标签:结构体 stack agg har 去掉 bool 匹配 scan 程序
不得不想吐槽一下编译原理的实验代码量实在是太大了,是编译原理撑起了我大学四年的代码量...
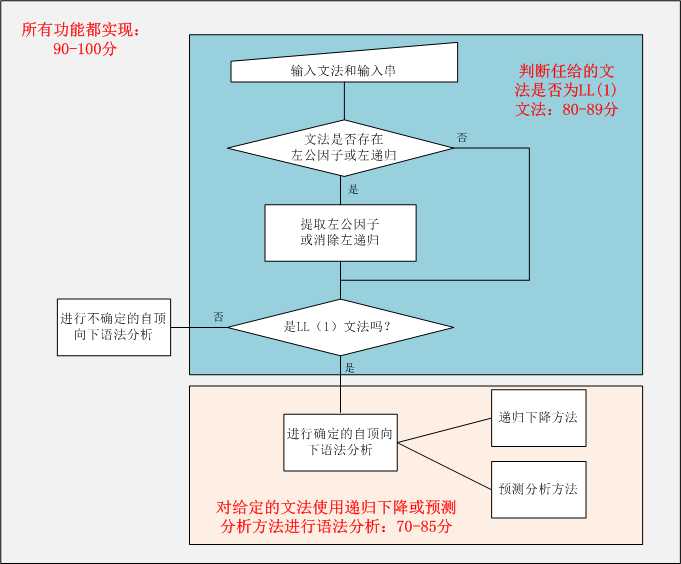
这次实验比上次要复杂得多,涵盖的功能也更多了,我觉得这次实验主要的难点有两个(其实都是难点...):
1. 提取左公因子或消除左递归(实现了消除左递归)
2. 递归求First集和Follow集
其它的只要按照课本上的步骤顺序写下来就好(但是代码量超多...),下面我贴出实验的一些关键代码和算法思想。
功能:主要用来处理输入的文法,包括将文法中的终结符和非终结符分别存储,检测直接左递归和左公因子,消除直接左递归,获得所有非终结符的First集,Follow集以及产生式的Select集。
#ifndef GRAMMAR_H #define GRAMMAR_H #include <string> #include <cstring> #include <iostream> #include <vector> #include <set> #include <iomanip> #include <algorithm> using namespace std; const int maxn = 110; //产生式结构体 struct EXP{ char left; //左部 string right; //右部 }; class Grammar { public: Grammar(); //构造函数 bool isNotTer(char x); //判断是否是终结符 int getTer(char x); //获取终结符下标 int getNonTer(char x); //获取非终结符下标 void getFirst(char x); //获取某个非终结符的First集 void getFollow(char x); //获取某个非终结符的Follow集 void getSelect(char x); //获取产生式的Select集 void input(); //输入文法 void scanExp(); //扫描输入的产生式,检测是否有左递归和左公因子 void remove(); //消除左递归 void solve(); //处理文法,获得所有First集,Follow集以及Select集 void display(); //打印First集,Follow集,Select集 void debug(); //用于debug的函数 ~Grammar(); //析构函数 protected: int cnt; //产生式数目 EXP exp[maxn]; //产生式集合 set<char> First[maxn]; //First集 set<char> Follow[maxn]; //Follow集 set<char> Select[maxn]; //select集 vector<char> ter_copy; //去掉$的终结符 vector<char> ter; //终结符 vector<char> not_ter; //非终结符 }; #endif
功能:得到预测分析表,判断输入的文法是否是LL(1)文法,用预测分析表法判断输入的符号串是否符合刚才输入的文法,并打印出分析过程。
#ifndef ANALYZTABLE_H #define ANALYZTABLE_H #include "Gramma.h" class AnalyzTable:public Gramma { public: AnalyzTable(); void getTable(); //得到分析表 void judge(); //判断是否是LL(1)文法 void analyExp(string s); //分析输入串 void displayTable(); //打印表 void inputString(); //输入符号串 ~AnalyzTable(); protected: string s; //符号串 vector<char> stack; //分析栈 vector<char> left; //剩余输入串 int detect[maxn][maxn]; //检测表 int table[maxn][maxn]; //预测分析表 }; #endif
非终结符:大写字母‘A‘~‘Z‘
终结符:除大写字母之外的所有字符
空串:$
符号栈终止符:#
规定第一个产生式的左边那个非终结符就是开始符号
