标签:自动删除 tor 权重 san 网站链接 最好 并发 解决 不能
Redis是一款开源的、高性能的键-值存储。它常被称作是一款数据结构服务器。
当值支持的主要数据类型为:字符串(strings)类型,括哈希(hashes)、列表(lists)、集合(sets)和 有序集合(sorted sets)等数据类型。
同时Redis可以进行持久化(将数据存到硬盘),意味着不仅仅可以作为高速缓存服务器,也可以作为数据库使用。
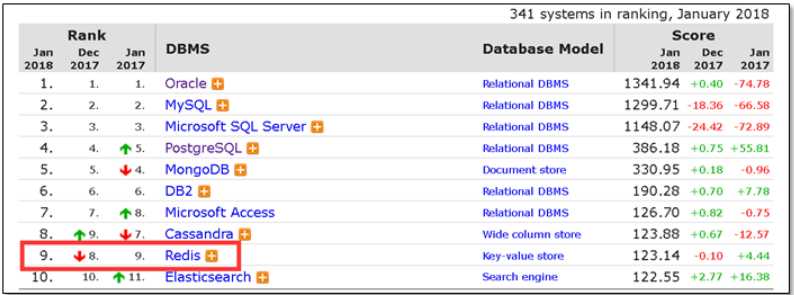
数据来源:https://db-engines.com/en/ranking
菜鸟教程 -> http://www.runoob.com/redis/redis-tutorial.html
redis中文网站 -> http://doc.redisfans.com/index.html
Redis支持多种数据类型,适应更多的场景需求。 支持发布订阅,管道 设置TTL存活时间,到期自动删除 可以执行lua脚本 提供了简单的事务功能, 能在一定程度上保证事务特性。 提供了流水线(Pipeline) 功能, 这样客户端能将一批命令一次性传到Redis, 减少了网络的开销。 可以使用内存做持久化 可以将数据复制到任意数量的从服务器。
Memcached:
优点:高性能读写、单一数据类型、支持客户端式分布式集群、一致性hash多核结构、多线程读写性能高。
缺点:无持久化、节点故障可能出现缓存穿透、分布式需要客户端实现、跨机房数据同步困难、架构扩容复杂度高
Redis:
优点:高性能读写、多数据类型支持、数据持久化、高可用架构、支持自定义虚拟内存、支持分布式分片集群、单线程读写性能极高
缺点:多线程读写较Memcached慢
Tair:
优点:高性能读写、支持三种存储引擎(ddb、rdb、ldb)、支持高可用、支持分布式分片集群、支撑了几乎所有淘宝业务的缓存。
缺点:单机情况下,读写性能较其他两种产品较慢
命令执行结构:
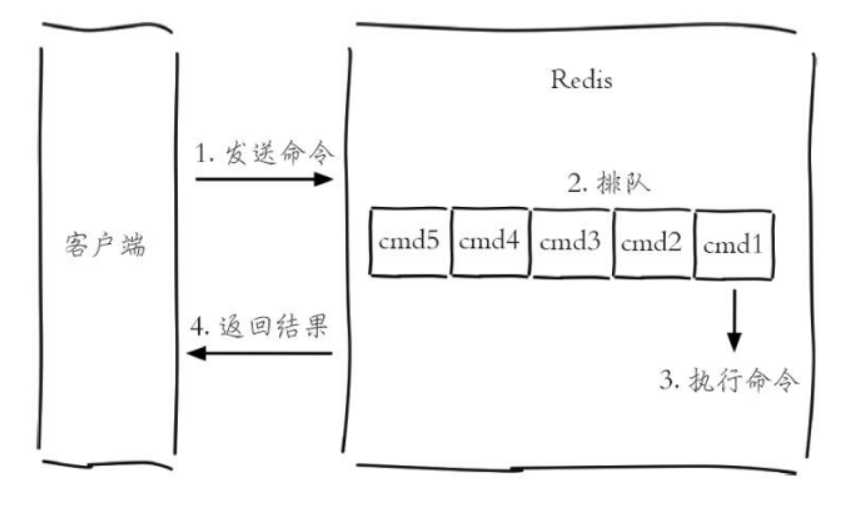
一条客户端命令的生命周期
客户端发送命令后,Redis服务器将为这个客户端链接创造一个’输入缓存’,将命令放到里面。之后再由Redis服务器进行分配挨个执行,顺序是随机的,这将不会产生并发冲突问题,也就不需要事物了。最后再将结果返回到客户端的’输出缓存’中,客户端再获得信息结果。
如果数据是写入命令,例如set name:1 zhangsan方式添加一个字符串
redis将根据策略,将这对 key:value 来用内部编码格式存储。好处是改变内部编码不会对外有影响,正常操作即可,同时不同情况下存储格式不一样,发挥优势。
Redis高性能原因:
基于内存的访问,非阻塞I/O,Redis使用事件驱动模型epoll多路复用实现,连接、读写、关闭都转换为事件,不在网络I/O上浪费过多的时间。单线程避免的高并发的时候,多线程有锁的问题和线程切换的CPU开销的问题。
虽然是单线程的,我们还可以通过多实例来弥补。
