标签:stash 配置 技术栈 机器 time base 需要 max 能力
目录
Elasticsearch(ES)是一个基于Apache的开源索引库Lucene而构建的开源、分布式、RESTful接口的全文搜索引擎, 还是一个分布式文档数据库.
ES可以轻松扩展数以百计的服务器(水平扩展), 用于存储和处理数据. 它可以在很短的时间内存储、搜索和分析海量数据, 通常被作为复杂搜索场景下的核心引擎.
由于Lucene提供的API操作起来异常繁琐, 需要编写大量的代码, Elasticsearch就对Lucene 进行了封装与优化, 并提供了REST风格的操作接口, 开箱即用, 大大的方便了开发人员的使用.
关于全文检索与Lucene方面的简介, 请参照博主的博客: Lucene01-全文搜索及Lucene简介
(1) 维基百科(类似百度百科): 全文检索, 高亮, 搜索推荐;
(2) The Guardian(新闻网站): 用户行为日志(点击, 浏览, 收藏, 评论) + 社交网络数据(对某某新闻的相关看法), 数据分析(将公众对文章的反馈提交至文章作者);
(3) Stack Overflow(IT技术论坛): 全文检索, 搜索相关问题和答案;
(4) GitHub(开源代码管理), 搜索管理其托管的上千亿行代码;
(5) 日志数据分析: ELK技术栈(Elasticsearch + Logstash + Kibana)对日志数据进行采集&分析;
(6) 商品价格监控网站: 用户设定某商品的价格阈值, 当价格低于该阈值时, 向用户推送降价消息;
(7) BI系统(Business Intelligence, 商业智能): 分析某区域最近3年的用户消费额的趋势、用户群体的组成结构等;
(8) 其他应用: 电商、招聘、门户等网站的内部搜索服务, IT系统(OA, CRM, ERP等)的内部搜索服务, 数据分析(ES的又一热门使用场景).
select * from products where product_name like "%编程思想%" ;select * from products where category_id=‘计算机科学‘ ;select category_id, count(*) from products group by category_id ;关于近实时:
非近实时: 检索x个数据要花费很长时间(这就不是近实时, 而是离线批处理, batch-processing).
实时: 数据的处理与响应都是立即呈现的, 几乎没有间隔, 这在大数据应用场景下是很难达到的要求.
近实时(near real-time, NRT): 对海量数据进行搜索和分析的响应耗时控制在秒级以内, 方可称为近实时.
Term(索引词)
- 在ES中, 索引词(Term)是一个能够被索引的精确值, 可以通过Term查询进行准确搜索.
- 举例: foo、Foo、FOO是不同的索引词.
Text(文本)
- 文本是一段普通的非结构化文字, 通长文本会被分析成多个Term, 存储在ES的索引库中.
- 文本字段一般需要先分析再存储, 查询文本中的关键词时, 需要根据搜索条件搜索出原文本.
Analysis(分析)
- 分析是将文本转换为索引词的过程, 分析的结果依赖于分词器.
- 比如: FOO BAR、Foo-Bar和foo bar可能会被分析成相同的索引词foo和bar, 然后被存储到ES的索引库中. 当用FoO:bAr进行全文搜索的时候, 搜索引擎根据匹配计算也能在索引库中查找到相关的内容.
Cluster(集群)
- 集群由一个或多个节点组成, 对外提供索引和搜索服务. 集群中有且只能有一个节点被选举为主节点 —— 主从节点是集群内部的说法, 对用户是透明的 —— 去中心化.
- 同一网络中, 每个ES集群都要有唯一的名称用于区分, 默认的集群名称为"Elasticsearch".
- 水平扩展时, 只需要将新增节点的集群名称设置为要扩容的集群名称, 该节点就会自动加入集群中.
- 一个节点只能加入到一个集群中.
Node(节点)
- 节点是逻辑上独立的服务, 是集群的一部分, 可以存储数据, 并参与集群的索引和检索功能.
- 节点也有唯一的名称, 用于集群的管理和通信. 节点名称在启动的时候自动分配 —— 当然可以自定义.
- 如果有多个节点在运行, 默认情况下, 这些节点会自动组成一个名为Elasticsearch的集群.
- 如果只有一个节点在运行, 该节点就会组成只有一个节点的名为Elasticsearch的集群.
- 每个节点属于哪个集群是通过"集群名称"来决定的.
Shard(分片)
- 单台机器(节点)无法存储大量的索引数据, ES可以把一个完整的索引分成多个分片, 分布到不同的节点上, 从而构成分布式索引.
- 分片的数量只能在创建索引前指定, 创建索引后不能修改.
- 每个分片都是一个Lucene实例, 即每个分片底层都有一个单独的Lucene提供索引和检索服务, 它们可以托管在集群的任一节点上.
- 单个Lucene中存储的索引文档最大值为 lucene-5843, 极限是
2147483519(=integer.max_value - 128)个文档. 可使用_cat/shards API 监控分片的大小.
Replica(副本)
- ES支持为每个Shard创建多个副本, 相当于索引数据的冗余备份.
- 副本的重要性:
- ① 解决单点问题, 提高可用性和容错性: 某些节点失败时服务不受影响;
- ② 提高查询效率: 搜索可以在所有的副本上并行执行, 提高了服务的并发量.
