标签:git table pack efault end 通过 ges items method
RGui的arules程序包里含有Groceries数据集,该数据集是某个杂货店一个月真实的交易记录,共有9835条消费记录,169个商品

#install.packages("arules") library(arules) setwd(‘D:\\data‘) #读入数据 #Groceries数据集 Groceries groceries<-read.transactions("groceries.txt",format="basket",sep=",") #查看groceries中的数据 summary(groceries) class(groceries) groceries dim(groceries) colnames(groceries)[1:5] #rownames(groceries)[1:5] basketSize<-size(groceries) summary(basketSize) sum(basketSize) #size函数和itemFrequency函数都是arules包中的函数,前者是为了计算购物篮里商品数量,后者是为了计算每种商品的支持度 itemFreq<-itemFrequency(groceries) itemFreq[1:5] sum(itemFreq) itemCount<-(itemFreq/sum(itemFreq))*sum(basketSize) summary(itemCount) #按支持度itemFrequency排序,查看支持度的最大值 orderedItem<-sort(itemCount,decreasing=T) orderedItem[1:10] orderedItemFreq<-sort(itemFrequency(groceries),decreasing=T) orderedItemFreq[1:10] #切除第100行到800行,计算第1列到第3列的支持度 itemFrequency(groceries[100:800,1:3]) #itemFrequencyPlot 画频繁项的图 #按最小支持度查看 itemFrequencyPlot(groceries,support=0.1) #按照排序查看 itemFrequencyPlot(groceries,topN=10,horiz=T) #只关心购买两件商品以上的交易 groceries_use<-groceries[basketSize>1] dim(groceries_use) inspect(groceries[1:5]) #一个点代表在某个transaction上购买了item。 image(groceries[1:10]) #当数据集很大的时候,这张稀疏矩阵图是很难展现的,一般可以用sample函数进行采样显示 image(sample(groceries,100)) groceryrules<-apriori(groceries,parameter=list(support=0.03,confidence=0.25,minlen=2)) summary(groceryrules) #inspect查看具体的规则 inspect(groceryrules[1:5]) inspect(groceryrules) #按照某种度量,对规则进行排序。 ordered_groceryrules<-sort(groceryrules,by="lift") inspect(ordered_groceryrules[1:5]) yogurtrules<-subset(groceryrules,items%in%c("yogurt")) inspect(yogurtrules) fruitrules<-subset(groceryrules,items%pin%c("fruit")) inspect(fruitrules) byrules<-subset(groceryrules,items%ain%c("berries","yogurt")) inspect(byrules) fruitrules<-subset(groceryrules,items%pin%c("fruit")&lift>2) inspect(fruitrules) berriesInLHS<-apriori(groceries,parameter=list(support=0.001,confidence=0.1),appearance=list(lhs=c("berries"),default="rhs")) summary(berriesInLHS) inspect(berriesInLHS) inspect(head(rhs(berriesInLHS),n=5)) berrySub<-subset(berriesInLHS,subset=!