输入的产生式需要分开写(比如A->a|b, 要输入A->a和A->b才能处理)
遍历每一个左部为x的产生式
如果产生式右部第一个字符为终结符,则将其计入左部非终结符的First集
如果产生式右部第一个字符为非终结符
求该非终结符的First集
将该非终结符的去掉$的First集计入左部的First集
若存在$,继续往后遍历右部
若不存在$,则停止遍历该产生式,进入下一个产生式
若已经到达产生式的最右部的非终结符(即右部的First集都含有空串),则将$加入左部的First集
//求出非终结符的First集 void Gramma::getFirst(char x){ cout<<x<<endl; bool flag = 0; //记录非终结符的First集是否有空串 int tot = 0; //记录一个非终结符产生式含有空串的产生式 for(int i=0;i<cnt;i++){ if(exp[i].left==x){ //如果右部的第一个字符是终结符 if(!isNotTer(exp[i].right[0])){ First[getNonTer(x)].insert(exp[i].right[0]); } //如果是非终结符 else{ //从左到右遍历右部 for(int j=0;j<exp[i].right.length();j++){ //如果遇到终结符,结束 if(!isNotTer(exp[i].right[j])){ First[getNonTer(x)].insert(exp[i].right[j]); break; } //不是终结符,求该非终结符的First集 getFirst(exp[i].right[j]); set<char>::iterator it; int ind = getNonTer(exp[i].right[j]); for(it=First[ind].begin();it!=First[ind].end();it++){ if(*it==‘$‘){ flag = 1; }else{ First[getNonTer(x)].insert(*it); } } //没有空串就不必再找下去了 if(flag==0){ break; }else{ flag = 0; tot++; } } //如果右部所有符号的First集都有空串,则符号x的First集也有空串 if(tot==exp[i].right.length()){ First[getNonTer(x)].insert(‘$‘); } } } } }
遍历每一个右部包含非终结符x的产生式
如果x的下一个字符是终结符,添加进x的Follow集
如果x的下一个字符是非终结符,把该字符的First集加入x的Follow集(不能加入空串)
如果下一字符的First集有空串并且该产生式的左部不是x,则把左部的Follow集加入x的Follow集
如果x已经是产生式的末尾,则把左部的Follow集添加到x的Follow集里
//求出非终结符的Follow集 void Gramma::getFollow(char x){ //找到非终结符x出现的位置 for(int i=0;i<cnt;i++){ int index = -1; int len = exp[i].right.length(); for(int j=0;j<len;j++){ if(exp[i].right[j]==x){ index = j; break; } } //如果找到了x,并且它不是最后一个字符 if(index!=-1&&index<len-1){ //如果下一个字符是终结符,添加进x的Follow集 char next = exp[i].right[index+1]; if(!isNotTer(next)){ Follow[getNonTer(x)].insert(next); }else{ //如果下一个字符是非终结符 bool flag = 0; set<char>::iterator it; //遍历下一个字符的First集 for(it = First[getNonTer(next)].begin();it!=First[getNonTer(next)].end();it++){ if(*it==‘$‘){ flag = 1; }else{ Follow[getNonTer(x)].insert(*it); } } //如果有空串并且左部不是它本身(防止陷入死循环),当前非终结符的Follow集是x的Follow集 char tmp = exp[i].left; if(flag&&tmp!