标签:思想 most 分享图片 变量 并且 介绍 分类 关于 理解
我们先回想一下之前经常处理的问题,我们常常是在给定这样一组模式的情况下:
$$({x_1},{y_1}),...,({x_n},{y_n}) \in X \times Y$$
寻找这样一个映射:
$$f:X \to Y$$
但是我们注意到,在各种回归和分类问题中,我们常常认为Y=R,也即是响应变量为标量,但是我们应该注意到,我们在学习过程中,往往还要面对另一类很重要的问题,需要我们通过模型得到结构化的y,例如,我们在进行自然语言处理的时候,我们在输入一个句子(x),我们可能希望得到一个解析树(y),显然,这是我们之前的模型所无法处理的,因此我们引入了结构化学习(Structured Learning)。
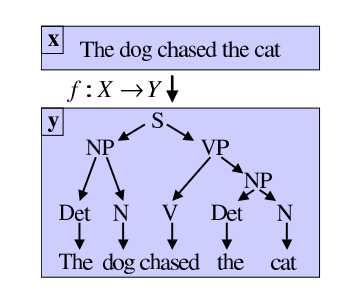
在介绍怎么解决这一类问题之前,让我先绕一点儿弯路,想一下另一个问题:我们在进行网络检索的时候,我们常常需要需要考虑一个问题,当我们获取到检索相关的文档之后,我们需要对文档做一定的顺序排列返回给用户,原因很简单,放在前面的文档显然更加占便宜,容易被用户关注到。
考虑直接将排序问题转化为以查询-文档为训练样本的分类或者回归问题:
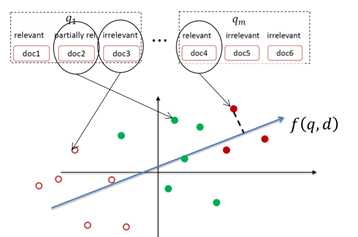
但是我们注意到,这样的建模方法所进行的样本训练是跨查询进行的,而这些查询中由于对文档的重要性标注有不同的数量级差异,而这种差异会导致我们在训练时学习到不必要的特性,从而干扰模型的效果。
进一步,我们注意到我们在进行排序的时候,只需要考虑在同一个查询中的文档相对分值大小,因此不会跨查询进行:
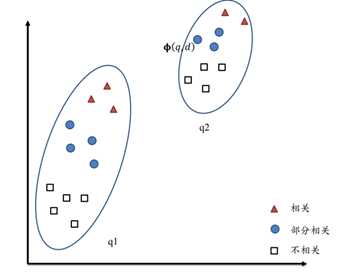
因此我们考虑充分利用这种特性获得更好性能的模型。
给定训练数据:
$$D = \{ {D_{qi}}\} _{i = 1}^N,{D_{qi}} = \{ ({d_{ij}},{y_{ij}})\} _{j = 1}^{{M_i}}$$
分别对应查询集合和查询的文档集合。
对于每一个查询-文档对都建立特征向量$\phi (q,d)$
将其参数化,不妨设:
$$f(q,d) = \left\langle {w,\phi (q,d)} \right\rangle $$
对于文档di和文档dj,我们都可以一组序偶对:
$$\left( {\phi (q,di) - \phi (q,di),z} \right),z = \left\{ {\matrix{
{ + 1,{d_i} > {d_j}} \cr
{ - 1,{d_i} < {d_j}} \cr
} } \right.$$
考虑到正负样本是对称的,因此我们也只需要其中的一半样本就可以了。
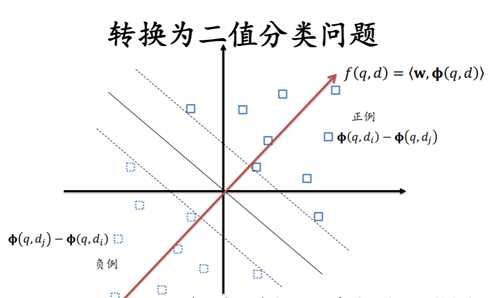
我们可以使用任何分类模型解决上面的问题,比如SVM,于是就是Ranking SVM。
回到我们的主题,我们首先定义一个判别函数,这个函数表明了输入与输出的一个匹配程度,这是一个很显然的转化,因为这个是我们所能解决的标量问题,因此,我们定义一个如下的映射:
$${F_{dis}}:X \times Y \to R$$
如果我们进一步,考虑一组定义出来的“规则特征”$\psi (x,y)$ ,考虑因为参数向量对其进行参数化,不失一般性,我们考虑其为参数向量与特征规则的内积:
$$F(x,y;w) = < w,\psi (x,y) > $$
然后,我们注意到,我们已经建立了一个求解目标,对于任何的输入x,我们希望找到:
$$\hat y = \mathop {\arg \max }\limits_{y \in Y} F(x,y;w)$$
因此,这个问题也被转化为一个二分类问题,我们得到如下样本点:
$$\forall y \in Y\backslash {y_i},(\psi ({x_i},{y_i}) - \psi ({x_i},y), + 1)$$
$$\forall y \in Y\backslash {y_i},(\psi ({x_i},y) - \psi ({x_i},{y_i}), - 1)$$
在解决模型的时候,我们毫无例外地,需要定义一个优化方向,我们按照机器学习的一般方法,首先定义损失函数:
对于一个给定的样本(xi,yi),我们可以借鉴上面的Ranking SVM思想,由于我们在进行模型推断的时候,我们并不需要跨xi进行,因此我们只需要比较得到相对大小即可,我们可以直观的获得一个损失函数:
$$E = \mathop {\max }\limits_{y \in Y} < w,\psi ({x_i},y) > - < w,\psi ({x_i},{y_i}) > $$
可能会有人有疑问,这个并不是我们常见的经验损失函数,我将在后面对这个问题进行解释,并且证明它们的同质性。
先占个坑,我们直观意义上的损失函数为:
$${E_{empirical}} = {1 \over n}\sum\limits_n {\Delta (\tilde y,y)} $$
我们考察上面的损失函数,我们注意到,尽管上面的函数是一个阶梯函数,但是我们在取定y的时候,依然可以对其进行求导:
$${{\partial E} \over {\partial w}} = \psi ({x_i},\tilde y) - \psi ({x_i},{y_i})$$
使用梯度下降法,我们可以得到:
$${w^{k + 1}} = {w^k} - \eta \nabla E = {w^k} - \eta (\psi ({x_i},\tilde y) - \psi ({x_i},{y_i}))$$
如果我们取学习率参数为1,那么我们就很轻易的获得:
$${w^{k + 1}} = {w^k} - \psi ({x_i},\tilde y) + \psi ({x_i},{y_i})$$
我们注意到,这恰好是感知机的迭代方式。
进一步,根据感知机收敛法则,这样的迭代式一定能够结束的,并且最大迭代次数:
$$k \le {R \over \sigma }$$
很庆幸,没有与|Y|扯上关系,那么这个问题的求解就是很简单的了。
从上面的感知机模型,我们一个很自然的想法就是,我们可不可以使用SVM对问题的解的形式做进一步的优化:
与SVM相似,如果我们提出约束:
$$\forall i \in \{ 1,2,3,...,n\} ,\forall y \in Y\backslash {y_i}$$
$$ < w,\psi ({x_i},{y_i}) > - < w,\psi ({x_i},y) > \ge 1$$
上面约束的意思也很明显,就是我们要求最佳的匹配要比其它的好出一个度。
此时我们的优化目标为:
$$\mathop {\min }\limits_w {1 \over 2}{\left\| w \right\|^2}$$
这与我们之前的SVM是完全一致的,但是值得一提的我们注意到Y空间的高维性会带来求解的困难。
进一步,如果我们引入松弛因子,我们有:
$$\mathop {\min }\limits_{w,{\xi _i}} {1 \over 2}{\left\| w \right\|^2} + {C \over n}\sum\limits_{i = 1}^n {{\xi _i}} $$
s.t.