(rhs%in%c("root vegetables","whole milk"))) inspect(head(rhs(sort(berrySub,by="confidence")),n=5)) write(groceryrules,file="groceryrules.csv",sep=",",quote=TRUE,row.names=FALSE) groceryrules_df<-as(groceryrules,"data.frame") str(groceryrules_df) data(Groceries) summary(Groceries) print(levels(itemInfo(Groceries)[["level1"]])) print(levels(itemInfo(Groceries)[["level2"]])) inspect(Groceries[1:3]) groceries=aggregate(Groceries,itemInfo(Groceries)[["level2"]]) inspect(groceries[1:3]) itemFrequencyPlot(Groceries,support=0.025,cex.names=0.8,xlim=c(0,0.3), type="relative",horiz=TRUE,col="darkred",las=1, xlab=paste("ProportionofMarketBasketsContainingItem", "\n(ItemRelativeFrequencyorSupport)")) second.rules<-apriori(groceries,parameter=list(support=0.025,confidence=0.05)) print(summary(second.rules)) install.packages("RColorBrewer") install.packages("arulesViz") #library(RColorBrewer) #library(arulesViz) inspect(second.rules) plot(second.rules,control=list(jitter=2,col=rev(brewer.pal(9,"Greens")[4:9])),shading="lift") plot(second.rules,measure="confidence",method="graph",control=list(type="items"),shading="lift") plot(second.rules,method="grouped",control=list(col=rev(brewer.pal(9,"Greens")[4:9]))) groceryrules.eclat<-eclat(groceries,parameter=list(support=0.05,minlen=2)) summary(groceryrules.eclat) inspect(groceryrules.eclat)
查看groceries中的数据
> summary(groceries) transactions as itemMatrix in sparse format with 9835 rows (elements/itemsets/transactions) and 169 columns (items) and a density of 0.02609146 most frequent items: whole milk other vegetables rolls/buns soda yogurt (Other) 2513 1903 1809 1715 1372 34055 element (itemset/transaction) length distribution: sizes 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 2159 1643 1299 1005 855 645 545 438 350 246 182 117 78 77 55 46 29 14 14 9 11 4 6 24 26 27 28 29 32 1 1 1 1 3 1 Min. 1st Qu. Median Mean 3rd Qu. Max. 1.000 2.000 3.000 4.409 6.000 32.000 includes extended item information - examples: labels 1 abrasive cleaner 2 artif. sweetener 3 baby cosmetics > class(groceries) [1] "transactions" attr(,"package") [1] "arules" > groceries transactions in sparse format with 9835 transactions (rows) and 169 items (columns) > dim(groceries) [1] 9835 169
对groceries中的数据进行统计
