标签:sklearn RKE 通过 ota 挖掘 datetime 会员 ... ati
本次实战项目是关于航空公司客户价值的分析,其中用到的聚类方法是K-Means方法,属于非监督学习。
Tools :python 3.6; jupyter
os : mac os
reference: 数据分析与挖掘实战,csdn
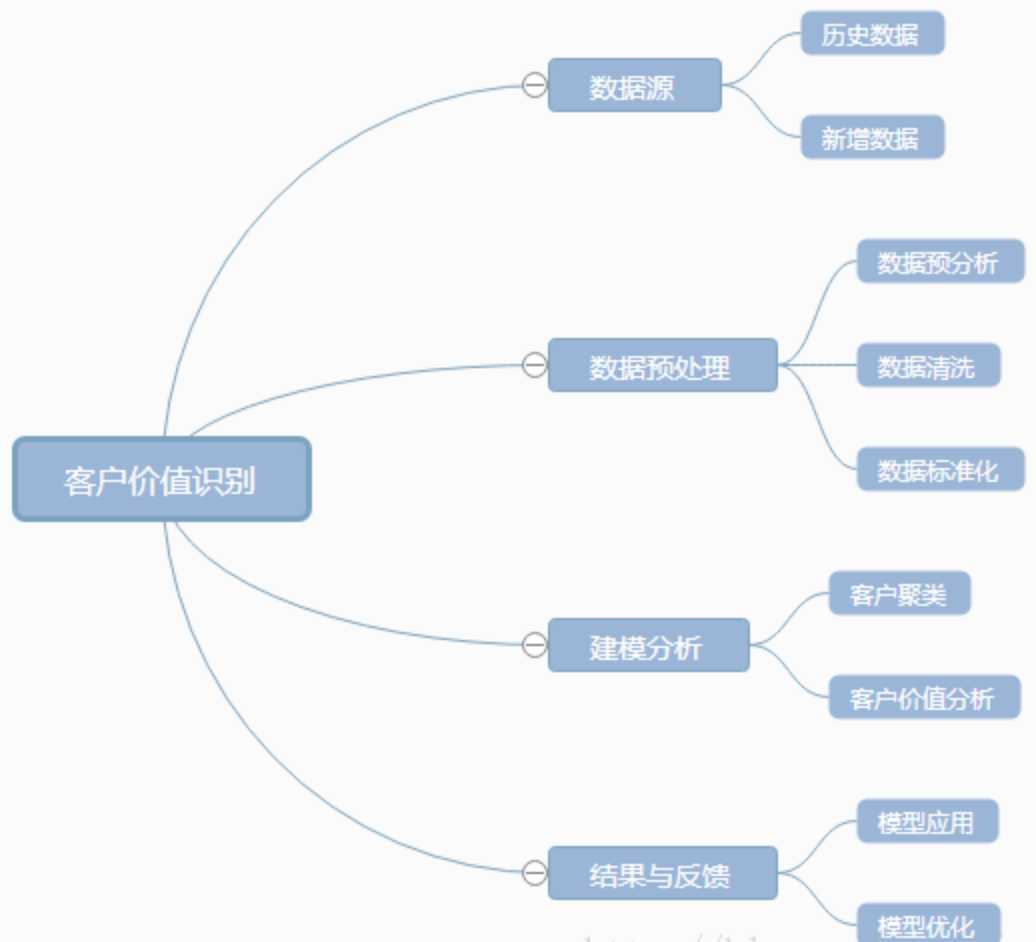
数据分析或挖掘涉及的一般步骤:
数据集中共有62988个客户的基本信息和在观测窗口内的消费积分等相关信息,其中包含了会员卡号、入会时间、性别、年龄、会员卡级别、在观测窗口内的飞行公里数、飞行时间等44个特征属性。
首先导入需要用到的库,然后概览数据集,并进行数据预处理:
1 import pandas as pd 2 import numpy as np 3 from sklearn.cluster import KMeans 4 import matplotlib.pyplot as plt 5 6 datafile = "/Volumes/win/sj/dataset/air_data.csv" 7 data = pd.read_csv(datafile, encoding="utf-8") 8 print(data.shape) 9 print(data.info())
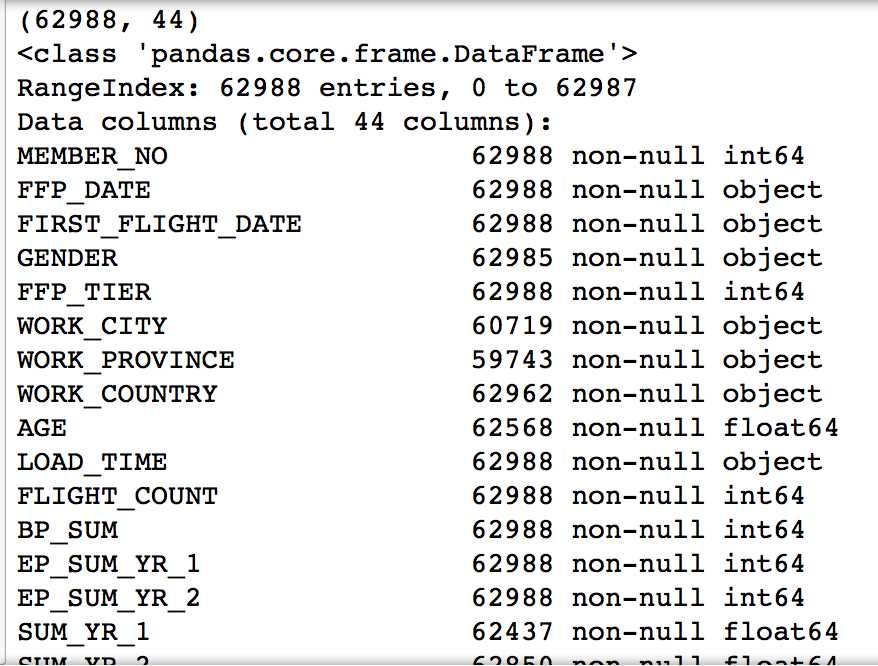
MEMBER_NO FFP_DATE FIRST_FLIGHT_DATE GENDER FFP_TIER WORK_CITY 0 54993 2006/11/02 2008/12/24 男 6 . 1 28065 2007/02/19 2007/08/03 男 6 NaN 2 55106 2007/02/01 2007/08/30 男 6 . 3 21189 2008/08/22 2008/08/23 男 5 Los Angeles 4 39546 2009/04/10 2009/04/15 男 6 贵阳 WORK_PROVINCE WORK_COUNTRY AGE LOAD_TIME ... 0 北京 CN 31.0 2014/03/31 ... 1 北京 CN 42.0 2014/03/31 ... 2 北京 CN 40.0 2014/03/31 ... 3 CA US 64.0 2014/03/31 ... 