$$ < w,\psi ({x_i},{y_i}) > - < w,\psi ({x_i},y) > \ge 1 - {\xi _i},\forall i \in \{ 1,2,3,...,n\} ,\forall y \in Y\backslash {y_i}$$
我们解到这一步的时候,可能都觉得会松了一口气,但是其实我们还忽略了另一个问题,也就是我们之前一直忽略的经验损失函数,我们仅仅考虑了两个模式的匹配程度,但是从一个角度讲,如果这两个结果在结构上是相似的,我是是不是就应该倾向于接受它;反之呢,我们是不是该选择抛弃它?

基于上面的做法,我们进一步引入惩罚因子——经验损失函数,直观的,我们可以将这个惩罚因子加在松弛因子上,那么其约束条件变为:
$$ < w,\psi ({x_i},{y_i}) > - < w,\psi ({x_i},y) > \ge 1 - {{{\xi _i}} \over {\Delta ({y_i},y)}},\forall i \in \{ 1,2,3,...,n\} ,\forall y \in Y\backslash {y_i}$$
也许你也能看出来,将这个惩罚因子加在第一个因子上也是合情合理的,此时,约束变为:
$$ < w,\psi ({x_i},{y_i}) > - < w,\psi ({x_i},y) > \ge \Delta ({y_i},y) - {\xi _i},\forall i \in \{ 1,2,3,...,n\} ,\forall y \in Y\backslash {y_i}$$
这两个并不是很难理解,进一步可以引出来我们下面对于损失函数的解释。
我们知道,在一般的SVM中,我们求得的合页损失函数是0-1损失函数的一个上界,但是structured svm还要更复杂一点。
回到我们上面关于slack re-scaling的公式,结合松弛因子的约束:
整理得:
$${\xi _i} = {\max _{y \ne {y_i}}}\{ 0,\max \Delta ({y_i},y)(1 - ( < w,\psi ({x_i},y) - < w,\psi ({x_i},{y_i}) > ))\} $$
我们可以分为两种情况进行讨论:
1.$< w,\psi ({x_i},y) > = < w,\psi ({x_i},{y_i}) > $
从而我们有:
$${\xi _i} \ge 0 = \Delta ({y_i},y)$$
2.不相等,即我们没有找到严丝合缝的match:
$${\xi _i} = \max \Delta ({y_i},y)(1 - ( < w,\psi ({x_i},y) - < w,\psi ({x_i},{y_i}) > )) \ge \Delta ({y_i},y)$$
从而我们得出结论:我们求出的损失函数是经验损失的一个上界(upper bound)。
对于margin re-scaling的证明不再赘述。
进一步,我们注意到对于结构化的输出,经验损失函数的定义是比较复杂的,此时我们很难对其进行求导等操作,因此我觉得这也算是一个权宜之计。
我们注意到在上面的优化目标中,我们可能在求解上遇到一些困难。
考察约束个数,我们发现上述的约束个数为n*|Y|-n,如果我们考虑Y的维度十分高的时候,我们对于这个问题的求解是无能为力的。
但是我们同时进行一些直观的思考,我们很难去想象,我们最终搜索的可行域,是被所有的约束条件所限制的,直观上和实际上,大多数约束都属于redundancy,对于我们的求解,我们希望避开所有这样的约束(甚至于,某些有意义的约束在求解过程中也是可以忽略的)。
因此我们在实际求解中,我们会使用cutting plane algorithm,其思想是进行试错,每一次选择违背最厉害(violated mostly)的约束,将之加入到约束集中,直到不违反任何约束为止。
考虑到我们的学习过程可以和约束选择过程可以同时进行,因此我们不难想象这一个算法的收敛是比较快的。
其算法步骤如下:

或者:

标签:思想 most 分享图片 变量 并且 介绍 分类 关于 理解
原文地址:https://www.cnblogs.com/sugar-mouse-wbz/p/9884898.html