> colnames(groceries)[1:5] [1] "abrasive cleaner" "artif. sweetener" "baby cosmetics" "baby food" "bags" > #rownames(groceries)[1:5] > basketSize<-size(groceries) > summary(basketSize) Min. 1st Qu. Median Mean 3rd Qu. Max. 1.000 2.000 3.000 4.409 6.000 32.000 > sum(basketSize) [1] 43367
统计groceries数据中的支持度
> itemFreq<-itemFrequency(groceries) > itemFreq[1:5] abrasive cleaner artif. sweetener baby cosmetics baby food bags 0.0035587189 0.0032536858 0.0006100661 0.0001016777 0.0004067107 > sum(itemFreq) [1] 4.409456 #代表"平均一个transaction购买的item个数"
#查看basketSize的分布:密度曲线(TO ADD HERE) > itemCount<-(itemFreq/sum(itemFreq))*sum(basketSize) > summary(itemCount) Min. 1st Qu. Median Mean 3rd Qu. Max. 1.0 38.0 103.0 256.6 305.0 2513.0
按支持度itemFrequency排序,查看支持度的最大值
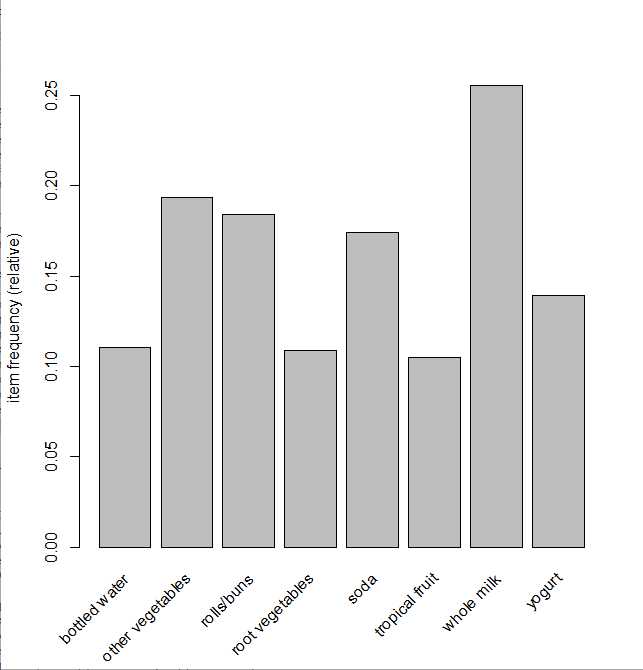
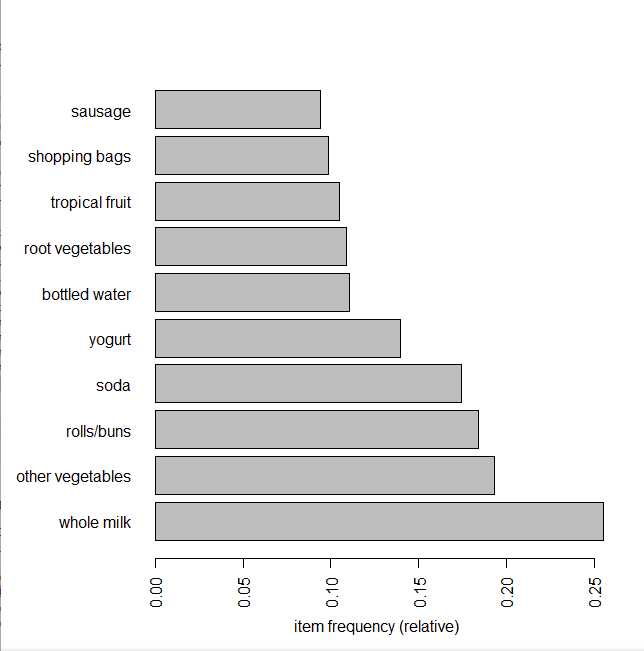
> orderedItem<-sort(itemCount,decreasing=T) > orderedItem[1:10] whole milk other vegetables rolls/buns soda yogurt bottled water 2513 1903 1809 1715 1372 1087 root vegetables tropical fruit shopping bags sausage 1072 1032 969 924 > orderedItemFreq<-sort(itemFrequency(groceries),decreasing=T) > orderedItemFreq[1:10] whole milk other vegetables rolls/buns soda yogurt bottled water 0.25551601 0.19349263 0.18393493 0.17437722 0.13950178 0.11052364 root vegetables tropical fruit shopping bags sausage 0.10899847 0.10493137 0.09852567 0.09395018 #切除第100行到800行,计算第1列到第3列的支持度 > itemFrequency(groceries[100:800,1:3]) abrasive cleaner artif. sweetener baby cosmetics 0.005706134 0.001426534 0.001426534
使用itemFrequencyPlot 画频繁项的图
#按最小支持度查看 itemFrequencyPlot(groceries,support=0.1)
#按照排序查看 itemFrequencyPlot(groceries,topN=10,horiz=T)
根据业务对数据集进行过滤,获得进一步规则挖掘的数据集
> #只关心购买两件商品以上的交易 > groceries_use<-groceries[basketSize>1] > dim(groceries_use) [1] 7676 169
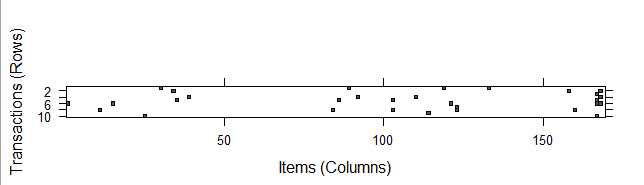
通过图形更直观观测数据的稀疏情况
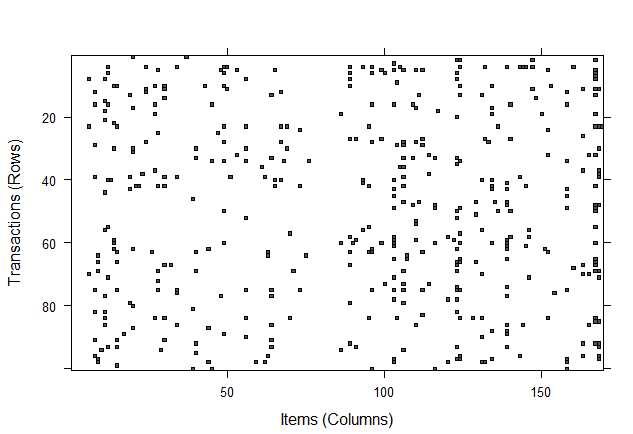
> inspect(groceries[1:5]) items [1] {citrus fruit,margarine,ready soups,semi-finished bread} [2] {coffee,tropical fruit,yogurt} [3] {whole milk} [4] {cream cheese,meat spreads,pip fruit,yogurt} [5] {condensed milk,long life bakery product,other vegetables,whole milk} #一个点代表在某个transaction上购买了item。 > image(groceries[1:10])
#当数据集很大的时候,这张稀疏矩阵图是很难展现的,一般可以用sample函数进行采样显示 image(sample(groceries,100))
