标签:分配 动作 收集 循环 tree obs new time() 文件
1.观察者模式
观察者模式(有时又被称为模型-视图(View)模式、源-收听者(Listener)模式或从属者模式)是软件设计模式的一种。在此种模式中,一个目标物件管理所有相依于它的观察者物件,并且在它本身的状态改变时主动发出通知。这通常透过呼叫各观察者所提供的方法来实现。此种模式通常被用来实现事件处理系统。
观察者模式(Observer)完美的将观察者和被观察的对象分离开。举个例子,用户界面可以作为一个观察者,业务数据是被观察者,用户界面观察业务数据的变化,发现数据变化后,就显示在界面上。面向对象设计的一个原则是:系统中的每个类将重点放在某一个功能上,而不是其他方面。一个对象只做一件事情,并且将他做好。观察者模式在模块之间划定了清晰的界限,提高了应用程序的可维护性和重用性。观察者设计模式定义了对象间的一种一对多的组合关系,以便一个对象的状态发生变化时,所有依赖于它的对象都得到通知并自动刷新。
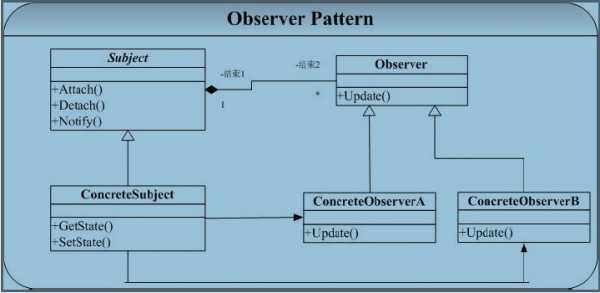
2.观察者模式的结构(以clawer_news为例)
https://github.com/Kelang-Tian/clawer_news
该代码为本人所写,项目功能是从网易新闻网站上自动爬取财经新闻并存储到mongo数据库中。
采取分布式结构爬取数据,server负责分发详细的所需要获得内容的新闻url给client,client收到URL后自动分析网页内容并将收集的信息存储到数据库中。Server起到了监控client动作并控制的功能,相当于观察者的位置。文件中的tasklist是用来进行新闻网站URL的管理与存储,也是被server进行监控与管理。
Server实现:
from selenium import webdriver
from tasklist import TaskList
import time
import socket
import requests
from bs4 import BeautifulSoup
import traceback
import re
def main():
addr = "0.0.0.0"
port = 9992
main_url = "http://money.163.com/special/00252C1E/gjcj.html"
task_list = TaskList(timeout=30)
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind((addr, port))
sock.listen(50)
#driver = webdriver.Chrome()
#driver.get(main_url)
print("正在从网页中解析URL链接...")
def gethtmltext(url, code="gbk"):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = code
return r.text
except requests.exceptions.ConnectionError:
return ""
html = gethtmltext(main_url)
try:
if html == "":
print("---html error1!---")
soup = BeautifulSoup(html, ‘html.parser‘)
url_info = soup.find_all(‘div‘, attrs={‘class‘: ‘list_item clearfix‘})
news_url = list()
for i in url_info:
# noinspection PyBroadException
try:
a = i.find(name=‘h2‘)
url = a.find(name=‘a‘).attrs[‘href‘]
news_url.append(url)
print(url)
except:
continue
task_list.put_tasks(news_url)
except:
print("---url error2!---")
# driver.close()
print("等待client中.......")
while 1:
if task_list.is_empty():
print("====任务完成====")
sock.close()
break
conn, addr = sock.accept() # 接受TCP连接,并返回新的套接字与IP地址
print(‘Connected by\n‘, addr, conn) # 输出客户端的IP地址
try:
data = conn.recv(1024).decode("gbk")
if data.split(‘,‘)[0] == "get":
client_id = data.split(‘,‘)[1]
task_url = task_list.get_task()
print("向client {0} 分配{1}".format(client_id, task_url))
conn.send(task_url.encode("gbk"))
elif data.split(‘,‘)[0] == "done":
client_id = data.split(‘,‘)[1]
client_url = data.split(‘,‘)[2]
print("client {0}‘ 完成爬取{1}".format(client_id, client_url))
task_list.done_task(client_url)
conn.send("ok".encode("gbk"))
except socket.timeout:
print("Timeout!")
