标签:图片 bsp names 命令 超时 nod 解决方案 alt 直接
问题说明:
一个POD里放了百个容器,然后让K8S集群部署上百个POD,得到可运行上万个容器的实验目的。
实验环境:3台DELL裸机服务器,16核+64G,硬盘容量忽略吧,上T了,肯定够。
1.一开始运行5000多个容器的时候(也就50个POD),集群部署后,10几分钟就起来了,感觉还不错。
2.增加压力,把50个POD增加到100个POD,感觉也不会很长时间,都等到下班后又过了半个小时,还是没有起来,集群链接缓慢,使用kubect里面的命令,好久都出不来信息,UI界面显示服务器超时。
心想,完了,起不来了,把服务器撑死了。让其晚上慢慢启动吧,明天早上查看。
当当当,早上来上班了
打开服务器,使用SSH连接 master 节点,挺好,连接挺快,使用kubectl命令获取pods 信息,居然报服务器错误了,基本都是服务器超时的错误。……
然后用ssh连接 node 节点,直接连不上,本地一致在转圈圈,去机房接显示屏连接,直接也没有反应。
这下子坏了,难道要重新装服务器了,键盘鼠标 CPU都给他分配资源了。这不坏了嘛。。
敲重点……还好,master节点很好,可以连接。这一点Kubernetes做的比较好(我三台服务器的配置一样),有Master节点在就不用担心。
解决方案,上网,问大神,给的方法是 用etcd ,进入集群的专用数据库etcd,删除其POD,然后让服务器转起来
又呵呵了,对与我这样的小白,压根都不会ETCD数据库,K8S集群才刚搭建起来玩玩,怎么会那么高深的操作。
这下会不会被炒鱿鱼!!!!!!!!
突然想到了一个绝招 ,用Docker 呀,看看Docker 是否好用,这也是本次实验的杀手锏了。。下面开始着重讲述了
1.连接master节点,然后输入docker images 和docker ps 和docker ps -a 命令也就会这三个,下了一跳 ,上万个容器僵死在那里,怪不得服务器起不来,上图

2.先把所有的容器 stop掉 ,或者把你认为想stop掉的容器都可以停掉,看下 面我的操作
1 docker stop $(docker ps -q -f name=k8s_hello-ros-10*) //就是停止掉前缀名字为 k8s_hello-ros-10 的容器
3.把停到的容器 删除掉,容器太多,这一步运行的有点慢(上面的代码和这次代码做了一个合并)
1 docker stop $(docker ps -q -f name=k8s_hello-ros-10*) & docker rm $(docker ps -aq -f name=k8s_hello-ros-10*)
4.处理完之后,迅速回到Master节点的kubectl命令下,此时K8S集群有反应了,先把你的创建的pod时用的yaml 文件删除,输入命令
1 kubuetc delete -f XXX.yaml
5. 删除你的部署名,因为我是创建POD时,使用Deployments 部署的,所以删除部署,省的根据副本控制器自己又创建POD,那又陷入死循环了
1 1. kubeclt get deployments -n namespace名字 2 2.找到命令空间,删除 3 kubectl delete deployemtns XXX -n XXX命名空间
6.准备关机重启吧
先关闭NODE节点机,再关闭MASTER机器,重启看看吧
顺利成功,K8S集群启动后,原先的POD已全部删除,剩下了系统要用的POD,集群正常运转。
一次危机就这么化解了……
然后又部署了5000个容器,不敢玩大了,下面图
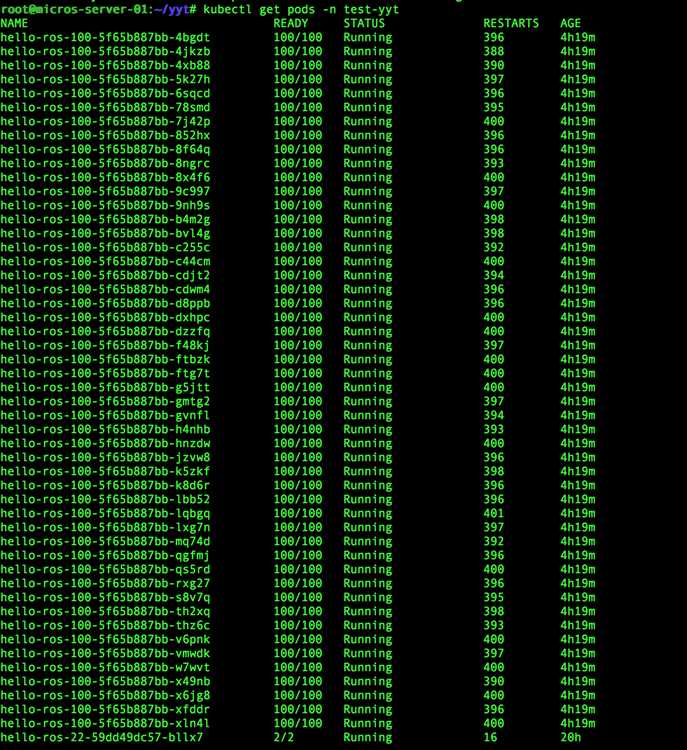
k8s集群启动了上万个容器(一个pod里放上百个容器,起百个pod就模拟出上万个容器)服务器超时,无法操作的解决办法
标签:图片 bsp names 命令 超时 nod 解决方案 alt 直接
原文地址:https://www.cnblogs.com/yytlmm/p/9890485.html