标签:elastic delete chunk 个性 str ... 不能 value nal
批量导入可以合并多个操作,比如index,delete,update,create等等。也可以帮助从一个索引导入到另一个索引。
语法大致如下;
action_and_meta_data\n
optional_source\n
action_and_meta_data\n
optional_source\n
....
action_and_meta_data\n
optional_source\n需要注意的是,每一条数据都由两行构成(delete除外),其他的命令比如index和create都是由元信息行和数据行组成,update比较特殊它的数据行可能是doc也可能是upsert或者script,如果不了解的朋友可以参考前面的update的翻译。
注意,每一行都是通过\n回车符来判断结束,因此如果你自己定义了json,千万不要使用回车符。不然_bulk命令会报错的!
比如我们现在有这样一个文件,data.json:
{ "index" : { "_index" : "test", "_type" : "type1", "_id" : "1" } }
{ "field1" : "value1" }它的第一行定义了_index,_type,_id等信息;第二行定义了字段的信息。
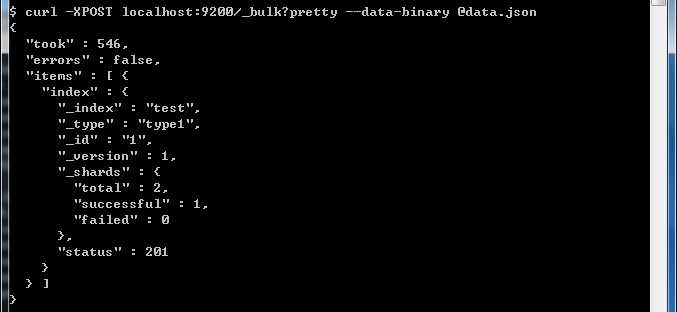
然后执行命令:
curl -XPOST localhost:9200/_bulk --data-binary @data.json就可以看到已经导入进去数据了。
对于其他的index,delete,create,update等操作也可以参考下面的格式:
{ "index" : { "_index" : "test", "_type" : "type1", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_type" : "type1", "_id" : "2" } }
{ "create" : { "_index" : "test", "_type" : "type1", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_type" : "type1", "_index" : "index1"} }
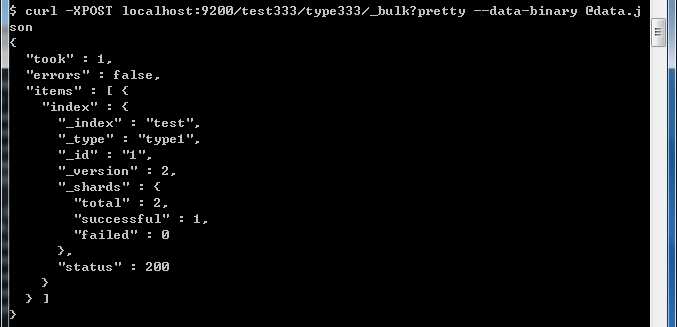
{ "doc" : {"field2" : "value2"} }如果在路径中设置了index或者type,那么在JSON中就不需要设置了。如果在JSON中设置,会覆盖掉路径中的配置。
比如上面的例子中,文件中定义了索引为test,类型为type1;而我们在路径中定义了默认的选项,索引为test333,类型为type333。执行命令后,发现文件中的配置会覆盖掉路径中的配置。这样也提供了统一的默认配置以及个性化的特殊配置的需求。
由于bulk是一次性提交很多的命令,它会把这些数据都发送到一个节点,然后这个节点解析元数据(index或者type或者id之类的),然后分发给其他的节点的分片,进行操作。
由于很多命令执行后,统一的返回结果,因此数据量可能会比较大。这个时候如果使用的是chunk编码的方式,分段进行传输,可能会造成一定的延迟。因此还是对条件在客户端进行一定的缓冲,虽然bulk提供了批处理的方法,但是也不能给太大的压力!
最后要说一点的是,Bulk中的操作执行成功与否是不影响其他的操作的。而且也没有具体的参数统计,一次bulk操作,有多少成功多少失败。
扩展:在Logstash中,传输的机制其实就是bulk,只是他使用了Buffer,如果是服务器造成的访问延迟可能会采取重传,其他的失败就只丢弃了....
标签:elastic delete chunk 个性 str ... 不能 value nal
原文地址:https://www.cnblogs.com/crystaltu/p/9889478.html