conn.close() # 关闭连接
if __name__ == ‘__main__‘:
main()
client实现:
from selenium import webdriver
#from selenium import exceptions
import pymongo
import socket
import time
import requests
from bs4 import BeautifulSoup
import traceback
import re
__HOST_ADDR__ = "127.0.0.1"
__HOST_PORT__ = 9992
__DB_ADDR__ = "127.0.0.1"
__DB_PORT__ = 27017
client_id = int(time.time())
mongo_client = pymongo.MongoClient("mongodb://{0}:{1}/".format(__DB_ADDR__, __DB_PORT__))
mongo_db = mongo_client["News"]
mongo_col = mongo_db["NewsWangyi"]
#driver = webdriver.Chrome()
def getinfo(newsURL, path1, path2, attr):
html = gethtmltext(newsURL)
try:
soup = BeautifulSoup(html, ‘html.parser‘)
info = soup.find(path1, attrs={path2: attr})
return info
except:
return ""
def gethtmltext(url, code="gbk"):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = code
return r.text
except requests.exceptions.ConnectionError:
return ""
while 1:
try:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((__HOST_ADDR__, __HOST_PORT__))
req = "get,{0}".format(client_id)
sock.send(req.encode("gbk"))
res = sock.recv(1024)
sock.close()
task_url = res.decode("gbk")
#try:
# driver.get(task_url)
#except:
# break
#selector = etree.HTML(driver.page_source)
print("---working with---:", task_url)
text = {
"title": getinfo(task_url, "div", "class", "post_content_main").string,
"time": getinfo(task_url, "div", "class", "post_time_source").text.split()[0],
"author": getinfo(task_url, "a", "id", "ne_article_source").string,
"content": ""
}
text_content = getinfo(task_url, "div", "class", "post_text").get_text()
for line in text_content:
if line.isspace():
continue
text["content"] += (line.lstrip())
#if mongo_col.find_one({"title": text["title"]}) is None:
mongo_col.insert_one(text)
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((__HOST_ADDR__, __HOST_PORT__))
req = "done,{0},{1}".format(client_id, task_url)
sock.send(req.encode("gbk"))
except socket.error:
print("Connection error")
time.sleep(5)
tasklist的实现:
import time
import threading
class TaskList:
__timestamp__ = None
__timeout__ = None
__tasks_undo__ = None
__tasks_pending__ = None
__lock__ = None
def __init__(self, timeout=5):
self.__tasks_undo__ = list()
self.__tasks_pending__ = list()
self.__timeout__ = timeout
self.__lock__ = threading.Lock()
self.__update_timestamp__()
def set_timeout(self, timeout):
self.__lock__.acquire()
self.__check_timeout__()
self.__timeout__ = timeout
self.__update_timestamp__()
self.__lock__.release()
def put_tasks(self, tasks):
self.__lock__.acquire()
self.__check_timeout__()
self.__tasks_undo__.extend(tasks)
self.__update_timestamp__()
self.__lock__.release()
def get_task(self):
self.__lock__.acquire()
self.__check_timeout__()
if len(self.__tasks_undo__) == 0:
return None
task = self.__tasks_undo__.pop()
self.__tasks_pending__.append(task)
self.__update_timestamp__()
self.__lock__.release()
return task
def done_task(self, task):
self.__lock__.acquire()
self.__check_timeout__()
self.__tasks_pending__.remove(task)
self.__update_timestamp__()
self.__lock__.release()
def is_empty(self):
self.__lock__.acquire()
self.__check_timeout__()
ret = (len(self.__tasks_undo__) + len(self.__tasks_pending__) == 0)
self.__lock__.release()
return ret
def __update_timestamp__(self):
self.__timestamp__ = int(time.time())
def __check_timeout__(self):
cur_time = int(time.time())
if cur_time > self.__timestamp__ + self.__timeout__:
self.__tasks_undo__.extend(self.__tasks_pending__)
self.__tasks_pending__.clear()
3.观察者模式的优缺点
1、优点
1、解耦,被观察者只知道观察者列表「抽象接口」,被观察者不知道具体的观察者
2、被观察者发送通知,所有注册的观察者都会收到信息「可以实现广播机制」
2、缺点
1、如果观察者非常多的话,那么所有的观察者收到被观察者发送的通知会耗时
2、观察者知道被观察者发送通知了,但是观察者不知道所观察的对象具体是如何发生变化的
3、如果被观察者有循环依赖的话,那么被观察者发送通知会使观察者循环调用,会导致系统崩溃
标签:分配 动作 收集 循环 tree obs new time() 文件
原文地址:https://www.cnblogs.com/USTC-18/p/9854519.html