String 字符串类型 Hash散列类型 List列表类型 Set集合类型 Zset有序集合类型

分析:是不是觉得这个问题很基础,其实我也这么觉得。然而根据面试经验发现,至少百分八十的人答不上这个问题。建议,在项目中用到后,再类比记忆,体会更深,不要硬记。基本上,一个合格的程序员,五种类型都会用到。
回答:一共五种
(一)String
这个其实没啥好说的,最常规的set/get操作,value可以是String也可以是数字。一般做一些复杂的计数功能的缓存。
(二)hash
这里value存放的是结构化的对象,比较方便的就是操作其中的某个字段。博主在做单点登录的时候,就是用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
(三)list
使用List的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好。
(四)set
因为set堆放的是一堆不重复值的集合。所以可以做全局去重的功能。为什么不用JVM自带的Set进行去重?因为我们的系统一般都是集群部署,使用JVM自带的Set,比较麻烦,难道为了一个做一个全局去重,再起一个公共服务,太麻烦了。
另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
(五)sorted set
sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。另外,参照另一篇《分布式之延时任务方案解析》,该文指出了sorted set可以用来做延时任务。最后一个应用就是可以做范围查找。
缓存:
Redis提供了键值过期时间设置, 并且也提供了灵活控制最大内存和内存溢出后的淘汰策略。可以这么说,一个合理的缓存设计能够为一个网站的稳定保驾护航。
社交网络:
赞/踩、 粉丝、 共同好友/喜好、 推送、 下拉刷新等是社交网站的必备功能,由于社交网站访问量通常比较大, 而且传统的关系型数据不太适合保存这种类型的数据, Redis提供的数据结构可以相对比较容易地实现这些功能。
分析:博主觉得在项目中使用redis,主要是从两个角度去考虑:性能和并发。当然,redis还具备可以做分布式锁等其他功能,但是如果只是为了分布式锁这些其他功能,完全还有其他中间件(如zookpeer等)代替,并不是非要使用redis。因此,这个问题主要从性能和并发两个角度去答。
回答:如下所示,分为两点
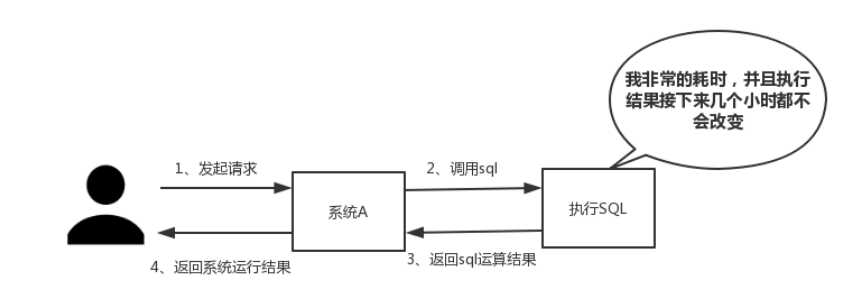
(一)性能
如下图所示,我们在碰到需要执行耗时特别久,且结果不频繁变动的SQL,就特别适合将运行结果放入缓存。这样,后面的请求就去缓存中读取,使得请求能够迅速响应。
题外话:忽然想聊一下这个迅速响应的标准。其实根据交互效果的不同,这个响应时间没有固定标准。不过曾经有人这么告诉我:"在理想状态下,我们的页面跳转需要在瞬间解决,对于页内操作则需要在刹那间解决。另外,超过一弹指的耗时操作要有进度提示,并且可以随时中止或取消,这样才能给用户最好的体验。"
那么瞬间、刹那、一弹指具体是多少时间呢?
