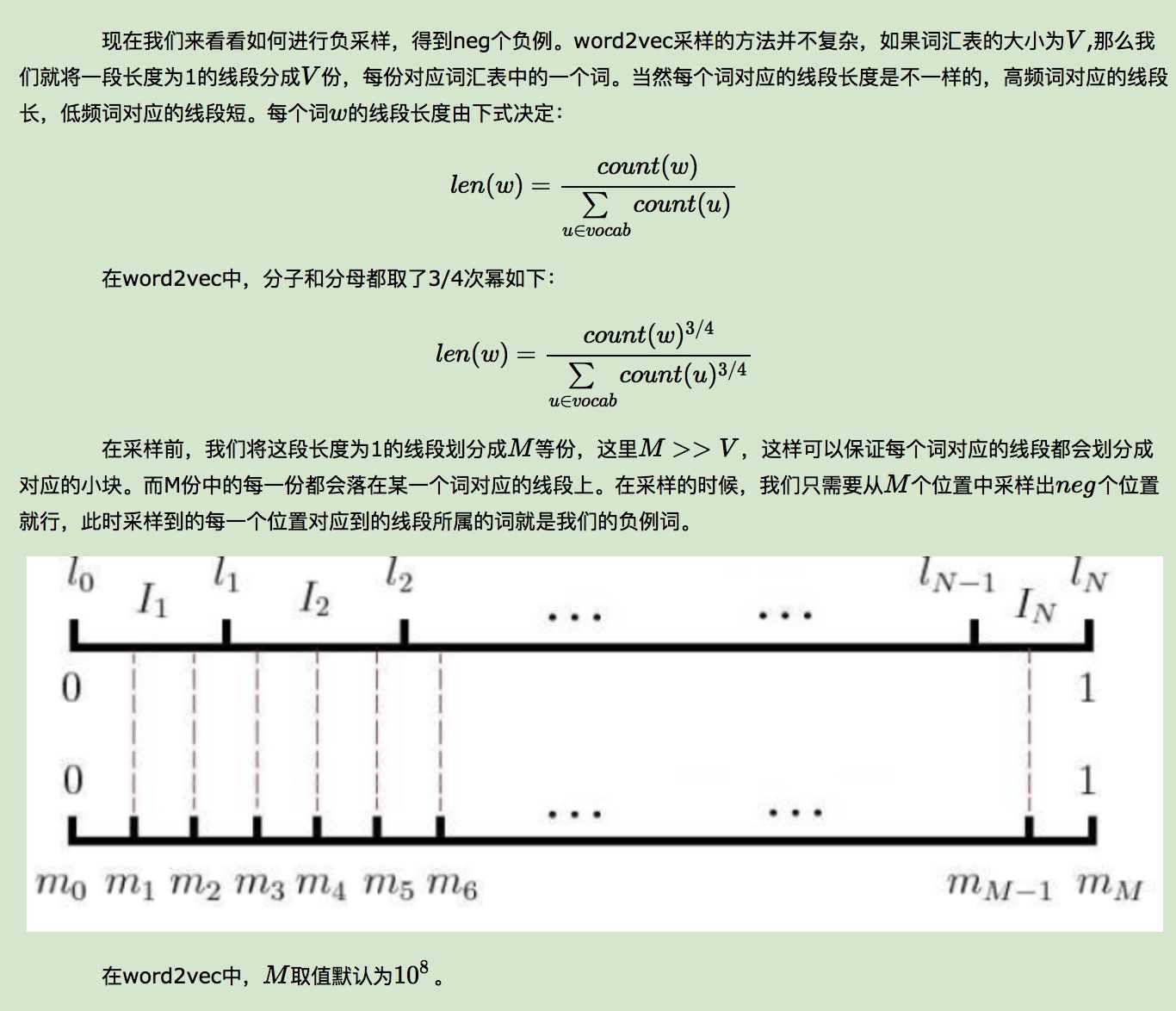
采样中心词的负例,然后最大化正例与(1-负例)的似然,既:sigmoid(w正*参数正)*[(1-sigmoid(w负*参数负)) neg个负例相乘]
参考博客地址:http://www.cnblogs.com/pinard/p/7160330.html
标签:大小 lin 最大 依据 博客 开始 center nbsp sig
原文地址:https://www.cnblogs.com/callyblog/p/9851732.html