4 贵州 CN 48.0 2014/03/31 ... ADD_Point_SUM Eli_Add_Point_Sum L1Y_ELi_Add_Points Points_Sum 0 39992 114452 111100 619760 1 12000 53288 53288 415768 2 15491 55202 51711 406361 3 0 34890 34890 372204 4 22704 64969 64969 338813 L1Y_Points_Sum Ration_L1Y_Flight_Count Ration_P1Y_Flight_Count 0 370211 0.509524 0.490476 1 238410 0.514286 0.485714 2 233798 0.518519 0.481481 3 186100 0.434783 0.565217 4 210365 0.532895 0.467105 Ration_P1Y_BPS Ration_L1Y_BPS Point_NotFlight 0 0.487221 0.512777 50 1 0.489289 0.510708 33 2 0.481467 0.518530 26 3 0.551722 0.448275 12 4 0.469054 0.530943 39 [5 rows x 44 columns]
对原始数据进行预分析,主要排查缺失值和异常值。分析原始数据的缺失值和异常值,根据分析结果,在数据处理阶段中进行相应处理。
处理方法:满足清洗条件的一行数据全部丢弃。
1 data = data[data["SUM_YR_1"].notnull() & data["SUM_YR_2"].notnull()] 2 index1 = data["SUM_YR_1"] != 0 3 index2 = data["SUM_YR_2"] != 0 4 index3 = (data["SEG_KM_SUM"] == 0) & (data["avg_discount"] == 0) 5 data = data[index1 | index2| index3] 6 print(data.shape)
删除后剩余的样本值是62044个,可见异常样本的比例极少,不会对分析果产生较大的影响。
原始数据集的特征属性太多,而且各属性不具有降维的特征,故这里选取几个对航空公司来说比较有价值的几个特征进行分析,
