标签:style blog http color 使用 ar strong 数据 sp
SVM(支持向量机)是机器学习算法里用得最多的一种算法。SVM最经常使用的是用于分类,只是SVM也能够用于回归,我的实验中就是用SVM来实现SVR(支持向量回归)。
对于功能这么强的算法,opencv中自然也是有集成好了,我们能够直接调用。OpenCV中的SVM算法是基于LibSVM软件包开发的,LibSVM是台湾大学林智仁(Lin Chih-Jen)等开发设计的一个简单、易于使用和高速有效的SVM模式识别与回归的软件包。
网上讲opencv中SVM使用的文章有非常多,但讲SVM參数优化的文章却非常少。所以在这里不重点讲怎么使用SVM,而是谈谈如何通过opencv中自带的库优化SVM中的各參数。
相信用SVM做过实验的人都知道,SVM的各參数对实验结果有非常大的影响,比方C,gama,P,coef等等。以下就是CvSVMParams类的原型。
C++: CvSVMParams::CvSVMParams()
C++: CvSVMParams::CvSVMParams(int svm_type,
int kernel_type,
double degree,
double gamma,
double coef0,
double Cvalue,
double nu,
double p,
CvMat* class_weights,
CvTermCriteria term_crit
)
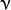 类支持向量分类机。n类似然不全然分类的分类器。參数为代替C(其值在区间【0,1】中,nu越大,决策边界越平滑)。
类支持向量分类机。n类似然不全然分类的分类器。參数为代替C(其值在区间【0,1】中,nu越大,决策边界越平滑)。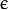 类支持向量回归机。训练集中的特征向量和拟合出来的超平面的距离须要小于p。异常值惩处因子C被採用。类支持向量回归机。 代替了 p。
类支持向量回归机。训练集中的特征向量和拟合出来的超平面的距离须要小于p。异常值惩处因子C被採用。类支持向量回归机。 代替了 p。<2>kernel_type:SVM的内核类型(4种):
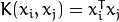 .
.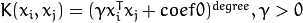 .
.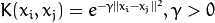 .
.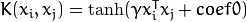 .
.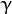 。。
。。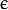 。
。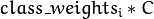 。所以这些权重影响不同类别的错误分类惩处项。权重越大,某一类别的误分类数据的惩处项就越大。
。所以这些权重影响不同类别的错误分类惩处项。权重越大,某一类别的误分类数据的惩处项就越大。CvSVMParams param; param.svm_type = CvSVM::EPS_SVR; //我的实验是用SVR作回归分析,可能大部分人的实验是用SVM来分类,方法都一样 param.kernel_type = CvSVM::RBF; param.C = 1; param.p = 5e-3; param.gamma = 0.01; param.term_crit = cvTermCriteria(CV_TERMCRIT_EPS, 100, 5e-3);
C++: bool CvSVM::train(const Mat& trainData,
const Mat& responses,
const Mat& varIdx=Mat(),
const Mat& sampleIdx=Mat(),
CvSVMParams params=CvSVMParams()
)
C++: bool CvSVM::train_auto(const Mat& trainData,
const Mat& responses,
const Mat& varIdx,
const Mat& sampleIdx,
CvSVMParams params,
int k_fold=10,
CvParamGrid Cgrid=CvSVM::get_default_grid(CvSVM::C), CvParamGrid gammaGrid=CvSVM::get_default_grid(CvSVM::GAMMA), CvParamGrid pGrid=CvSVM::get_default_grid(CvSVM::P), CvParamGrid nuGrid=CvSVM::get_default_grid(CvSVM::NU), CvParamGrid coeffGrid=CvSVM::get_default_grid(CvSVM::COEF), CvParamGrid degreeGrid=CvSVM::get_default_grid(CvSVM::DEGREE),
bool balanced=false
)
CvSVMParams param; param.svm_type = CvSVM::EPS_SVR; param.kernel_type = CvSVM::RBF; param.C = 1; //给參数赋初始值 param.p = 5e-3; //给參数赋初始值 param.gamma = 0.01; //给參数赋初始值 param.term_crit = cvTermCriteria(CV_TERMCRIT_EPS, 100, 5e-3); //对不用的參数step设为0 CvParamGrid nuGrid = CvParamGrid(1,1,0.0); CvParamGrid coeffGrid = CvParamGrid(1,1,0.0); CvParamGrid degreeGrid = CvParamGrid(1,1,0.0); CvSVM regressor; regressor.train_auto(PCA_training,tr_label,NULL,NULL,param, 10, regressor.get_default_grid(CvSVM::C), regressor.get_default_grid(CvSVM::GAMMA), regressor.get_default_grid(CvSVM::P), nuGrid, coeffGrid, degreeGrid);
CvSVMParams params_re = regressor.get_params();
regressor.save("training_srv.xml");
float C = params_re.C;
float P = params_re.p;
float gamma = params_re.gamma;
printf("\nParms: C = %f, P = %f,gamma = %f \n",C,P,gamma);标签:style blog http color 使用 ar strong 数据 sp
原文地址:http://www.cnblogs.com/hrhguanli/p/4019137.html