apriori函数

> summary(groceryrules) set of 15 rules rule length distribution (lhs + rhs):sizes 2 15 Min. 1st Qu. Median Mean 3rd Qu. Max. 2 2 2 2 2 2 summary of quality measures: support confidence lift count Min. :0.03010 Min. :0.2929 Min. :1.205 Min. :296.0 1st Qu.:0.03274 1st Qu.:0.3185 1st Qu.:1.488 1st Qu.:322.0 Median :0.04230 Median :0.3737 Median :1.572 Median :416.0 中位数:0.04230中位数:0.3737中位数:1.572中位数:416 Mean :0.04475 Mean :0.3704 Mean :1.598 Mean :440.1 3rd Qu.:0.05247 3rd Qu.:0.4024 3rd Qu.:1.758 3rd Qu.:516.0 Max. :0.07483 Max. :0.4496 Max. :2.247 Max. :736.0 Max.:0.07483个最大值:0.4496个最大值:2.247个最大值:736 mining info: data ntransactions support confidence groceries 9835 0.03 0.25
> #inspect查看具体的规则 > inspect(groceryrules[1:5]) lhs rhs support confidence lift count [1] {whipped/sour cream} => {whole milk} 0.03223183 0.4496454 1.759754 317 [2] {pip fruit} => {whole milk} 0.03009659 0.3978495 1.557043 296 [3] {pastry} => {whole milk} 0.03324860 0.3737143 1.462587 327 [4] {citrus fruit} => {whole milk} 0.03050330 0.3685504 1.442377 300 [5] {sausage} => {rolls/buns} 0.03060498 0.3257576 1.771048 301 > inspect(groceryrules) lhs rhs support confidence lift count [1] {whipped/sour cream} => {whole milk} 0.03223183 0.4496454 1.759754 317 [2] {pip fruit} => {whole milk} 0.03009659 0.3978495 1.557043 296 [3] {pastry} => {whole milk} 0.03324860 0.3737143 1.462587 327 [4] {citrus fruit} => {whole milk} 0.03050330 0.3685504 1.442377 300 [5] {sausage} => {rolls/buns} 0.03060498 0.3257576 1.771048 301 [6] {bottled water} => {whole milk} 0.03436706 0.3109476 1.216940 338 [7] {tropical fruit} => {other vegetables} 0.03589222 0.3420543 1.767790 353 [8] {tropical fruit} => {whole milk} 0.04229792 0.4031008 1.577595 416 [9] {root vegetables} => {other vegetables} 0.04738180 0.4347015 2.246605 466 [10] {root vegetables} => {whole milk} 0.04890696 0.4486940 1.756031 481 [11] {yogurt} => {other vegetables} 0.04341637 0.3112245 1.608457 427 [12] {yogurt} => {whole milk} 0.05602440 0.4016035 1.571735 551 [13] {rolls/buns} => {whole milk} 0.05663447 0.3079049 1.205032 557 [14] {other vegetables} => {whole milk} 0.07483477 0.3867578 1.513634 736 [15] {whole milk} => {other vegetables} 0.07483477 0.2928770 1.513634 736
