标签:blog 内容 脚本 学习java ·· git 平衡二叉搜索树 感悟 jpg
二叉查找树是二叉树的扩展,它绝大数方法都会用到递归,二叉查找树的平均查找深度为O(log2N).
if (!(element instanceof Comparable)),如果不是则会抛出NoComparableExceptioncomparaTo()方法与TargetElement进行比较,
ElemenNotFoundException.没有左右子节点,可以直接删除这个结点。比如删除结点20.
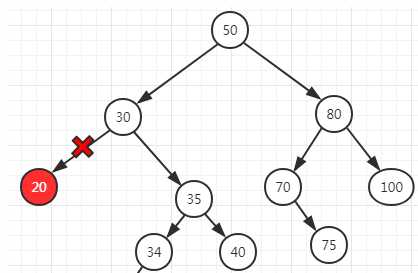
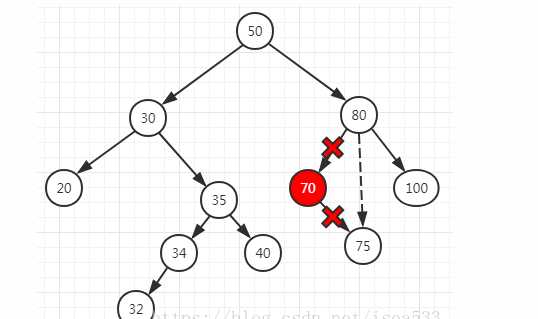
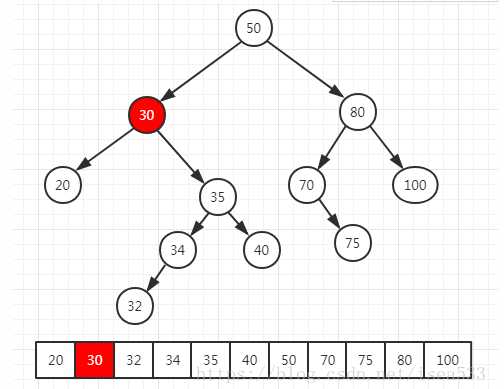
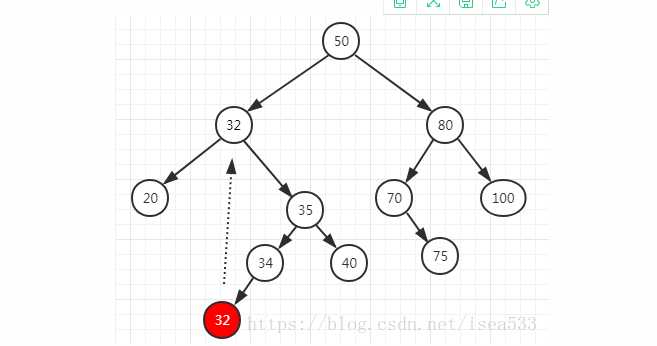
removeAllOccurrences、removeMin、removeMax、findMax、findMin方法都在:LinkedBinarySearchTree类
树的使用实现集合会让有些操作变得高效,也会让一些操作变得低效:
| 操作 | LinkList | BinarySearchTreeList |
|---|---|---|
| removeFirst | O(1) | O(n) |
| removeLast | O(n) | O(n) |
| remove | O(n) | O(n) |
| first | O(1) | O(n) |
| last | O(n) | O(n) |
| contains | O(n) | O(n) |
| isEmpty | O(1) | O(1) |
