标签:back 字节 open() 使用 ESS ack 文件上传 编辑 修改
使用Python来读写文件是非常简单的操作,我们使用open()函数来打开一个文件,获取到文件句柄,然后通过文件句柄就可以进行各种各样的操作了
根据打开方式的不同能够执行的操作会有相应的差异.
打开文件的方式:
r,w,a
r+,w+,a+
rb,wb,ab
r+b,w+b,a+b
默认使用的是r(只读模式)
|
1
2
3
4
5
6
7
|
f = open(‘护士少妇萝莉‘,mode=‘r‘,encoding=‘utf-8‘)content = f.read()print(content)f.close()结果:标题很好 |
上边的内容open()函数打开护士少妇萝莉的文件,然后赋值到一个句柄中,open函数中的mode是对这个文件操作是的一种模式
encoding这个是指定文件中内容的编码集,接下来的操作就完全通过句柄来操作
|
1
2
3
4
5
6
7
|
f = open(‘护士少妇萝莉‘,mode=‘rb‘)content = f.read()print(content)f.close()结果:b‘\xe6\xa0\x87\xe9\xa2\x98\xe5\xbe\x88\xe5\xa5\xbd‘ |
rb 读出来的数据是bytes类型,在rb模式下,不能encoding字符集
rb的作用:在读取非文本文件的时候,比如要读取mp3,图像,视频等信息的时候就需要用到rb,因为这种数据是没办法直接显示出来的
在后面我们文件上传下载的时候还会用到.
1.绝对路径:从磁盘根目录开始一直到文件名
2.相对路径:用一个文件夹下的文件,相对于当前这个程序所在的文件而言.如果在同一个文件中,则相对路劲就是这个文件名.如果再上一层文件夹则要使用../
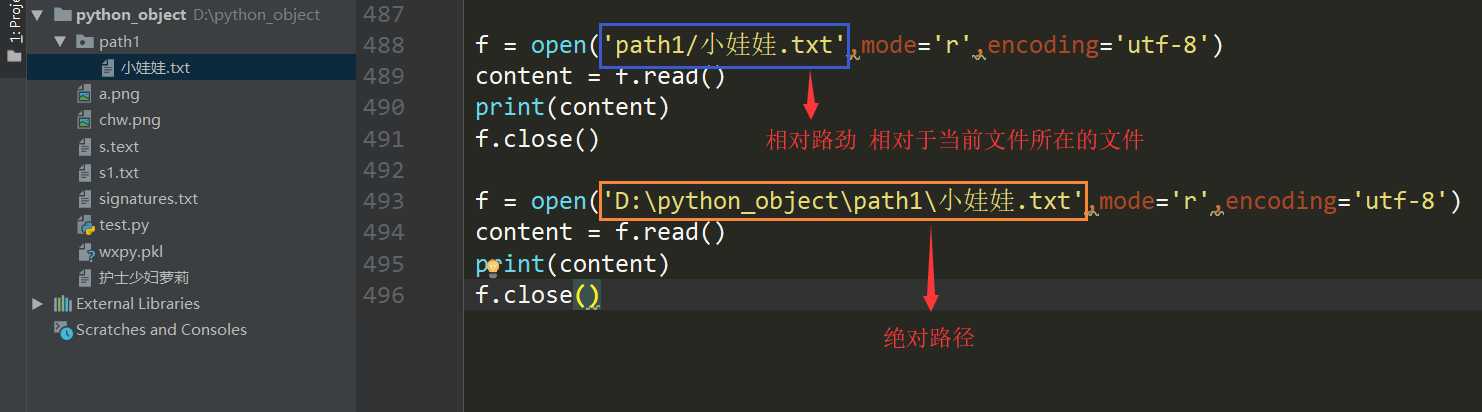
如果相对还是不能理解,来看下这列子:
你朋友要来找你,知道你在那个楼那一层但是不知道那个一个屋,现在你朋友来到这个楼里相对他知道的这一层然后开始找你在那个房间
这种操作就是相对路劲,例子中是通过这个楼中的这一层开始寻找,也就是相对于这个楼的某一层
我们更推荐大家使用相对路劲,因为我把这个程序的整个文件发给你的时候,就可以运行,如果使用绝对路径还需要额外的拷贝外部文件给你
read()将文件中的内容全部读取出来;弊端 如果文件很大就会非常的占用内存,容易导致内存奔溃
|
1
2
3
4
5
6
7
8
9
10
11
|
f = open(‘path1/小娃娃.txt‘,mode=‘r‘,encoding=‘utf-8‘)msg = f.read()f.close()print(msg)结果:高圆圆刘亦菲张柏芝杨紫王菲 |
read()读取的时候指定读取到什么位置,我们指定先读取前三个内容,然后在使用read()进行读取会继续向后读取,而不会从头开始读取
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
f = open(‘path1/小娃娃.txt‘,mode=‘r‘,encoding=‘utf-8‘)msg = f.read(3)msg1 = f.read()f.close()print(msg)print(msg1)<br>结果:高圆圆刘亦菲张柏芝杨紫王菲 |
上边现在使用的是r模式这样读取的就是文字,如果使用rb模式读取出来的就是字节
|
1
2
3
4
5
6
7
8
9
10
|
f = open(‘path1/小娃娃.txt‘,mode=‘rb‘)msg = f.read(3)msg1 = f.read()f.close()print(msg)print(msg1)结果:b‘\xe9\xab\x98‘b‘\xe5\x9c\x86\xe5\x9c\x86\r\n\xe5\x88\x98\xe4\xba\xa6\xe8\x8f\xb2\r\n\xe5\xbc\xa0\xe6\x9f\x8f\xe8\x8a\x9d\r\n\xe6\x9d\xa8\xe7\xb4\xab\r\n\xe7\x8e\x8b\xe8\x8f\xb2‘ |
readline()读取每次只读取一行,注意点:readline()读取出来的数据在后面都有一个\n
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
f = open(‘path1/小娃娃.txt‘,mode=‘r‘,encoding=‘utf-8‘)msg1 = f.readline()msg2 = f.readline()msg3 = f.readline()msg4 = f.readline()f.close()print(msg1)print(msg2)print(msg3)print(msg4)结果:高圆圆刘亦菲张柏芝杨紫Process finished with exit code 0 |
解决这个问题只需要在我们读取出来的文件后边加一个strip()就OK了
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