四. 对数据集进行评估规则
规则可以划分为3大类:
> #按照某种度量,对规则进行排序。 > ordered_groceryrules<-sort(groceryrules,by="lift") > inspect(ordered_groceryrules[1:5]) lhs rhs support confidence lift count [1] {root vegetables} => {other vegetables} 0.04738180 0.4347015 2.246605 466 [2] {sausage} => {rolls/buns} 0.03060498 0.3257576 1.771048 301 [3] {tropical fruit} => {other vegetables} 0.03589222 0.3420543 1.767790 353 [4] {whipped/sour cream} => {whole milk} 0.03223183 0.4496454 1.759754 317 [5] {root vegetables} => {whole milk} 0.04890696 0.4486940 1.756031 481
搜索规则
> yogurtrules<-subset(groceryrules,items%in%c("yogurt")) > inspect(yogurtrules) lhs rhs support confidence lift count [1] {yogurt} => {other vegetables} 0.04341637 0.3112245 1.608457 427 [2] {yogurt} => {whole milk} 0.05602440 0.4016035 1.571735 551 > fruitrules<-subset(groceryrules,items%pin%c("fruit")) > inspect(fruitrules) lhs rhs support confidence lift count [1] {pip fruit} => {whole milk} 0.03009659 0.3978495 1.557043 296 [2] {citrus fruit} => {whole milk} 0.03050330 0.3685504 1.442377 300 [3] {tropical fruit} => {other vegetables} 0.03589222 0.3420543 1.767790 353 [4] {tropical fruit} => {whole milk} 0.04229792 0.4031008 1.577595 416 > byrules<-subset(groceryrules,items%ain%c("berries","yogurt")) > inspect(byrules)
items %in% c("A", "B")表示 lhs+rhs的项集并集中,至少有一个item是在c("A", "B")。 item = Aor item = B
如果仅仅想搜索lhs或者rhs,那么用lhs或rhs替换items即可。如:lhs %in% c("yogurt")
%in%是精确匹配
%pin%是部分匹配,也就是说只要item like ‘%A%‘ or item like ‘%B%‘
%ain%是完全匹配,也就是说itemset has ’A‘ and itemset has ‘B‘
同时可以通过 条件运算符(&, |, !) 添加 support, confidence, lift的过滤条件。
> yogurtrules<-subset(groceryrules,items%in%c("yogurt")) > inspect(yogurtrules) lhs rhs support confidence lift count [1] {yogurt} => {other vegetables} 0.04341637 0.3112245 1.608457 427 [2] {yogurt} => {whole milk} 0.05602440 0.4016035 1.571735 551 > fruitrules<-subset(groceryrules,items%pin%c("fruit")) > inspect(fruitrules) lhs rhs support confidence lift count [1] {pip fruit} => {whole milk} 0.03009659 0.3978495 1.557043 296 [2] {citrus fruit} => {whole milk} 0.03050330 0.3685504 1.442377 300 [3] {tropical fruit} => {other vegetables} 0.03589222 0.3420543 1.767790 353 [4] {tropical