标签:lse 文档 read png 操作 属性 describe main ali
空气质量分指数计算方法(框架)

1 def cal_liner(iaqi_lo,iaqi_hi,bp_lo,bp_hi,cp): 2 """范围缩放""" 3 iaqi =(iaqi_hi - iaqi_lo)*(cp -bp_lo) /(bp_hi - bp_lo) + iaqi_lo 4 return iaqi 5 6 def cal_pm_iaqi(pm_val): 7 if 0 <= pm_val <36: 8 pm_iaqi = cal_liner(0,50,0,35,pm_val) 9 elif 36 <= pm_val <76: 10 pm_iaqi = cal_liner(0,100,35,75,pm_val) 11 elif 76 <= pm_val < 116: 12 pm_iaqi = cal_liner(0, 150, 75, 115, pm_val) 13 else: 14 pass 15 16 def cal_co_iaqi(co_val): 17 if 0 <= co_val <3: 18 co_iaqi = cal_liner(0,50,0,3,co_val) 19 elif 3 <= co_val <5: 20 co_iaqi = cal_liner(0,100,2,4,co_val) 21 else: 22 pass 23 24 def cal_aqi(param_list): 25 pm_val = param_list[0] 26 co_val = param_list[1] 27 pm_iaqi = cal_pm_iaqi(pm_val) 28 co_iaqi = cal_pm_iaqi(co_val) 29 iaqi_list = [] 30 iaqi_list.append(pm_iaqi) 31 iaqi_list.append(co_iaqi) 32 33 aqi = max(iaqi_list) 34 return aqi 35 36 def main(): 37 print(‘请输入以下信息,使用空格分割‘) 38 input_str = input(‘(1)PM2.5 (2)CO:‘) 39 str_list = input_str.split(‘ ‘) 40 pm_val = float(str_list[0]) 41 co_val = float(str_list[1]) 42 param_list = [] 43 param_list.append(pm_val) 44 param_list.append(co_val) 45 #调用AQI计算函数 46 aqi_val = cal_aqi(param_list) 47 print(‘空气质量指数为:{}‘.format(aqi_val)) 48 49 if __name__ == ‘__main__‘: 50 main()
--snip-- city_list.sort(key= lambda city:city[‘aqi‘]) #func:函数为lambda,city为元素 top5_list = city_list[:5] #切片拿取前5个元素 f = open(‘top5_aqi.json‘,mode=‘w‘,encoding=‘utf-8‘) json.dump(‘top5_list‘,f,ensure_ascii=False) #第二元素为打开文件对象,最后为编码格式,中文false f.close
1 import json 2 3 def process_json_file(filepath): 4 f = open(filepath,mode=‘r‘,encoding=‘utf-8‘) 5 json.load(f) 6 city_list = json.load(f) 7 return city_list 8 9 def main(): 10 filepath = input(‘请输入json文件名称:‘) 11 city_list = process_json_file(filepath) 12 city_list.sort(key= lambda city:city[‘aqi‘]) #func:函数为lambda,city为元素 13 top5_list = city_list[:5] #切片拿取前5个元素 14 f = open(‘top5_aqi.json‘,mode=‘w‘,encoding=‘utf-8‘) 15 json.dump(‘top5_list‘,f,ensure_ascii=False) #第二元素为打开文件对象,最后为编码格式,中文false 16 f.close 17 18 if __name__ == ‘__main__‘: 19 main()
with open(‘file_name‘) as somefile: for line in somefile: print(line)
--snip-- lines.append(list(city_list[0].key())) #使用list拿到city的keys for city in city_list: lines.append(list(city.values())) f = open(‘aqi.csv‘,‘w‘,encoding=‘utf-8‘,newline=‘‘) #newline为空表示末尾不加任何字符,否则默认加空行 writer = csv.writer(f) for line in lines: writer.writerow(line) --snip--
1 import json 2 import csv 3 def process_json_file(filepath): 4 f = open(filepath,mode=‘r‘,encoding=‘utf-8‘) 5 city_list = json.load(f) 6 return city_list 7 8 def main(): 9 filepath = input(‘请输入json文件名称:‘) 10 city_list = process_json_file(filepath) 11 city_list.sort(key= lambda city:city[‘aqi‘]) #func:函数为lambda,city为元素 12 lines = [] 13 lines.append(list(city_list[0].key())) #使用list拿到city的keys 14 for city in city_list: 15 lines.append(list(city.values())) 16 f = open(‘aqi.csv‘,‘w‘,encoding=‘utf-8‘,newline=‘‘) #newline为空表示末尾不加任何字符,否则默认加空行 17 writer = csv.writer(f) 18 for line in lines: 19 writer.writerow(line) 20 21 if __name__ == ‘__main__‘: 22 main()