f = open(‘path1/小娃娃.txt‘,mode=‘r‘,encoding=‘utf-8‘)msg1 = f.readline().strip()msg2 = f.readline().strip()msg3 = f.readline().strip()msg4 = f.readline().strip()f.close()print(msg1)print(msg2)print(msg3)print(msg4)结果:高圆圆刘亦菲张柏芝杨紫 |
如果有个较大的文件我们进行读取不推荐使用以下方法:
|
1
2
|
f = open(‘../path1/弟子规‘,mode=‘r‘,encoding=‘utf-8‘)print(f.read()) #这样就是将文件一次性全部读取到内存中,内存容易奔溃 |
推荐使用的是这种方法:
|
1
2
3
4
5
6
7
8
|
f = open(‘../path1/弟子规‘,mode=‘r‘,encoding=‘utf-8‘)for line in f: print(line) #这种方式就是在一行一行的进行读取,它就执行了下边的功能print(f.readline())print(f.readline())print(f.readline())print(f.readline()) |
注意点:读完的文件句柄一定要关闭
在写文件的时候我们要养成一个写完文件就刷新的习惯. 刷新flush()
|
1
2
3
4
5
6
|
f = open(‘../path1/小娃娃.txt‘,mode=‘w‘,encoding=‘utf-8‘)f.write(‘太白很白‘)<br>f.flush()f.close()结果:当我选择使用w模式的时候,在打开文件的时候就就会把文件中的所有内容都清空,然后在操作 |
注意点:如果文件不存在使用w模式会创建文件,文件存在w模式是覆盖写,在打开文件时会把文件中所有的内容清空.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
f1 = open(‘../path1/小娃娃.txt‘,mode=‘r‘,encoding=‘utf-8‘)msg = f1.read()print(msg)# 这个是先查看小娃娃文件中有哪些内容f = open(‘../path1/小娃娃.txt‘,mode=‘w‘,encoding=‘utf-8‘)f.write(‘太白很白‘)<br>f.flush()f.close()# 这个是对小娃娃文件进行覆盖写操作f1 = open(‘../path1/小娃娃.txt‘,mode=‘r‘,encoding=‘utf-8‘)msg = f1.read()print(msg)# 查看覆盖写后的内容 |
尝试读一读
|
1
2
3
4
5
6
7
8
9
|
f1 = open(‘../path1/小娃娃.txt‘,mode=‘w‘,encoding=‘utf-8‘)msg = f1.read()print(msg)结果:Traceback (most recent call last): File "D:/python_object/path2/test.py", line 563, in <module> msg = f1.read()io.UnsupportedOperation: not readable #模式是w,不可以执行读操作 |
wb模式下,不可以指定打开文件的编辑,但是写文件的时候必须将字符串转换成utf-8的bytes数据
|
1
2
3
4
5
|
f = open(‘../path1/小娃娃.txt‘,mode=‘wb‘)msg = ‘你好‘.encode(‘utf-8‘)f.write(msg)f.flush() # 刷新f.close() |
只要是a或者ab,a+都是在文件的末尾写入,不论光标在任何位置.
在追加模式下,我们写入的内容后追加在文件的末尾
|
1
2
|
f1 = open(‘../path1/小娃娃.txt‘,mode=‘a‘,encoding=‘utf-8‘)msg = f1.write(‘这支烟灭了以后‘) |
上图是没有追加的图片

上图是追加后的图片
ab这个模式,自己试一下就好了
对于读写模式,必须是先读后写,因为光标默认在开头位置,当读完了以后再进行写入.我们以后使用频率最高的模式就是r+
看下正确的操作:
|
1
2
3
4
5
6
|
f1 = open(‘../path1/小娃娃.txt‘,mode=‘r+‘,encoding=‘utf-8‘)msg = f1.read()f1.write(‘这支烟灭了以后‘)f1.flush()f1.close()print(msg)<br>结果:<br>正常的读取之后,写在结尾 |
看下错误的操作:
|
1
2
3
4
5
6
7
8
9
|
f1 = open(‘../path1/小娃娃.txt‘,mode=‘r+‘,encoding=‘utf-8‘)f1.write(‘小鬼‘)msg = f1.read()f1.flush()f1.close()print(msg)结果:这样写会把小鬼写在开头,并且读出来的是小鬼之后的内容 |
r+模式一定要记住是先读后写
深坑请注意: 在r+模式下. 如果读取了内容. 不论读取内容多少. 光标显示的是多少. 再写入
或者操作文件的时候都是在结尾进行的操作.