fruit} => {whole milk} 0.04229792 0.4031008 1.577595 416 > byrules<-subset(groceryrules,items%ain%c("berries","yogurt")) > inspect(byrules) > > fruitrules<-subset(groceryrules,items%pin%c("fruit")&lift>2) > inspect(fruitrules) > berriesInLHS<-apriori(groceries,parameter=list(support=0.001,confidence=0.1),appearance=list(lhs=c("berries"),default="rhs")) Apriori Parameter specification: confidence minval smax arem aval originalSupport maxtime support minlen maxlen target ext 0.1 0.1 1 none FALSE TRUE 5 0.001 1 10 rules FALSE Algorithmic control: filter tree heap memopt load sort verbose 0.1 TRUE TRUE FALSE TRUE 2 TRUE Absolute minimum support count: 9 set item appearances ...[1 item(s)] done [0.00s]. set transactions ...[169 item(s), 9835 transaction(s)] done [0.01s]. sorting and recoding items ... [157 item(s)] done [0.00s]. creating transaction tree ... done [0.01s]. checking subsets of size 1 2 done [0.00s]. writing ... [26 rule(s)] done [0.00s]. creating S4 object ... done [0.01s]. > summary(berriesInLHS) set of 26 rules rule length distribution (lhs + rhs):sizes 1 2 8 18 Min. 1st Qu. Median Mean 3rd Qu. Max. 1.000 1.000 2.000 1.692 2.000 2.000 summary of quality measures: support confidence lift count Min. :0.003660 Min. :0.1049 Min. :1.000 Min. : 36.00 1st Qu.:0.004601 1st Qu.:0.1177 1st Qu.:1.000 1st Qu.: 45.25 Median :0.007016 Median :0.1560 Median :1.470 Median : 69.00 Mean :0.053209 Mean :0.1786 Mean :1.547 Mean : 523.31 3rd Qu.:0.107982 3rd Qu.:0.2011 3rd Qu.:1.830 3rd Qu.:1062.00 Max. :0.255516 Max. :0.3547 Max. :3.797 Max. :2513.00 mining info: data ntransactions support confidence groceries 9835 0.001 0.1 > inspect(berriesInLHS) lhs rhs support confidence lift count [1] {} => {bottled water} 0.110523640 0.1105236 1.000000 1087 [2] {} => {tropical fruit} 0.104931368 0.1049314 1.000000 1032 [3] {} => {root vegetables} 0.108998475 0.1089985 1.000000 1072 [4] {} => {soda} 0.174377224 0.1743772 1.000000 1715 [5] {} => {yogurt} 0.139501779 0.1395018 1.000000 1372 [6] {} => {rolls/buns} 0.183934926 0.1839349 1.000000 1809 [7] {} => {other vegetables} 0.193492628 0.1934926 1.000000 1903 [8] {} => {whole milk} 0.255516014 0.2555160 1.000000 2513 [9] {berries} => {beef} 