最终选取的特征是第一年总票价、第二年总票价、观测窗口总飞行公里数、飞行次数、平均乘机时间间隔、观察窗口内最大乘机间隔、入会时间、观测窗口的结束时间、平均折扣率这八个特征。
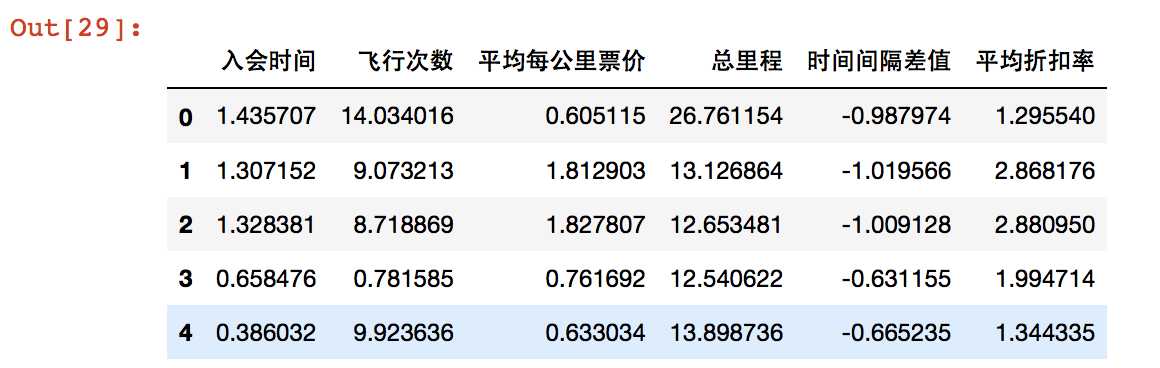
1 data["LOAD_TIME"] = pd.to_datetime(data["LOAD_TIME"]) 2 data["FFP_DATE"] = pd.to_datetime(data["FFP_DATE"]) 3 data["入会时间"] = data["LOAD_TIME"] - data["FFP_DATE"] 4 data["平均每公里票价"] = (data["SUM_YR_1"] + data["SUM_YR_2"]) / data["SEG_KM_SUM"] 5 data["时间间隔差值"] = data["MAX_INTERVAL"] - data["AVG_INTERVAL"] 6 deal_data = data.rename( 7 columns = {"FLIGHT_COUNT" : "飞行次数", "SEG_KM_SUM" : "总里程", "avg_discount" : "平均折扣率"}, 8 inplace = False 9 ) 10 filter_data = deal_data[["入会时间", "飞行次数", "平均每公里票价", "总里程", "时间间隔差值", "平均折扣率"]] 11 print(filter_data[0:5]) 12 filter_data[‘入会时间‘] = filter_data[‘入会时间‘].astype(np.int64)/(60*60*24*10**9) 13 print(filter_data[0:5]) 14 print(filter_data.info())
入会时间 飞行次数 平均每公里票价 总里程 时间间隔差值 平均折扣率
0 2706 days 210 0.815798 580717 14.516746 0.961639
1 2597 days 140 1.154043 293678 11.805755 1.252314
2 2615 days 135 1.158217 283712 12.701493 1.254676
3 2047 days 23 0.859648 281336 45.136364 1.090870
4 1816 days 152 0.823617 309928 42.211921 0.970658