| size | O(1) | O(1) |
| add | O(n) | O(n) |
黑色加粗代表使用树后操作将变得低效。
红色字体代表该操作可能使树变得不平衡。
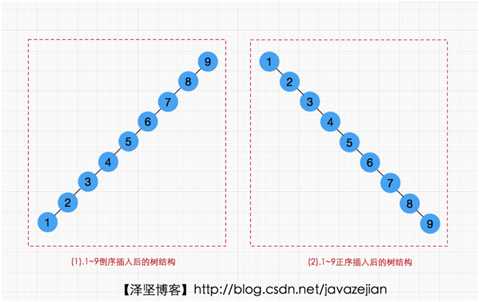
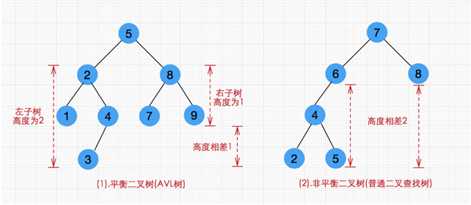
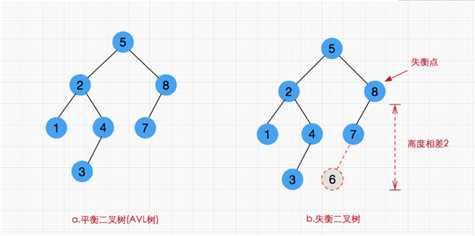
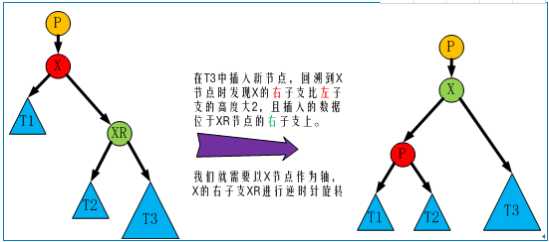
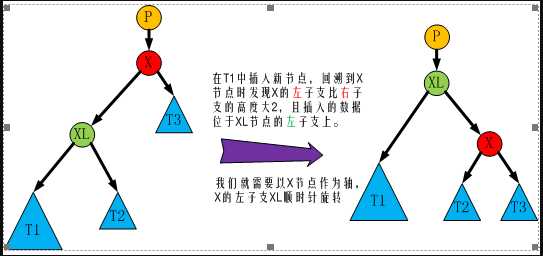
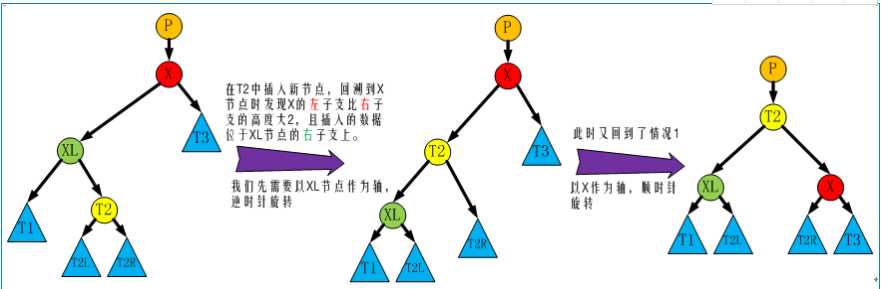
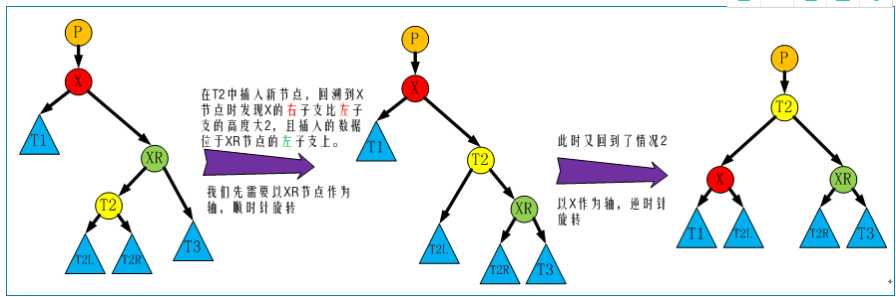
红黑树的查询性稍微逊色于AVL树,因为它比AVL树会稍微不平衡多一层,也就是说他会比AVL树多进行一次比较。
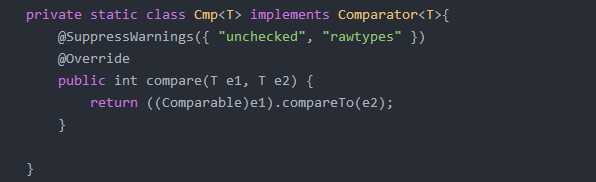
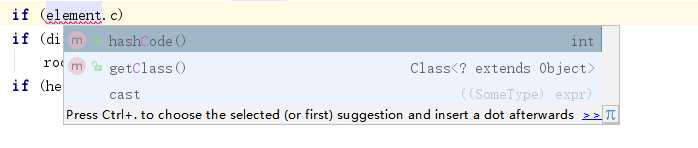
String1.comparaTO(String2)...,也就是只能比较String类型。要想比较其他类型,就得写一个比较器,其中用Compara(T value1,T value2)方法。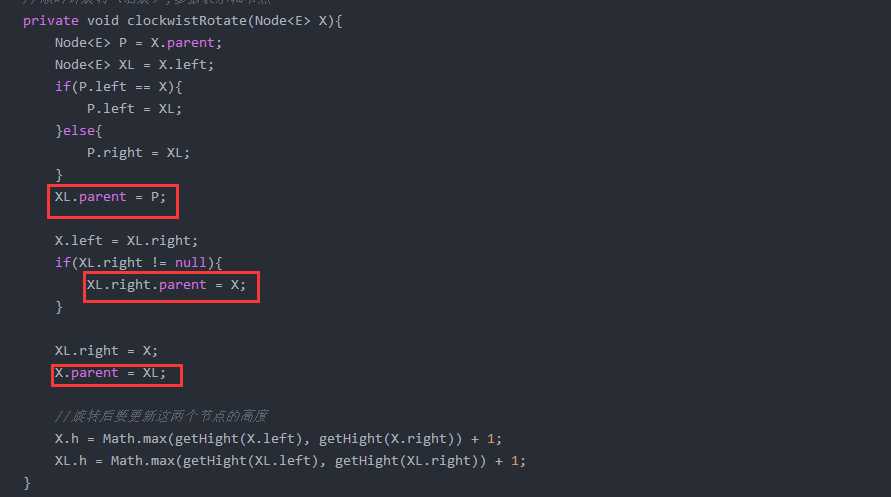

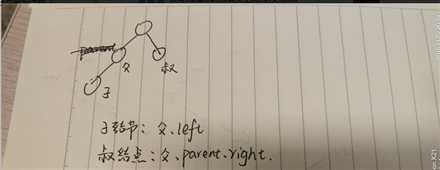
一:当添加已有结点时,后来的数据之间覆盖原来的数据,有可能人说这个没有用,在我看来,当一个节点有两个数据时,这就变得非常有用,比如这两个数据是:name、price。
