标签:could apt sp2 c++ 编码 capture 能力 查找 需求分析
第二次结对编程总结
成员: 陈灿 刘泽 王子博
github地址:https://github.com/USTC-ASE-P10/wf
| PSP2.1 | 任务内容 | 计划完成需要的时间(min) | 实际完成需要的时间(min) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| Estimate | 估计这个任务需要多少时间,并规划大致工作步骤 | 30 | 30 |
| Development | 开发 | 670 | 590 |
| Analysis | 需求分析 (包括学习新技术) | 20 | 30 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 (和同事审核设计文档) | 30 | 10 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| Design | 具体设计 | 40 | 40 |
| Coding | 具体编码 | 360 | 300 |
| Code Review | 代码复审 | 60 | 40 |
| est | 测试(自我测试,修改代码,提交修改) | 100 | 120 |
| Reporting | 报告 | 190 | 210 |
| Test Report | 测试报告 | 60 | 60 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结 ,并提出过程改进计划 | 100 | 120 |
| Summary | 合计 | 890 | 830 |
第0步:输出某个英文文本文件中26个字母出现的频率,由高到低排列,并显示字母出现的百分比,精确到小数点后面两位。
第一步:输出单个文件中的前 N 个最常出现的英语单词。
第二步: 支持 stop words。
第三步: 我们想看看常用的短语是什么, 怎么办呢?
第四步:把动词形态都统一之后再计数。
一开始是两人结对,一人领航,一人驾驶;后来的大部分工作,两人领航,一人驾驶。
我们的编码风格主要是PEP8,然后编码时是三个人讨论具体的实现细节,然后王子博对于我一些不合风格的写法会给予纠正,比如空格换行这些格式之类的。
我们三个人克服了一些阻碍,抽出了一定的连续时间来合作;这不是我们能做到的最好结果,因为我们的时间精力是有限的,还有很多公司的事情,生活上的事情需要处理。
刘泽:
1.脑子转得快,在先验知识比较丰富的前提下,对于很多数理逻辑问题,能给予很快的反馈
2.解决实际问题能力强
3.对新事物的学习能力很强
4.平时编码少,经验不足,我也有同样的弱点,希望能在接下来的一段时间提升自己的engineering能力
王子博:
1.对python语言有比较深刻的认识
2.领导以及表达能力优秀,能合理安排团队的工作
3.编码规范,工程能力强
4.据本人说,从未用过C++,理由好像是不接触自己无法精通的领域,我反而觉得可以多去尝试一下,不必拘泥于必须精通,尝试过程中可能会有所改观。
使用了Pycharm中profile进行性能分析,测试的配置是:
wf.py -f -n 10 C:\Users\v-checan\Desktop\pride-and-prejudice.txt
即统计pride-and-prejudice.txt中出现频率前10的单词,得到的性能分析结果:

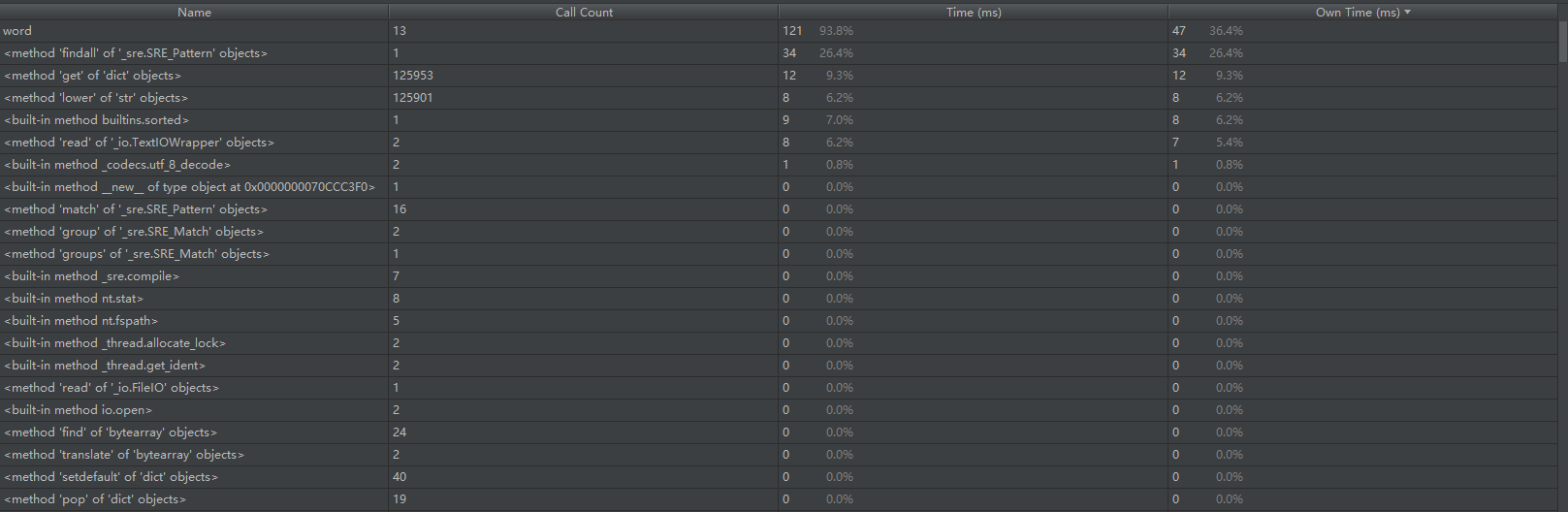
可以看到,我们的wf.py主体是main函数,main函数里面的__init__(),parse_args各占0.8%的时间,负责初始化和参数解析,显然这部分也不是我们的主体。我们在统计词频这个功能中调用最多的是word这个函数,然后我们再分析这个函数里面的情况:lower()占用6.2%的时间,sorted占用7.0%的时间,open占用0.0%的时间,read()占用6.2%的时间;真正的大头在于findall函数,我们这里采用了正则匹配的方法去找到符合我们要求的词,但是这样其实我们很难在这里面进行优化,除非我们根据文本的内容以及我们要查找的实际逻辑来重新细化写一个函数,但是这样的话,会显得很复杂。
接下是我们具体的数字形式的性能分析结果:
利用python的unitest进行我们的单元测试,具体代码可以访问我们github地址:https://github.com/USTC-ASE-P10/wf/blob/master/tests.py
标签:could apt sp2 c++ 编码 capture 能力 查找 需求分析
原文地址:https://www.cnblogs.com/moee/p/9900168.html