先将所有的内容清空,然后写入.最后读取.但是读取的内容是空的,不常用
|
1
2
3
4
5
6
|
f1 = open(‘../path1/小娃娃.txt‘,mode=‘w+‘,encoding=‘utf-8‘)f1.write(‘小鬼‘)msg = f1.read()f1.flush()f1.close()print(msg) |
有人说,先读在写不就行了.w+模式下 其实和w模式一样,把文件清空了,在写的内容.所以很少人用
a+模式下,不论是先读还是后读,都是读不到数据的
|
1
2
3
4
5
6
|
f = open(‘../path1/小娃娃.txt‘,mode=‘a+‘,encoding=‘utf-8‘)f.write(‘阿刁‘)f.flush()msg = f.read()f.close()print(msg) |
还有几个带b的模式,其实就是对字节的一些操作,就不多叙述了.
seek()
seek(n)光标移动到n位置,注意: 移动单位是byte,所有如果是utf-8的中文部分要是3的倍数
通常我们使用seek都是移动到开头或者结尾
移动到开头:seek(0)
移动到结尾:seek(0,2) seek的第二个参数表示的是从哪个位置进行偏移,默认是0,表示开头,1表示当前位置,2表示结尾
|
1
2
3
4
5
6
7
8
9
10
11
12
|
f = open("小娃娃", mode="r+", encoding="utf-8")f.seek(0) # 光标移动到开头content = f.read() # 读取内容, 此时光标移动到结尾print(content)f.seek(0) # 再次将光标移动到开头f.seek(0, 2) # 将光标移动到结尾content2 = f.read() # 读取内容. 什么都没有print(content2)f.seek(0) # 移动到开头f.write("张国荣") # 写入信息. 此时光标在9 中文3 * 3个 = 9f.flush()f.close() |
tell()
使用tell()可以帮我们获取当前光标在什么位置
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
f = open("小娃娃", mode="r+", encoding="utf-8")f.seek(0) # 光标移动到开头content = f.read() # 读取内容, 此时光标移动到结尾print(content)f.seek(0) # 再次将光标移动到开头f.seek(0, 2) # 将光标移动到结尾content2 = f.read() # 读取内容. 什么都没有print(content2)f.seek(0) # 移动到开头f.write("张国荣") # 写入信息. 此时光标在9 中?文3 * 3个 = 9print(f.tell()) # 光标位置9f.flush()f.close() |
truncate() 截断文件
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
f = open("小娃娃", mode="w", encoding="utf-8")f.write("哈哈") # 写入两个字符f.seek(3) # 光标移动到3, 也就是两个字中间f.truncate() # 删掉光标后面的所有内容f.close()f = open("小娃娃", mode="r+", encoding="utf-8")content = f.read(3) # 读取9个字符f.seek(4)print(f.tell())f.truncate() # 后面的所有内容全部都删掉# print(content)f.flush()f.close() |
所以如果想做截断操作. 记住了. 要先挪动光标. 挪动到你想要截断的位置. 然后再进行截断
关于truncate(n), 如果给出了n. 则从开头进行截断, 如果不给n, 则从当前位置截断. 后?面
的内容将会被删除
文件修改: 只能将文件中的内容读取到内存中, 将信息修改完毕, 然后将源文件删除, 将新文件的名字改成老文件的名字.
|
1
2
3
4
5
6
7
8
|
import oswith open("../path1/小娃娃", mode="r", encoding="utf-8") as f1,\open("../path1/小娃娃_new", mode="w", encoding="UTF-8") as f2: content = f1.read() new_content = content.replace("冰糖葫芦", "?白梨") f2.write(new_content)os.remove("../path1/小娃娃") # 删除源文件os.rename("../path1/小娃娃_new", "小娃娃") # 重命名新?文件 |
弊端: ?一次将所有内容进?行行读取. 内存溢出. 解决?方案: ?一?行行?一?行行的读取和操作
|
1
2
3
4
5
6
7
8
|
import oswith open("?小娃娃", mode="r", encoding="utf-8") as f1,\open("?小娃娃_new", mode="w", encoding="UTF-8") as f2: for line in f1: new_line = line.replace("?大?白梨梨", "冰糖葫芦") f2.write(new_line)os.remove("?小娃娃") # 删除源?文件os.rename("?小娃娃_new", "?小娃娃") # 重命名新?文件 |
标签:back 字节 open() 使用 ESS ack 文件上传 编辑 修改
原文地址:https://www.cnblogs.com/hard-up/p/9892510.html