根据《摩诃僧祗律》记载
一刹那者为一念,二十念为一瞬,二十瞬为一弹指,二十弹指为一罗预,二十罗预为一须臾,一日一夜有三十须臾。那么,经过周密的计算,一瞬间为0.36 秒,一刹那有 0.018 秒.一弹指长达 7.2 秒。
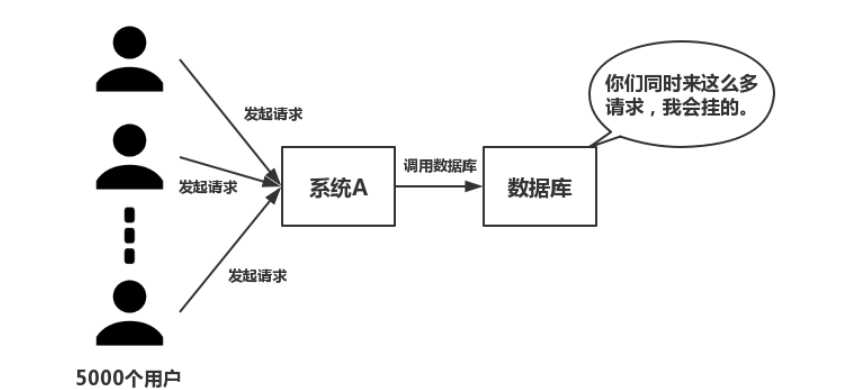
(二)并发
如下图所示,在大并发的情况下,所有的请求直接访问数据库,数据库会出现连接异常。这个时候,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问数据库。
分析:大家用redis这么久,这个问题是必须要了解的,基本上使用redis都会碰到一些问题,常见的也就几个。
回答:主要是四个问题
(一)缓存和数据库双写一致性问题 (二)缓存雪崩问题 (三)缓存击穿问题 (四)缓存的并发竞争问题
这四个问题,我个人是觉得在项目中,比较常遇见的
分析:一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。数据库和缓存双写,就必然会存在不一致的问题。答这个问题,先明白一个前提。就是如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证最终一致性。另外,我们所做的方案其实从根本上来说,只能说降低不一致发生的概率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
回答:《分布式之数据库和缓存双写一致性方案解析》给出了详细的分析,在这里简单的说一说。首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
分析:这两个问题,说句实在话,一般中小型传统软件企业,很难碰到这个问题。如果有大并发的项目,流量有几百万左右。这两个问题一定要深刻考虑。
回答:如下所示
缓存穿透,即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常。
解决方案:
(一)利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试
(二)采用异步更新策略,无论key是否取到值,都直接返回。value值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
(三)提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的key。迅速判断出,请求所携带的Key是否合法有效。如果不合法,则直接返回。
缓存雪崩,即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常。
解决方案:
(一)给缓存的失效时间,加上一个随机值,避免集体失效。
(二)使用互斥锁,但是该方案吞吐量明显下降了。
(三)双缓存。我们有两个缓存,缓存A和缓存B。缓存A的失效时间为20分钟,缓存B不设失效时间。自己做缓存预热操作。然后细分以下几个小点
分析:这个问题大致就是,同时有多个子系统去set一个key。这个时候要注意什么呢?大家思考过么。需要说明一下,博主提前百度了一下,发现答案基本都是推荐用redis事务机制。博主不推荐使用redis的事务机制。因为我们的生产环境,基本都是redis集群环境,做了数据分片操作。你一个事务中有涉及到多个key操作的时候,这多个key不一定都存储在同一个redis-server上。因此,redis的事务机制,十分鸡肋。
回答:如下所示
(1)如果对这个key操作,不要求顺序
这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可,比较简单。
(2)如果对这个key操作,要求顺序
假设有一个key1,系统A需要将key1设置为valueA,系统B需要将key1设置为valueB,系统C需要将key1设置为valueC.
期望按照key1的value值按照 valueA-->valueB-->valueC的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳如下
系统A key 1 {valueA 3:00}
系统B key 1 {valueB 3:05}
系统C key 1 {valueC 3:10}那么,假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。以此类推。
其他方法,比如利用队列,将set方法变成串行访问也可以。总之,灵活变通。
注:文章中redis部分内容转载出处:https://www.cnblogs.com/rjzheng/
https://www.cnblogs.com/clsn/p/8409458.html#auto_id_0
https://www.abcdocker.com
标签:自动删除 tor 权重 san 网站链接 最好 并发 解决 不能
原文地址:https://www.cnblogs.com/tim1blog/p/9885060.html