标签:筛选 分享 通过 sel 分享图片 cti 决策 而不是 rand
一、Out of bag estimate(OOB)
1、OOB sample number
RF是bagging的一种发方法,在做有放回的bootstrap时,由抽样随机性可得到(其中1/e可由高数中的洛必达法则得到):
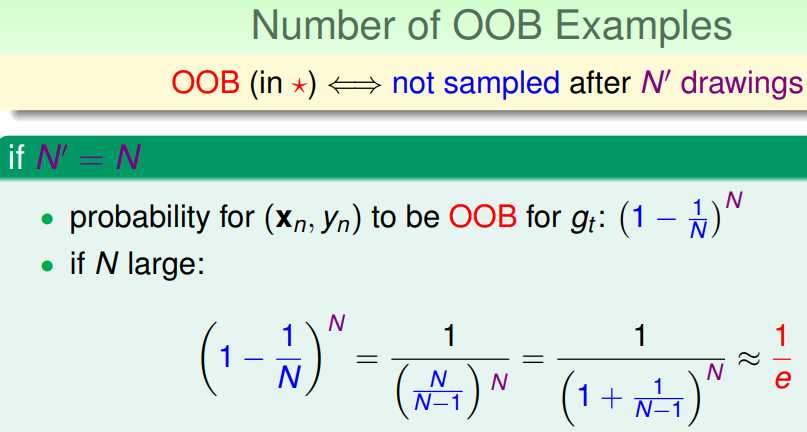
RF中每次抽样N个样本训练每一棵decision tree(gt),对于此棵树gt,原始的数据集中将有近1/e(33.3%)的样本未参与其训练;因此可以使用这部分数据对此棵树gt进行validation。(下图中红色星号表示此样本未参与某棵决策树gt训练)
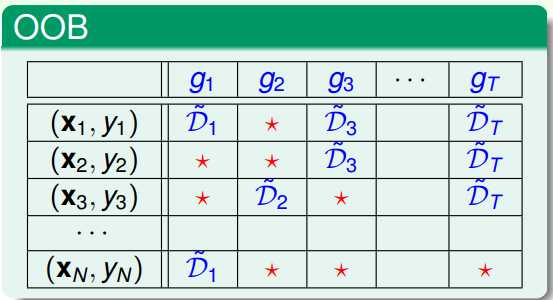
2、OOB如何做validation
RF是通过多个基学习器进行组合得到整体的性能,即基学习器性能不高但经过组合却仍可能得到高性能(三个臭皮匠,赛过诸葛亮);因此,对于RF,应当是对整体的性能进行validation,而不是依次对单个基学习器进行validation。那么,如何对一个训练好的RF进行validation呢?
具体作法:
(1)对于数据集中每一个样本(xi, yi),将所有未使用该样本(xi, yi)进行训练得到的决策树筛选出来得到几个包含部分决策树的子模型集合M;
(2)然后在样本(xi, yi)上,使用模型集合M进行误差计算,即得到使用样本(xi, yi)进行validation的结果;(此步骤与使用留一法进行validation相似)
(3)重复步骤(2),依次计算在剩余的样本中使用每个样本进行validation的结果;
(4)对所有样本进行validation的结果进行求和取平均,作为RF模型最终的validation的结果。
具体表达式如下图:
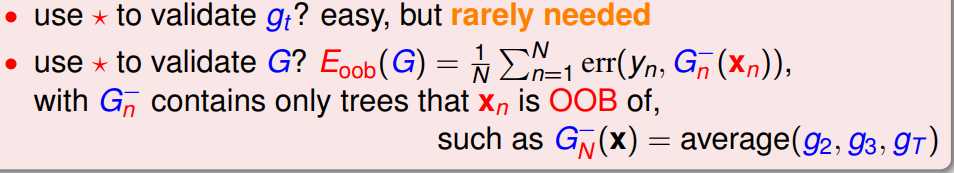
特点:不需要额外划分一部分的validation set,RF可以做self-validation
![]()
3、RF如何做Feature Selection
RandomForest的out of bag estimate 及Feature selection 具体作法
标签:筛选 分享 通过 sel 分享图片 cti 决策 而不是 rand
原文地址:https://www.cnblogs.com/xieb1994/p/9895450.html