import csv import os def process_json_file(filepath): #解码json文件 # f = open(filepath,mode=‘r‘,encoding=‘utf-8‘) # city_list = json.load(f) # return city_list with open(filepath,mode=‘r‘,encoding=‘utf-8‘) as f: #with语句不需要关闭文件 city_list =json.load(f) print(city_list) def process_csv_file(filepath): with open(‘filepath‘,mode=‘r‘,encoding=‘utf-8‘,newline=‘‘) as f: reader = csv.reader(f) for row in reader: print(‘,‘.jion(row)) #通过逗号连接语句,.jion
1 import json 2 import csv 3 import os 4 def process_json_file(filepath): #解码json文件 5 # f = open(filepath,mode=‘r‘,encoding=‘utf-8‘) 6 # city_list = json.load(f) 7 # return city_list 8 with open(filepath,mode=‘r‘,encoding=‘utf-8‘) as f: #with语句不需要关闭文件 9 city_list =json.load(f) 10 print(city_list) 11 def process_csv_file(filepath): 12 with open(‘filepath‘,mode=‘r‘,encoding=‘utf-8‘,newline=‘‘) as f: 13 reader = csv.reader(f) 14 for row in reader: 15 print(‘,‘.jion(row)) #通过逗号连接语句,.jion 16 17 def main(): 18 filepath = input(‘请输入json文件名称:‘) 19 filename,file_ext = os.path.splitext(filepath) 20 if file_ext == ‘.json‘: 21 process_json_file(filepath) 22 elif file_ext == ‘.csv‘: 23 process_csv_file(filepath) 24 else: 25 print(‘不支持文件格式!‘) 26 27 if __name__ == ‘__main__‘: 28 main()
网络爬虫:
requests模块
import requests def get_html_text(url): """返回url的文本""" r = requests.get(url,timeout =30) #print(r.status_code) #显示状态,200为链接ok return r.text #获取文本 def main(): city_pinyin = input(‘请输入城市拼音:‘) url = ‘http://pm25.in/‘+city_pinyin url_text = get_html_text(url) #print(url_text) #属性名r.text d调用为url.text aqi_div=‘‘‘<div class="span12 data"> <div class="span1"> <div class="value"> ‘‘‘ #注意复制范围,一直取值到数字的前面,可能会有空格 index = url_text.find(aqi_div) begin_index = index +len(aqi_div) #从开始索引号‘<‘加上文本长度 end_index = begin_index + 2 #再获取2位为AQI值 aqi_value = url_text[begin_index: end_index] print(‘空气质量为:{}‘.format(aqi_value)) if __name__ == ‘__main__‘: main()
网页解析
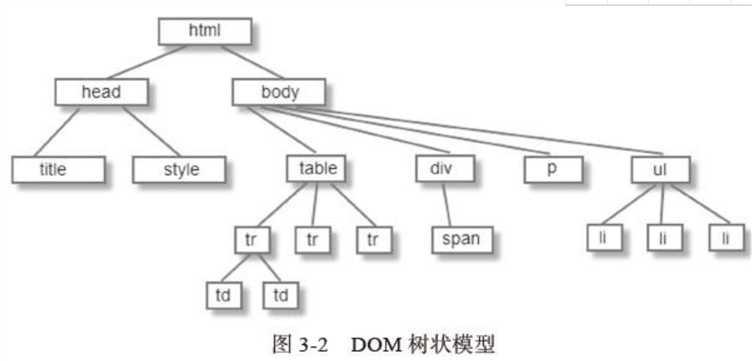
解析器输出的树是由DOM元素和属性节点组成的。DOM的全称为:Document Object Model。它是HTML文档的对象化描述,也是HTML元素与外界(如Javascript)的接口。
DOM与标签有着几乎一一对应的关系,如下:
<html>
<body>
<p>hello world</p>
<div><img src="aa.png"/></div>
</body>
</html>
bs = BeautifulSoup(
url,
html_parser, 指定解析器 #一般默认lxml
encoding 指定编码格式(确保和网页编码格式一致) #如果不一致会出现乱码
)
import requests from bs4 import BeautifulSoup def get_city_aqi(city_pinyin): url = ‘http://pm25.in/‘+city_pinyin r = requests.get(url,timeout=30) bs = BeautifulSoup(r.text,‘lxml‘) #bs = BeautifulSoup.find_all(‘div‘,‘span‘) div_list= bs.find_all(‘div‘,{‘class‘:‘span1‘}) #遗漏 city_AQI=[] for i in range(8): div_content = div_list[i] #对其list进行遍历 aqi = div_content.find(‘div‘,{‘class‘:‘value‘}).text.strip() #AQI = bs.find_all(‘div‘,‘value‘).text.strip() #应以键值对出现 caption = div_content.find(‘div‘,{‘class‘:‘caption‘}).text.strip() #city_AQI = city_AQI.append((caption, aqi)) city_AQI.append((caption, aqi)) return city_AQI def main(): city_pinyin = input(‘请输入城市拼音:‘) city_aqi =get_city_aqi(city_pinyin) print(city_aqi) if __name__ == ‘__main__‘: main()