=x){ getFollow(tmp); set<char>::iterator it; for(it = Follow[getNonTer(tmp)].begin();it!=Follow[getNonTer(tmp)].end();it++){ Follow[getNonTer(x)].insert(*it); } } } }else if(index!=-1&&index==len-1&&x!=exp[i].left){ //如果x在产生式的末尾,则产生式左部的Follow集应该添加到x的Follow集里 char tmp = exp[i].left; getFollow(tmp); set<char>::iterator it; for(it = Follow[getNonTer(tmp)].begin();it!=Follow[getNonTer(tmp)].end();it++){ Follow[getNonTer(x)].insert(*it); } } } }
如果右部的第一个字符tmp是终结符且不是空串,更新预测分析表,即table[left][tmp] = i(i为产生式编号)
如果右部的第一个字符是空串,遍历左部的Follow集,更新预测分析表,即table[left][x] = i(i为产生式编号,x为Follow集字符编号)
如果右部的第一个字符是非终结符,遍历它的First集,更新预测分析表,即table[left][x] = i(i为产生式编号,x为First集字符编号)
//获得预测分析表 void AnalyzTable::getTable(){ for(int i=0;i<cnt;i++){ char tmp = exp[i].right[0]; //如果产生式右部的第一个字符是终结符 if(!isNotTer(tmp)){ //该终结符不是空串,更新table if(tmp!=‘$‘){ detect[getNonTer(exp[i].left)][getTer(tmp)]++; table[getNonTer(exp[i].left)][getTer(tmp)] = i; } if(tmp==‘$‘){ //该终结符是空串,遍历左部的Follow集,更新table set<char>::iterator it; for(it = Follow[getNonTer(exp[i].left)].begin();it!=Follow[getNonTer(exp[i].left)].end();it++){ table[getNonTer(exp[i].left)][getTer(*it)] = i; detect[getNonTer(exp[i].left)][getTer(*it)]++; } } }else{ //如果产生式右部的第一个字符是非终结符,遍历它的First集,更新table set<char>::iterator it; for(it = First[getNonTer(tmp)].begin();it!=First[getNonTer(tmp)].end();it++){ table[getNonTer(exp[i].left)][getTer(*it)] = i; detect[getNonTer(exp[i].left)][getTer(*it)]++; } //如果有空串,遍历左部的Follow集,更新table if(First[getNonTer(tmp)].count(‘$‘)!=0){ set<char>::iterator it; for(it = Follow[getNonTer(exp[i].left)].begin();it!=Follow[getNonTer(exp[i].left)].end();it++){ table[getNonTer(exp[i].left)][getTer(*it)] = i; detect[getNonTer(exp[i].left)][getTer(*it)]++; } } } } }
若f1=f2=“#”,则分析成功,停止分析
若f1=f2≠”#”,则把f1从栈顶弹出,让f2指向下一个输入符号.
若f1是一个非终结符,则查看分析表,若table[f1][f2]中有值,则f1出栈,并且产生式的右部反序进栈
再把产生式的右部符号推进栈的同时应做这个产生式相应得语义动作,若M[A,a]中存放着”出错标志”,则调用出错诊察程序error.