0.004473818 0.1345566 2.564659 44 [10] {berries} => {butter} 0.003762074 0.1131498 2.041888 37 [11] {berries} => {domestic eggs} 0.003863752 0.1162080 1.831579 38 [12] {berries} => {fruit/vegetable juice} 0.003660397 0.1100917 1.522858 36 [13] {berries} => {whipped/sour cream} 0.009049314 0.2721713 3.796886 89 [14] {berries} => {pip fruit} 0.003762074 0.1131498 1.495738 37 [15] {berries} => {pastry} 0.004270463 0.1284404 1.443670 42 [16] {berries} => {citrus fruit} 0.005388917 0.1620795 1.958295 53 [17] {berries} => {shopping bags} 0.004982206 0.1498471 1.520894 49 [18] {berries} => {sausage} 0.004982206 0.1498471 1.594963 49 [19] {berries} => {bottled water} 0.004067107 0.1223242 1.106769 40 [20] {berries} => {tropical fruit} 0.006710727 0.2018349 1.923494 66 [21] {berries} => {root vegetables} 0.006609049 0.1987768 1.823666 65 [22] {berries} => {soda} 0.007320793 0.2201835 1.262685 72 [23] {berries} => {yogurt} 0.010574479 0.3180428 2.279848 104 [24] {berries} => {rolls/buns} 0.006609049 0.1987768 1.080691 65 [25] {berries} => {other vegetables} 0.010269446 0.3088685 1.596280 101 [26] {berries} => {whole milk} 0.011794611 0.3547401 1.388328 116 > inspect(head(rhs(berriesInLHS),n=5)) items [1] {bottled water} [2] {tropical fruit} [3] {root vegetables} [4] {soda} [5] {yogurt}
限制挖掘的item
可以控制规则的左手边或者右手边出现的item,即appearance。但尽量要放低支持度和置信度。
berrySub<-subset(berriesInLHS,subset=!(rhs%in%c("root vegetables","whole milk"))) inspect(head(rhs(sort(berrySub,by="confidence")),n=5)) write(groceryrules,file="groceryrules.csv",sep=",",quote=TRUE,row.names=FALSE) groceryrules_df<-as(groceryrules,"data.frame") str(groceryrules_df) data(Groceries) summary(Groceries) print(levels(itemInfo(Groceries)[["level1"]])) print(levels(itemInfo(Groceries)[["level2"]])) inspect(Groceries[1:3]) groceries=aggregate(Groceries,itemInfo(Groceries)[["level2"]]) inspect(groceries[1:3]) itemFrequencyPlot(Groceries,support=0.025,cex.names=0.8,xlim=c(0,0.3), type="relative",horiz=TRUE,col="darkred",las=1, xlab=paste("ProportionofMarketBasketsContainingItem", "\n(ItemRelativeFrequencyorSupport)")) second.rules<-apriori(groceries,parameter=list(support=0.025,confidence=0.05)) print(summary(second.rules))