入会时间 飞行次数 平均每公里票价 总里程 时间间隔差值 平均折扣率
0 2706.0 210 0.815798 580717 14.516746 0.961639
1 2597.0 140 1.154043 293678 11.805755 1.252314
2 2615.0 135 1.158217 283712 12.701493 1.254676
3 2047.0 23 0.859648 281336 45.136364 1.090870
4 1816.0 152 0.823617 309928 42.211921 0.970658
<class ‘pandas.core.frame.DataFrame‘>
Int64Index: 62044 entries, 0 to 62978
Data columns (total 6 columns):
入会时间 62044 non-null float64
飞行次数 62044 non-null int64
平均每公里票价 62044 non-null float64
总里程 62044 non-null int64
时间间隔差值 62044 non-null float64
平均折扣率 62044 non-null float64
dtypes: float64(4), int64(2)
memory usage: 3.3 MB
None
1 filter_zscore_data = (filter_data - filter_data.mean(axis=0))/(filter_data.std(axis=0)) 2 filter_zscore_data[0:5]
对于K-Means方法,k的取值是一个难点,因为是无监督的聚类分析问题,所以不寻在绝对正确的值,需要进行研究试探。这里采用计算SSE的方法,尝试找到最好的K数值。
1 def distEclud(vecA, vecB): 2 """ 3 计算两个向量的欧式距离的平方,并返回 4 """ 5 return np.sum(np.power(vecA - vecB, 2)) 6 7 def test_Kmeans_nclusters(data_train): 8 """ 9 计算不同的k值时,SSE的大小变化 10 """ 11 # print(data_train) 12 data_train = data_train.values 