标签:定义数据 被集成 收集 质数 dfs 提取 完成 组织 监视
大数据项目由业务驱动,一套完整且优秀的大数据解决方案对企业的发展具有战略性意义。
由于数据来源多样,导致来自不同数据源的数据类型、规模等具有不同的特征。在处理分析大数据时,将涉及到更多维度(治理、安全等)。
因此在采用大数据分析前,需对项目的整个管理流程和决策框架提前考虑。需要考虑到的内容主要有:
1.先决条件
优质数据、完善的流程、优秀的员工、预设持续周期。
2.数据获取来源
考虑来自所有渠道(内部和外部)、所有可用于分析的数据,同时包括数据格式、收集方式、规模等。
主要来源包括:企业内部(系统、数据管理系统DMS等)、企业外部(公开数据和商业数据)。
数据管理系统DMS——存储逻辑数据、流程、策略和各种其他类型的文档。
3.数据隐私管理
保护敏感数据,制定相应的数据屏蔽(标记化、匿名化)和存储措施。
4.数据安全
考虑使用用户认证、授权机制以保证数据库管理系统的安全。
非关系型数据库通过使用明文通信的API进行数据交换,缺乏安全性。
API(Application Programming Interface)——应用程序编程接口,实现计算机软件之间的相互通讯。可通过Postman工具进行调取。
5.元数据
大数据在生命周期的不同分析过程中,可能因传输、加工和存储而处于不同的状态。这些改变自动触发元数据的生成,后续可作为对结果进行溯源的依据,同时保证数据的准确、可靠性。因此需要一个框架来保存元数据。
6.时效性
不同业务对时效性的要求不同。由此分为批处理、流处理两种处理方式。
不同的处理方式有不同的平台、硬件支持(例:Storm-免费开源的分布式流处理计算系统,Hadoop-免费开源的分布式批处理计算系统)。
7.硬件性能
由于数据量大,数据查询和传输时间可能过长,因此需对相关硬件设施进行升级。
8.数据管理框架
在将数据传入企业进行处理、存储、分析、清除、存储时,同时制定监视、构建、存储和保护数据的流程和方针,有助于解决数据复杂性等问题。
数据管理框架还考虑以下内容:
9.建立反馈循环机制
考虑建立适当的反馈循环机制,以优化分析步骤,获得更准确的分析结果。
10.存储、计算环境
提供了多个数据存储选项,比如云、关系型数据库、非关系型数据库、分布式文件存储 (DFS)等。
但一般大数据环境都会全部/部分采用基于云的托管。
当所有前期准备已做好时,即可着手开始解决实际业务。
针对具体项目,由于大数据与传统数据的差异,大数据分析具有多样性的需求,因此其具有独特的生命周期,可分为9个阶段:
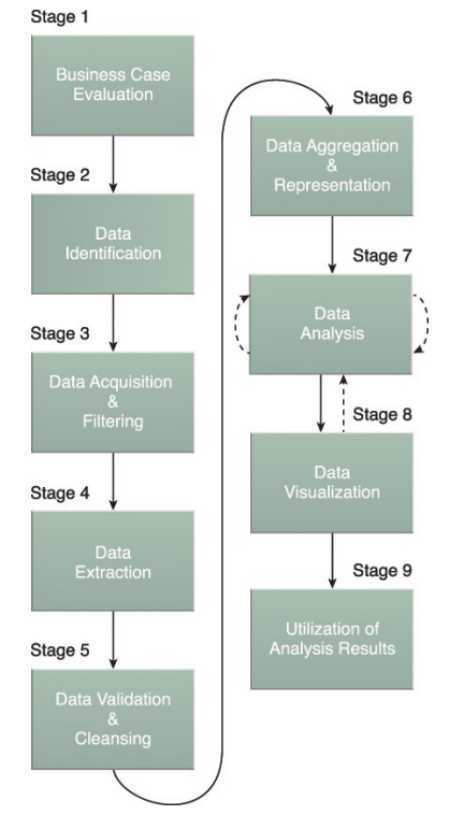
图1 大数据分析的生命周期
1.案例评估:
“SMART”化 + 判断是否为大数据问题(依据5V特征) + 评估预算和收益。
2.数据标识:
尽可能找到不同类型的相关数据集,试图从中发现隐藏信息。
3.数据获取、过滤
对获取的数据进行归类,并过滤“腐坏”数据,过滤前对数据进行备份、压缩。
“腐坏数据”包括:遗失/无意义值/空值等非结构或不相关类型。
4.数据提取
查询提取出分析所需数据。同时,根据分析类型和大数据解决方案能力,将数据修改为需要的格式。
目前主要的挑战是将非结构化数据格式(XML、Json等)转化为便于分析的数据格式。
5.验证、清洗
通过冗余数据集,整合验证字段、填充缺失数据、移除已知的无效数据,以此检验具有关联的数据集。(看似无效的数据可能蕴含某种隐藏规律,例:离群值可用于研究风险)
批处理的数据验证清洗过程在离线ELT系统中进行,流处理在复杂的内存中进行。
6.数据集成与表示
将不同来源、格式的数据,依逻辑上或物理上进行集成,并通过一个视图(二维表等)表示出来的过程。同时,对部分集成数据进行存储,以备后续数据分析使用。
数据集成包括两个层次——形式上的数据集成、语义上的数据集成。
7.数据分析
通过不同的分析方法,试图从数据中提取业务洞察。
数据分析方法可分为:描述性分析、验证性分析(假设→检验)、探索性分析(归纳法)。
同时建立适当的迭代方式,重复多次分析,以提高分析出可靠结果的可能性。
8.数据可视化
针对不同使用场景,使用不同的可视化技术,将分析结果通过图形进行展示。以便于专业分析人员与用户进行交流,同时使用户发现潜在答案成为可能。
9.分析结果的应用
使用分析层的输出结果,使用者可能是可视化应用程序、人(决策者)或某项业务流程。
当已经决定构建 新的/更新现有的 大数据解决方案,下一步是识别大数据解决方案所需的组件,主要可从以下两个视角来考虑。
1.大数据解决方案的逻辑层:
逻辑层提供了一种组织相关组件的方式,其中不同的组件执行不同的功能。
这些层只是逻辑层,并不意味着支持每层的功能独立运作,相反各层之间联系紧密,数据在各层之间流动。
大数据解决方案通常由以下逻辑层组成:
2.垂直层:
影响逻辑层中所有组件的各方面都包含在垂直层中,垂直层包括以下几层:
逻辑层和垂直层的组件及关系参考下图。
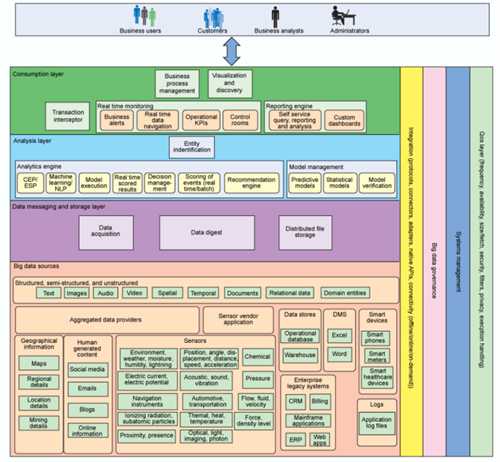
图2 逻辑层和垂直层的组件
标签:定义数据 被集成 收集 质数 dfs 提取 完成 组织 监视
原文地址:https://www.cnblogs.com/NovemberRain/p/9858499.html