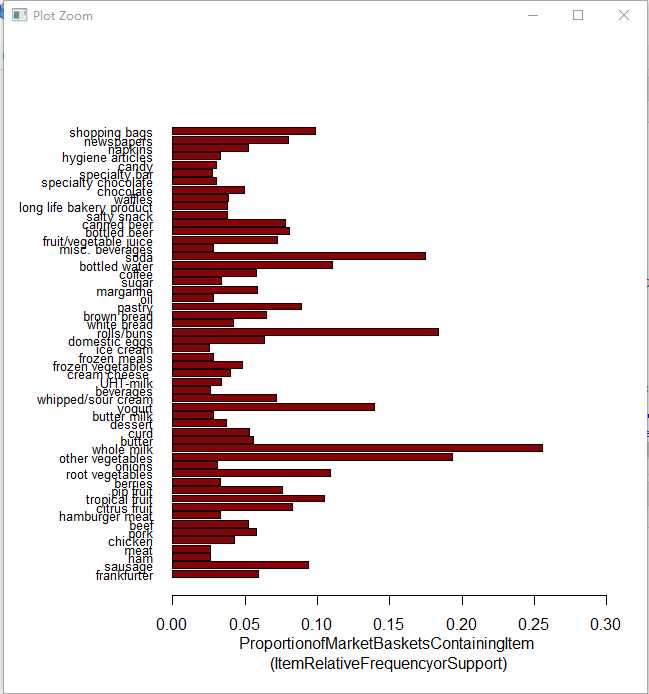
itemFrequency图
itemFrequencyPlot(Groceries, support = 0.025, cex.names=0.8, xlim = c(0,0.3), type = "relative", horiz = TRUE, col = "dark red", las = 1, xlab = paste("Proportionof Market Baskets Containing Item", "\n(Item Relative Frequency or Support)"))
horiz=TRUE: 让柱状图水平显示
cex.names=0.8:item的label(这个例子即纵轴)的大小乘以的系数。
s=1: 表示刻度的方向,1表示总是水平方向。
pe="relative": 即support的值(百分比)。如果type=absolute表示显示该item的count,而非support。默认就是relative。
扩展:
#install.packages("RColorBrewer") #install.packages("arulesViz") library(RColorBrewer) library(arulesViz) inspect(second.rules) plot(second.rules,control=list(jitter=2,col=rev(brewer.pal(9,"Greens")[4:9])),shading="lift") plot(second.rules,measure="confidence",method="graph",control=list(type="items"),shading="lift") plot(second.rules,method="grouped",control=list(col=rev(brewer.pal(9,"Greens")[4:9]))) groceryrules.eclat<-eclat(groceries,parameter=list(support=0.05,minlen=2)) summary(groceryrules.eclat) inspect(groceryrules.eclat)
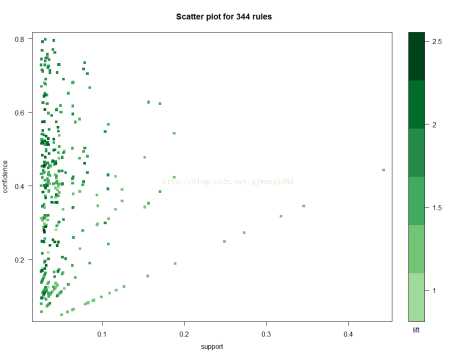
2.1 Scatter Plot
library(RColorBrewer)
library(arulesViz)
> plot(second.rules, control=list(jitter=2, col = rev(brewer.pal(9, "Greens")[4:9])), shading = "lift")
shading = "lift": 表示在散点图上颜色深浅的度量是lift。当然也可以设置为support 或者Confidence。
jitter=2:增加抖动值
col: 调色板,默认是100个颜色的灰色调色板。
brewer.pal(n, name): 创建调色板:n表示该调色板内总共有多少种颜色;name表示调色板的名字(参考help)。
这里使用Green这块调色板,引入9中颜色。
这幅散点图表示了规则的分布图:大部分规则的support在0.1以内,Confidence在0-0.8内。每个点的颜色深浅代表了lift的值。
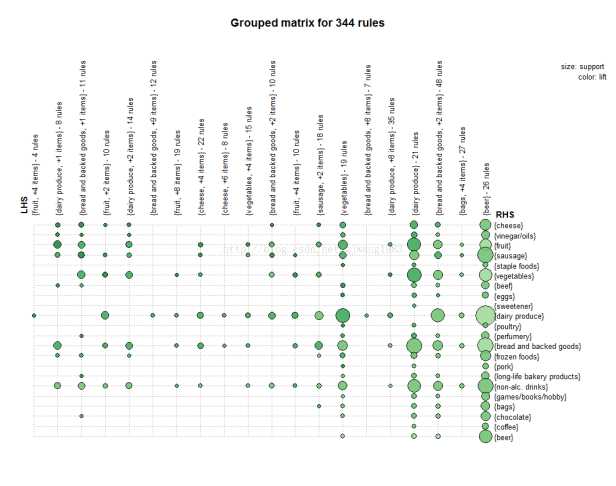
2.2 Grouped Matrix
> plot(second.rules, method="grouped", control=list(col = rev(brewer.pal(9, "Greens")[4:9])))
Grouped matrix-based visualization.
Antecedents (columns) in the matrix are grouped using clustering. Groups are represented as balloons in the matrix.
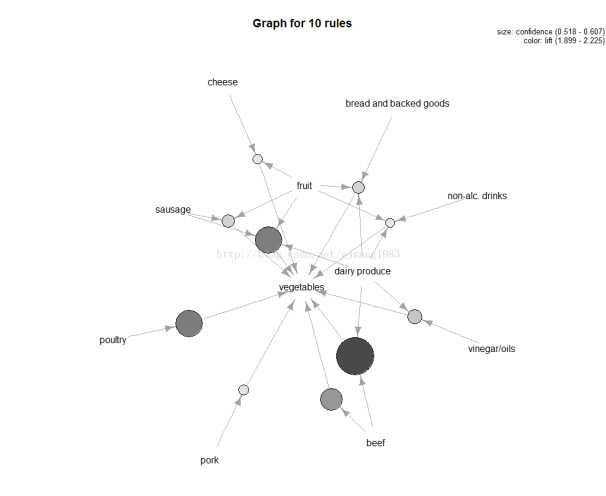
2.3 Graph
Represents the rules (or itemsets) as a graph
plot(top.vegie.rules, measure="confidence", method="graph",control=list(type="items"), shading = "lift")
type=items表示每个圆点的入度的item的集合就是LHS的itemset
measure定义了圈圈大小,默认是support
颜色深浅有shading控制
R_Studio(关联)对Groceries数据集进行关联分析
标签:git table pack efault end 通过 ges items method
原文地址:https://www.cnblogs.com/1138720556Gary/p/9893203.html