13 # print(data_train) 14 nums=range(2,10) 15 SSE = [] 16 for num in nums: 17 sse = 0 18 kmodel = KMeans(n_clusters=num, n_jobs=4) 19 kmodel.fit(data_train) 20 # 簇中心 21 cluster_ceter_list = kmodel.cluster_centers_ 22 # print("1.ceter_list:",cluster_ceter_list) 23 # 个样本属于的簇序号列表 24 cluster_list = kmodel.labels_.tolist() 25 # print("2.cluster_list:",len(cluster_list),cluster_list[-20:]) 26 for index in range(len(data)):#计算残差平方和 27 cluster_num = cluster_list[index] 28 29 sse += distEclud(data_train[index, :], cluster_ceter_list[cluster_num]) 30 print("簇数是",num , "时; SSE是", sse) 31 # print("3.dt_index:",data_train[index, :]) 32 # print("4.c_c_l:",cluster_ceter_list[cluster_num]) 33 SSE.append(sse) 34 return nums, SSE 35 36 nums, SSE = test_Kmeans_nclusters(filter_zscore_data)
簇数是 2 时; SSE是 296587.67961 簇数是 3 时; SSE是 245317.603158 簇数是 4 时; SSE是 209300.127424 簇数是 5 时; SSE是 183885.854183 簇数是 6 时; SSE是 167465.312745 簇数是 7 时; SSE是 151869.231702 簇数是 8 时; SSE是 142922.664126 簇数是 9 时; SSE是 135004.037996
