标签:就是 参数 表示 区间 jsb 变化 blog size 目标
监督学习可以看做最小化下面的目标函数:
L1正则化和L2正则化可以看做是损失函数的惩罚项,对损失函数中的某些参数做一些限制
第1项为经验风险,即模型f(x)关于训练数据集的平均损失;
第2项为正则化项,去约束我们的模型更加简单
(L1范数让W等于0,L2范数让W都接近于0,越小的参数说明模型越简单,越不容易产生过拟合的现象)
L1正则化: L1范数是指向量中各个元素绝对值之和。
L1正则化可以产生稀疏模型,用于特征选择:
稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0。
通常机器学习中特征数量很多,如果代入这些特征得到的模型是一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小此 时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。
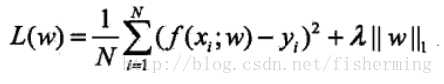
L2正则化:L2范数是指向量各元素的平方和然后再求平方根。
L2正则化可以防止模型过拟合(overfitting)
过拟合的时候,拟合函数的系数往往非常大
过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。
这就意味着函数在某些小区间里的导数值(绝对值)非常大
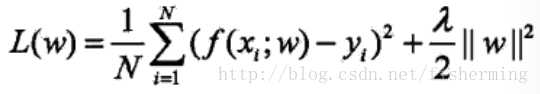
标签:就是 参数 表示 区间 jsb 变化 blog size 目标
原文地址:https://www.cnblogs.com/hapyygril/p/9870707.html