Primary Shard & Replica Shard(主分片和副本分片)
- 分片分为Primary Shard(主分片)、Replica Shard(副本分片), 建立索引时, 系统会先将索引存储在主分片中, 然后再将主分片中的索引复制到不同的副本中.
- 注意: 主分片和副本分片不能存储在同一个节点中 —— 无法保证高可用. 主分片在建立索引时设置, 默认为5个, 后期不能修改; 系统默认每个主分片各有一个副本分片, 即共有5个副本分片, 可随时修改其数量.
- ==> 默认情况下, 每个索引共有10个Shard = 5个Primary Shard + 5个Replica Shard.
- ==> 集群中至少要有2个节点: 最小的高可用配置.
ES的索引中, 各概念的关系为: Field =组成=> Document =组成=> Type =组成=> Index, 索引结构图如下:
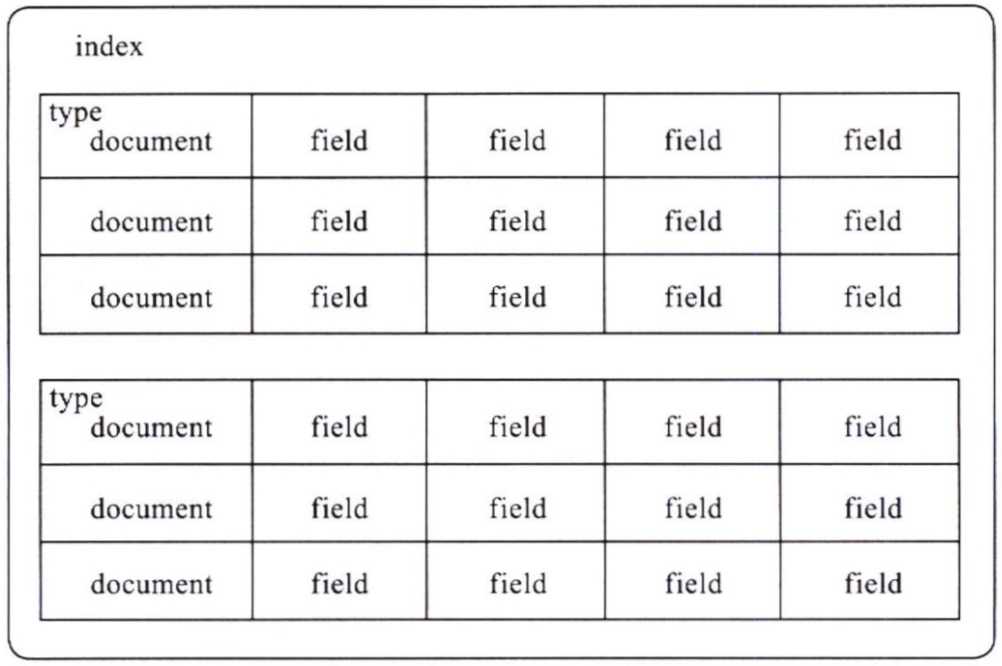
Index(索引)
- 索引是具有相似结构的文档的集合, 比如可以有一个商品分类索引, 订单索引.
- 索引的名称要小写, 通过索引名称来执行索引、搜索、更新和删除等操作.
Type(类型)
- 每个索引中可以定义一个或多个Type, Type是Index的逻辑分类.
- 一种Type一般被定义为具有一组公共field的document, 比如对博客系统中的数据建立索引, 可以定义用户数据Type, 博客数据Type, 评论数据Type.
Document(文档)
文档是存储在ES中的一个JSON格式的字符串, 是ES索引中的最小数据单元.
一个Document可以是一条商品分类数据, 一条订单数据, 例如:
# book document { "book_id": "1", "book_name": "Thinking in Java(Java 编程思想)", "book_desc": "Java学习者不得不看的经典书籍", "book_price": 108.00, "category_id": "5" }
Mapping(映射)
- 类似于关系数据库中的表结构, 每个Index都有一个映射: 定义索引中每个字段的类型.
- 映射可以提前定义, 也可以在第一次存储文档时自动识别.
- 类似于Solr中约束schema.xml文件的作用.
Field(字段)
- 字段可以是一个简单的值(如字符串、数字、日期), 也可以是一个数组, 还可以嵌套一个对象或多个对象.
- 字段类似于关系数据库中表数据的列, 每个字段都对应一个类型.
- 可以指定如何分析某一字段的值, 即对Field指定分词器.
Source Field(源字段)
- 原始的JSON文档被存储在
_source字段中, 搜索文档时默认返回该字段及其内容.- 该字段不存储索引分析后的任何其他数据.
ID(主键)
- ID是一个Document的唯一标识, 如果存储文档时没有提供ID, ES会自动生成一个ID.
- Document的Index/Type/ID都必须是唯一的.
| Elasticsearch | RDBMS |
|---|---|
| Index(索引) | DataBase(数据库) |
| Type(类型) | Table(表) |
| Document(文档) | Row(行) |
| Field(字段) | Column(列) |
《Elasticsearch技术解析与实战》朱林 编著, 机械工业出版社出版
版权声明
作者: ma_shoufeng(马瘦风)
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但未经博主同意必须保留此段声明, 且在文章页面明显位置给出原文链接, 否则博主保留追究法律责任的权利.
标签:stash 配置 技术栈 机器 time base 需要 max 能力
原文地址:https://www.cnblogs.com/shoufeng/p/9887327.html