分析栈
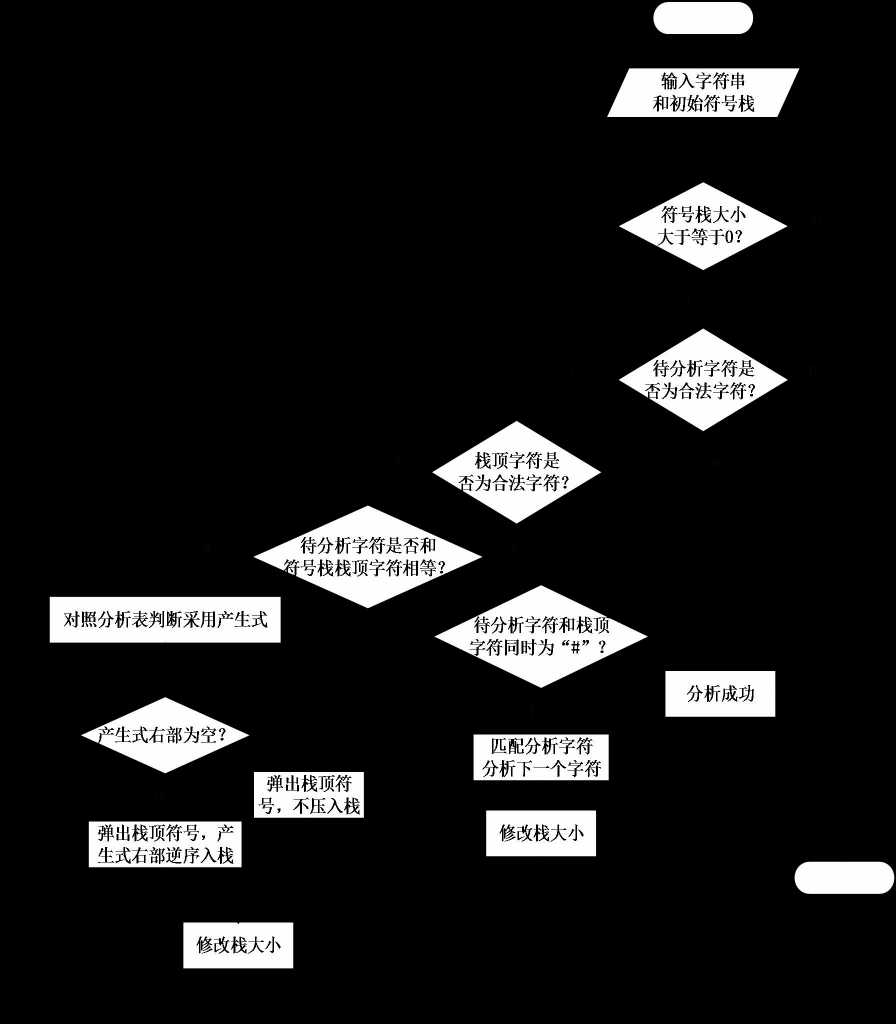
流程图
//分析符号串 void AnalyzTable::analyExp(string s){ cout<<setw(15)<<"分析栈"<<setw(15)<<"剩余输入串"<<setw(20)<<"推导式"<<endl; //把整个串倒序push进剩余符号vector left.push_back(‘#‘); for(int i=s.length()-1;i>=0;i--){ left.push_back(s[i]); } //把#和开始符push进分析栈 stack.push_back(‘#‘); stack.push_back(not_ter[0]); //如果剩余输入串长度不为0,就一直循环 while(left.size()>0){ //输出分析栈内容 string outputs = ""; for(int i=0;i<stack.size();i++){ outputs+=stack[i]; } cout<<setw(15)<<outputs; outputs = ""; //输出剩余输入串内容 for(int i=left.size()-1;i>=0;i--){ outputs+=left[i]; } cout<<setw(15)<<outputs; char f1 = stack[stack.size()-1]; char f2 = left[left.size()-1]; //如果可以匹配,并且都为# if(f1==f2&&f1==‘#‘){ cout<<setw(21)<<"Accept!"<<endl; return; } //如果可以匹配,并且都为终结符 if(f1==f2){ stack.pop_back(); left.pop_back(); cout<<setw(15)<<f1<<" 匹配"<<endl; }else if(table[getNonTer(f1)][getTer(f2)]!=-1){ //如果在预测分析表中有值 int index = table[getNonTer(f1)][getTer(f2)]; stack.pop_back(); if(exp[index].right!="$"){ for(int i=exp[index].right.length()-1;i>=0;i--){ stack.push_back(exp[index].right[i]); } } cout<<setw(15)<<exp[index].left<<"->"<<exp[index].right<<endl; }else{ cout<<setw(15)<<"error"<<endl; return; } } }
标签:结构体 stack agg har 去掉 bool 匹配 scan 程序
原文地址:https://www.cnblogs.com/jiaqi666/p/9879777.html