遍历城市
1 import requests 2 from bs4 import BeautifulSoup 3 4 def get_city_aqi(city_pinyin): 5 url = ‘http://pm25.in/‘+city_pinyin 6 r = requests.get(url,timeout=30) 7 bs = BeautifulSoup(r.text,‘lxml‘) 8 div_list= bs.find_all(‘div‘,{‘class‘:‘span1‘}) 9 city_AQI=[] 10 for i in range(8): 11 div_content = div_list[i] 12 aqi = div_content.find(‘div‘,{‘class‘:‘value‘}).text.strip() 13 caption = div_content.find(‘div‘,{‘class‘:‘caption‘}).text.strip() 14 city_AQI.append((caption, aqi)) 15 return city_AQI 16 17 def get_all_cities(): 18 url = ‘http://pm25.in/‘ 19 city_list = [] 20 r = requests.get(url, timeout=30) 21 bs = BeautifulSoup(r.text, ‘lxml‘) 22 city_all_name = bs.find_all(‘div‘, {‘class‘: ‘bottom‘})[1] 23 city_link_list = city_all_name.find_all(‘a‘) 24 #for i in city_all_name: 此段只要一个bottom元素,将无法输出 25 for city_link in city_link_list: 26 city_name = city_link.text 27 city_pinyin = city_link[‘href‘][1:] 28 #r = city_all_name[1] 29 #city_name = r.find(‘div‘,{‘href‘:‘city_link‘}).text.strip() 30 #city_link = r.find(‘div‘,{‘href‘:‘city_link‘})[1:] 31 city_list.append((city_name,city_pinyin)) 32 return city_list 33 34 def main(): 35 city_list = get_all_cities() 36 for city in city_list: 37 city_name =city[0] 38 city_pinyin = city[1] 39 city_aqi =get_city_aqi(city_pinyin) 40 print(city,city_aqi) 41 42 if __name__ == ‘__main__‘: 43 main()
--snip-- def get_all_cities(): url = ‘http://pm25.in/‘ city_list = [] r = requests.get(url, timeout=30) bs = BeautifulSoup(r.text, ‘lxml‘) city_all_name = bs.find_all(‘div‘, {‘class‘: ‘bottom‘})[1] city_link_list = city_all_name.find_all(‘a‘) #寻找所有bottom下的a标签 for city_link in city_link_list: city_name = city_link.text #取city_link文本 city_pinyin = city_link[‘href‘][1:] #取其‘/’后的数字 city_list.append((city_name,city_pinyin)) return city_list def main(): city_list = get_all_cities() for city in city_list: #对获取列表进行遍历输出 city_name =city[0] city_pinyin = city[1] city_aqi =get_city_aqi(city_pinyin) print(city,city_aqi) #注意为city,city_list将重复报错 if __name__ == ‘__main__‘: main()
字符串加列表 ‘abc’+[1,2,3]转换为[‘abc‘]+[1,2,3]
存入转换为CSV格式
1 import requests 2 from bs4 import BeautifulSoup 3 import csv 4 5 def get_city_aqi(city_pinyin): 6 url = ‘http://pm25.in/‘+city_pinyin 7 r = requests.get(url,timeout=30) 8 bs = BeautifulSoup(r.text,‘lxml‘) 9 div_list= bs.find_all(‘div‘,{‘class‘:‘span1‘}) 10 city_AQI=[] 11 for i in range(8): 12 div_content = div_list[i] 13 aqi = div_content.find(‘div‘,{‘class‘:‘value‘}).text.strip() 14 caption = div_content.find(‘div‘,{‘class‘:‘caption‘}).text.strip() 15 city_AQI.append(aqi) 16 return city_AQI 17 18 def get_all_cities(): 19 url = ‘http://pm25.in/‘ 20 city_list = [] 21 r = requests.get(url, timeout=30) 22 bs = BeautifulSoup(r.text, ‘lxml‘) 23 city_all_name = bs.find_all(‘div‘, {‘class‘: ‘bottom‘})[1] 24 city_link_list = city_all_name.find_all(‘a‘) 25 for city_link in city_link_list: 