标签:等等 部分 文档 正则表达 队列 集合 哈哈哈 不可 agent
我们先看看维基百科的定义
通俗的说爬虫就是通过一定的规则策略,自动抓取、下载互联网上网页,在按照某些规则算法对这些网页进行数据抽取、 索引。 像百度、谷歌、今日头条、包括各类新闻站都是通过爬虫来抓取数据。

题外话
博客园里偶尔看到爬虫的文章,其实很多都称不上为爬虫。 只能叫玩具或者叫http请求下载程序吧。。 严格来说爬虫是一个系统,它包含了爬取策略、更新策略、队列、排重、存储模块等部分。
按照抓取网站对象来分类,可以分为2类爬虫。
类似百度、谷歌这样的爬虫,抓取对象是整个互联网,对于网页没有固定的抽取规则。 对于所有网页都是一套通用的处理方法。
这类爬虫主要针对一些特定对象、网站,有一台指定的爬取路径、数据抽取规则。比如今日头条,它的目标网站就是所有的新闻类网站。 比如Etao比价、网易的慧慧购物助手,他们的目标网站就是 淘宝、京东、天猫等等电商网站。
通用爬虫和垂直爬虫显著的区别:
那么一个完整的爬虫程序由哪些东西组成呢?
顾名思义就是负责HTTP下载,别小瞧它,要做好还挺不容易,因为你面对的复杂而无序、甚至包含错误的互联网。
就是存储新产生的URL队列(queue),队列可以是多种形式的,他可以是redis的队列、数据库中的表、内存中的队列。根据场景,你可以自行选择。
调度嘛,就是负责管理工作的,它通过制定策略,规定哪些URL优先执行、哪些URL靠后。
对我来说,一个爬虫必须要支持多线程,并且可控。
排重,这是一个爬虫必不可少的部分,你必须记录下哪些URL已经采集过、哪些是未采集过的,复杂点的爬虫,你可能还需要记录上次抓取时间。
就是定义如何解析抓取到的页面,对于通用爬虫,它可能对于所有页面都是一套逻辑,就是分词、索引。 但对于垂直爬虫,则需要指定规则。手段可能有正则、XPath、正文识别等等。
定义以什么方式存储抓取到的数据, 一般情况下都是存储到数据库啦。当然,是一般的关系数据库,还是NoSQL 就看需求了。
通用爬虫、垂直爬虫他们的流程都是相似的,下面我们简单说说一个爬虫到底是怎么运行的。
首先,我们用一张一般爬虫的流程结构图来看看。
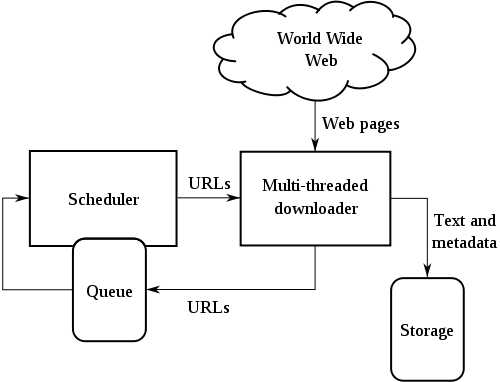
英文我就不翻译了。 大概说说流程吧。
这里列举一些比较有名的爬虫项目,有些我用过,有些没用过。我平时工作环境是 .net ,对python爬虫也略有研究。
Scrapy 额外点评, 在我大概读了下它的源码后,我觉得 Scrapy 在一些地方还是很不错的,比如回调模型。 但是它太臃肿了。对于一个垂直爬虫框架来说的,有很多不必要的设计,比如下载器、中间件。
暂且就列这几个, 欢迎各位同学补充!
主要的包括GET、POST方法。 各种类型Header的了解 ,包括Referer、User-Agent、Cookie、Accept、Encoding、Content-Type等等。
了解各种HTTP状态码的含义,常见的状态码比如 200表示正常; 301表示重定向,同时会返回新的URL;404表示页面不存在;5xx表示服务器端错误
了解Cookie的构成,原理。
HTML基础知识,了解HTML常用元素, 比如A、IMG等等。
了解URL的构成,路径、参数,绝对路径、相对路径。
编码相关,HTML charset, HTML Encode\Decode,URL Encode\Decode,JS Encode\Decode,
HTTP协议、HTML其实都是浏览器相关的
了解浏览器,从你输入一个URL,到看到完整的网页,中间发生了什么。相关知识点: URL、DNS、HTTP、Web Server、HTML、JS、CSS、DOM树、JS引擎等等。
其中DOM树、JavaScript相关知识对于爬虫来说还是相当重要的。有些时候需要反解JS。
常用抓包工具,比如Fiddler、浏览器的F12、Wireshark、Microsoft Network Monitor。后面2个属于TCP级别,用的较少。
通过学习抓包工具使用,可以帮你更好的学习HTTP协议、浏览器相关知识。
这里强烈、重点推荐 Fiddler。
大概说下几个常用功能吧, 抓包、保存包数据、Composer(构造HTTP请求)、AutoResponser(自动响应HTTP)、FidderScript 通过编写脚本定制程序、修改HTTP包。
如果你是 .net 技术相关的,建议反编译下,读下源代码,HTTP协议你就搞定啦。它还提供了 FiddlerCore 库让你可以编写自己抓包程序。
有爬虫,当然就有反爬虫技术啦。 他们俩一直处于一个对抗、共存的状态。 这是一个非常有意思的过程,对于一些爬虫从业、爱好者来说。
通常来说,只要你想爬,没有爬取不到的数据,就看你的资源和技术了。 不论是网站还是APP。
下面列举下常见几种反爬虫技术:
没关系,虽然反爬技术多,但是只是增加你的成本而已。 不过网站也是有代价的,有些反爬会损害用户体验的。
有意思的事情:
许多大的互联网公司,会同时有爬虫部门和反爬虫部门。哈哈哈,是这样的,爬虫部门用来爬别人家的数据, 反爬部门用来屏蔽别人家的爬虫咯! 举个例子,就像之前的58和赶集(不过现在他们合并了)
有意思的项目:
一步采集 通过算法,计算出一个网页中列表、分页地址。类似于 正文识别 算法。
这个技术对于需要做大量垂直爬虫的人来说,就很有用图。不用再编写XPath、正则表达式。
转自:https://www.cnblogs.com/pspider/p/7040681.html
标签:等等 部分 文档 正则表达 队列 集合 哈哈哈 不可 agent
原文地址:https://www.cnblogs.com/zhangmingcheng/p/9876518.html