已有的数据为:name:牛奶 、price:2元
后来的数据为:name:牛奶 、 price:2.5 元
一般来说、在实际生活中的应用一个节点会有很多数据,所以一般不会全部相同的。因此更新尤为重要。
二:在书中代码上,数据不会更新的。相同的元素会放在原元素的右结点上,当放上比他小的元素时,会存在于它的第一个出现的结点的左节点上。
(statistics.sh脚本的运行结果截图)
- 队友对于自己不懂得问题懂得深究,比如同学、百度。
- 队友的事比我多、学习java的效率比我高。
- 队友很细心、能够发现一些小问题。在上一章中,我说那一章很难。现在想是我错了!这个十一章是难的我脑壳都疼!特别是那个AVL、红黑树,哎。我得看代码去了····
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 260/0 | 1/1 | 05/05 | |
| 第二周 | 300/560 | 1/2 | 13/18 | |
| 第三周 | 212/772 | 1/4 | 21/39 | |
| 第四周 | 330/1112 | 2/7 | 21/60 | |
| 第五周 | 1321/2433 | 1/8 | 30/90 | |
| 第六周 | 1024/3457 | 1/9 | 20/110 | |
| 第七周 | 1024/3457 | 1/9 | 20/110 |
2017-2018 20172309 《程序设计与数据结构(下)》第七章学习总结
标签:blog 内容 脚本 学习java ·· git 平衡二叉搜索树 感悟 jpg
原文地址:https://www.cnblogs.com/dky-wzw/p/9898475.html