1 #画图,通过观察SSE与k的取值尝试找出合适的k值 2 # 中文和负号的正常显示 3 plt.rcParams[‘font.sans-serif‘] = ‘STHeiti‘#mac字体替换 4 plt.rcParams[‘font.size‘] = 12.0 5 plt.rcParams[‘axes.unicode_minus‘] = False 6 # 使用ggplot的绘图风格 7 plt.style.use(‘ggplot‘) 8 ## 绘图观测SSE与簇个数的关系 9 fig=plt.figure(figsize=(10, 10)) 10 ax=fig.add_subplot(1,1,1) 11 ax.plot(nums,SSE,marker="+") 12 ax.set_xlabel("n_clusters", fontsize=18) 13 ax.set_ylabel("SSE", fontsize=18) 14 fig.suptitle("KMeans", fontsize=20) 15 plt.show()
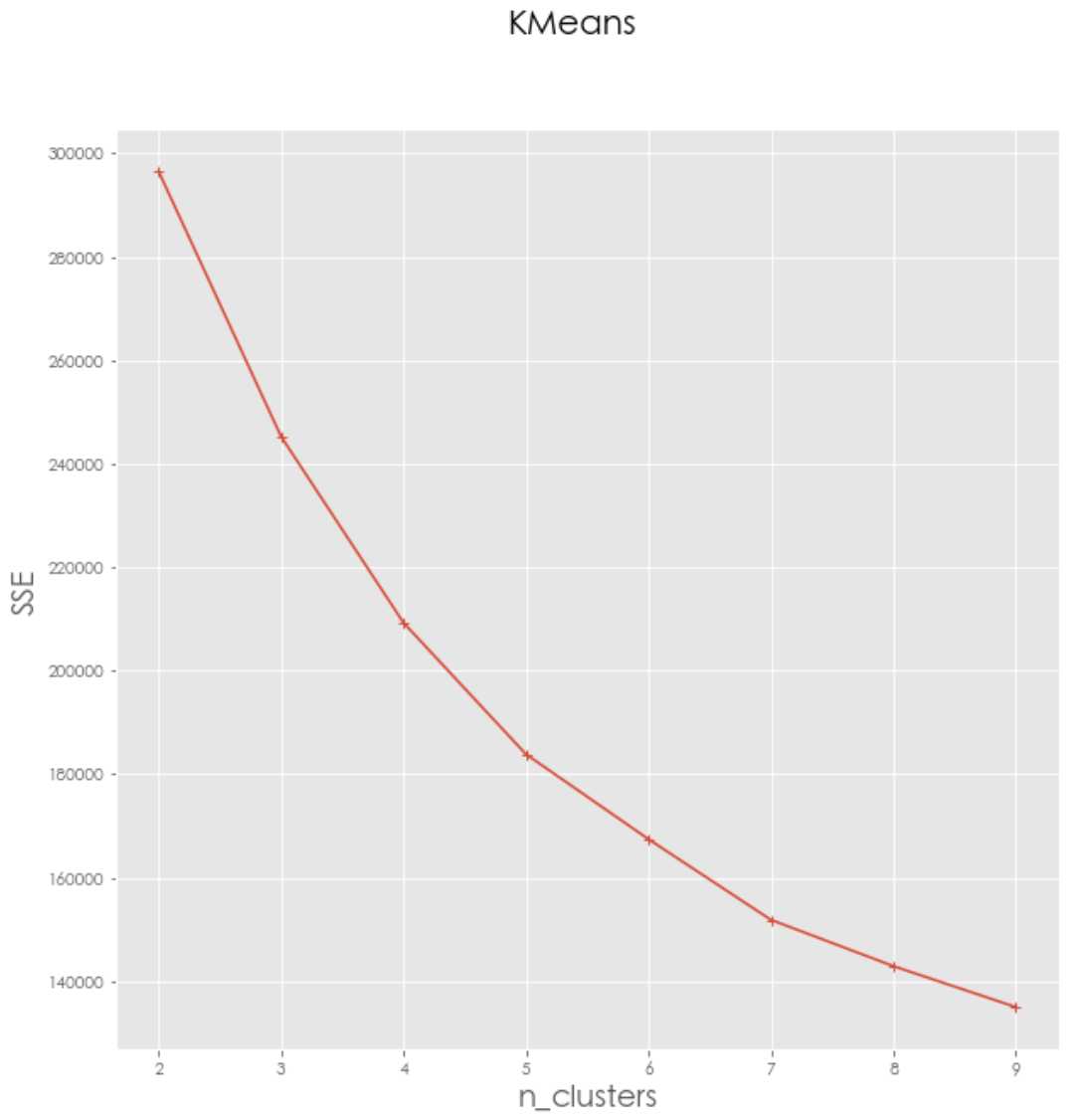
通过观察,并未发现明显的转折点,因此尝试选取k为4,5,6的聚类,看能否得到合适的客户聚类:
1 kmodel = KMeans(n_clusters=4, n_jobs=4) 2 kmodel.fit(filter_zscore_data) 3 # 简单打印结果 4 r1 = pd.Series(kmodel.labels_).value_counts() #统计各个类别的数目 5 r2 = pd.DataFrame(kmodel.cluster_centers_) #找出聚类中心 6 # print(r1,r2) 7 # 所有簇中心坐标值中最大值和最小值 8 max = r2.values.max() 9 min = r2.values.min() 10 # print(max,min) 11 r = pd.concat([r2, r1], axis = 1) #横向连接(0是纵向),得到聚类中心对应的类别下的数目 12 r.columns = list(filter_zscore_data.columns) + [u‘类别数目‘] #重命名表头 13 # print(r) 14 # 绘图 15 fig=plt.figure(figsize=(10, 8)) 16 ax = fig.add_subplot(111, polar=True) 17 center_num = r.values 18 feature = ["入会时间", "飞行次数", "平均每公里票价", "总里程", "时间间隔差值", "平均折扣率"] 19 N =len(feature) 20 for i, v in enumerate(center_num): 21 print(i,v,"#") 22 # 设置雷达图的角度,用于平分切开一个圆面 23 angles=np.linspace(0, 2*np.pi, N, endpoint=False) 24 # 为了使雷达图一圈封闭起来,需要下面的步骤 25 center = np.concatenate((v[:-1],[v[0]]))#-1:倒数第二个。把v拼接最后一个数 26 angles=np.concatenate((angles,[angles[0]])) 27 # 绘制折线图 28 ax.plot(angles, center, ‘o-‘, linewidth=2, label = "第%d簇人群,%d人"% (i+1,v[-1])) 29 # 填充颜色 30 ax.fill(angles, center, alpha=0.25) 31 # 添加每个特征的标签 32 ax.set_thetagrids(angles * 180/np.pi, feature, fontsize=15) 33 # 设置雷达图的范围 34 ax.set_ylim(min-0.1, max+0.1) 35 # 添加标题 36 plt.title(‘客户群特征分析图‘, fontsize=20) 37 # 添加网格线 38 ax.grid(True) 39 # 设置图例 40 plt.legend(loc=‘upper right‘, bbox_to_anchor=(1.3,1.0),ncol=1,fancybox=True,shadow=True) 41 42 # 显示图形 43 plt.show()
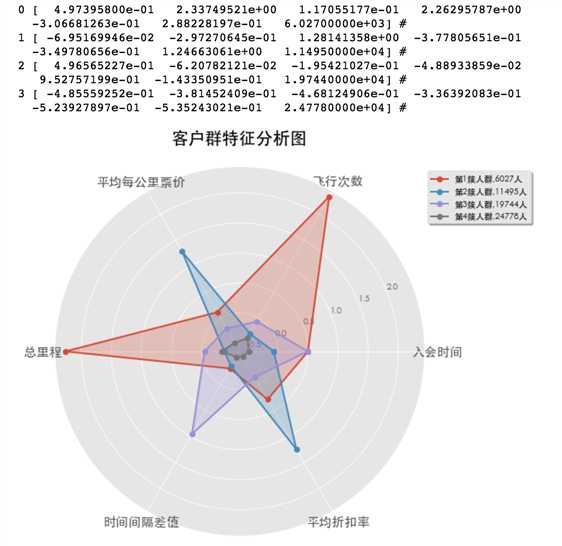
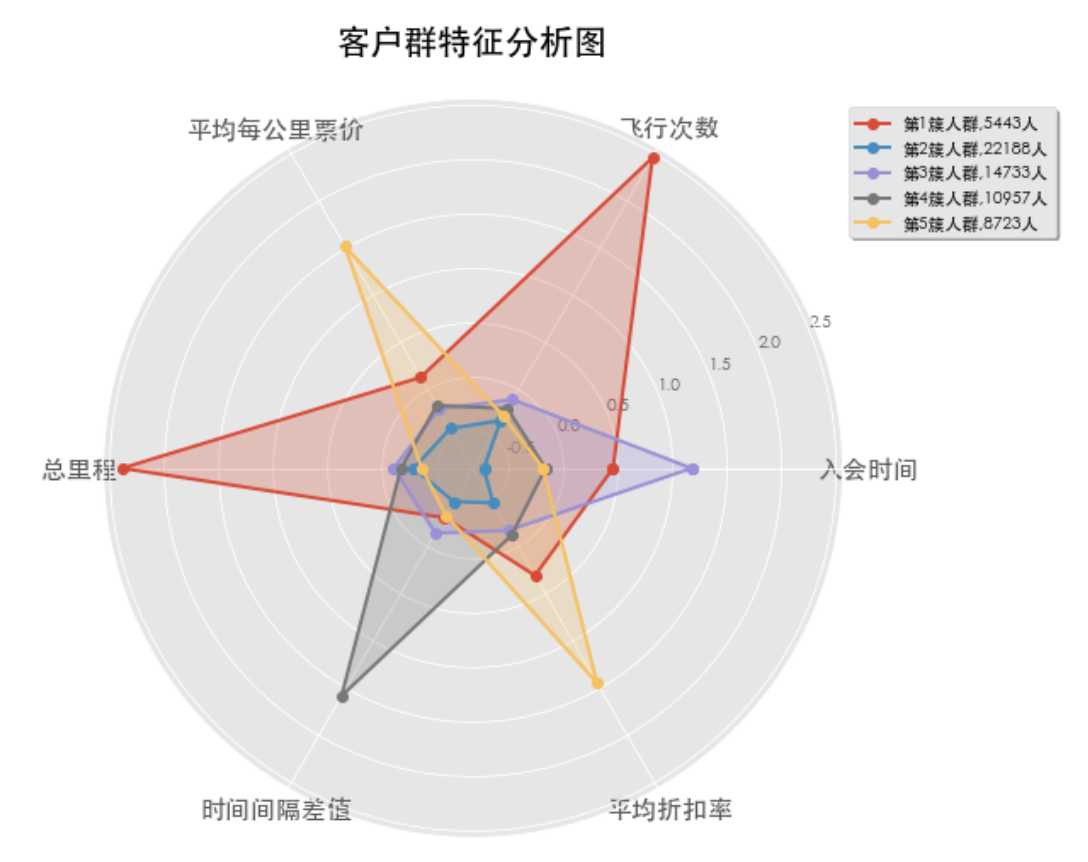
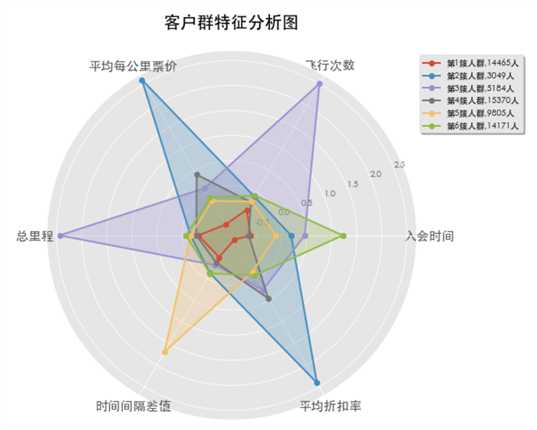
类似的,k为5,6时:
标签:sklearn RKE 通过 ota 挖掘 datetime 会员 ... ati
原文地址:https://www.cnblogs.com/daliner/p/9901475.html