26 city_name = city_link.text 27 city_pinyin = city_link[‘href‘][1:] 28 city_list.append((city_name,city_pinyin)) 29 return city_list 30 31 def main(): 32 city_list = get_all_cities() 33 header = [‘City‘,‘AQI‘,‘PM2.5/1H‘,‘PM10/H‘,‘CO/H‘,‘NO2/H‘,‘O3/1H‘,‘O3/8H‘,‘SO2/H‘,] #指定列名 34 with open(‘china_city_AQI.csv‘,‘w‘,encoding=‘utf-8‘,newline=‘‘) as f: 35 writer = csv.writer(f) 36 writer.writerow(header) 37 for i,city in enumerate(city_list): #enumerate科学计数法 38 if (i+1)%10 ==0: #实时查看处理进度 39 print(‘已处理{}条记录,共{}记录‘.format(i+1,len(city_list))) 40 city_name = city[0] 41 city_pinyin = city[1] 42 city_aqi = get_city_aqi(city_pinyin) 43 row= [city_name]+city_aqi #字符串转换为列表格式[] 44 writer.writerow(row) 45 46 if __name__ == ‘__main__‘: 47 main()
--snip-- def main(): city_list = get_all_cities() header = [‘city‘,‘AQI‘,‘PM2.5/1H‘,‘PM10/H‘,‘CO/H‘,‘NO2/H‘,‘O3/1H‘,‘O3/8H‘,‘SO2/H‘] #指定列名 with open(‘china_city_AQI.csv‘,‘w‘,encoding=‘utf-8‘,newline=‘‘) as f: writer = csv.writer(f) writer.writerow(header) for i,city in enumerate(city_list): #enumerate科学计数法 if (i+1)%10 ==0: print(‘已处理{}条记录,共{}记录‘.format(i+1,len(city_list))) city_name = city[0] city_pinyin = city[1] city_aqi = get_city_aqi(city_pinyin) row= [city_name]+city_aqi writer.writerow(row) if __name__ == ‘__main__‘: main()
Pandas库:
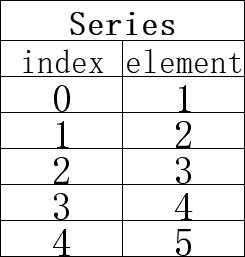 例:
例:

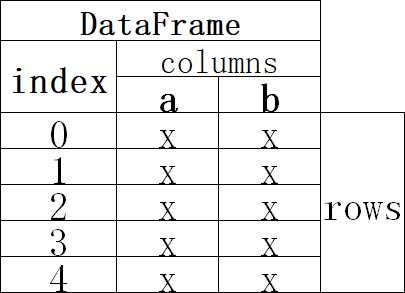
import pandas as pd def main(): aqi_data = pd.read_csv(‘china_city_AQI.csv‘) #print(aqi_data.head(5)) #print(aqi_data[‘AQI‘]) print(aqi_data[[‘city‘,‘AQI‘]]) #中间的中括号为列表 if __name__ == ‘__main__‘: main()
import pandas as pd def main(): aqi_data = pd.read_csv(‘china_city_AQI.csv‘) print(‘基本信息:‘) print(aqi_data.info()) print(‘数据预览:‘) print(aqi_data.head()) #基本统计 print(‘AQI最大值:‘, aqi_data[‘AQI‘].max()) print(‘AQI最大值:‘, aqi_data[‘AQI‘].min()) print(‘AQI最大值:‘, aqi_data[‘AQI‘].mean()) #top10 top10_cities= aqi_data.sort_values(by=[‘AQI‘]).head(10) print(‘空气质量最好的10个城市:‘,top10_cities) #bottom10 #bottom10_cities = aqi_data.sort_values(by=[‘AQI‘]).tail(10) bottom10_cities = aqi_data.sort_values(by=[‘AQI‘],ascending= False).head(10) #同理上述写法,降序排列 print(‘空气质量最差的10个城市:‘, bottom10_cities) #保存csv文件 top10_cities.to_csv(‘top10_aqi.csv‘,index = False) #index为不需要序列号 bottom10_cities.to_csv(‘top10_aqi.csv‘,index = False) if __name__ == ‘__main__‘: main()
Pandas数据清洗
1 import pandas as pd 2 3 def main(): 4 aqi_data = pd.read_csv(‘china_city_AQI.csv‘) 5 print(‘基本信息:‘) 6 print(aqi_data.info()) 7 print(‘数据预览:‘) 8 print(aqi_data.head()) 9 10 #数据清洗,只保留AQI>0的数据 11 # filter_condition = aqi_data[‘AQI‘] > 0 12 # clean_data = aqi_data[filter_condition]或者 13 clean_aqi_data = aqi_data[aqi_data[‘AQI‘] > 0] 14 15 #基本统计 16 print(‘AQI最大值:‘, aqi_data[‘AQI‘].max()) 17 print(‘AQI最大值:‘, aqi_data[‘AQI‘].min()) 18 print(‘AQI最大值:‘, aqi_data[‘AQI‘].mean()) 19 20 #top10 21 top10_cities= clean_aqi_data.sort_values(by=[‘AQI‘]).head(10) 22 print(‘空气质量最好的10个城市:‘,top10_cities) 23 #bottom10_cities = clean_aqi_data.sort_values(by=[‘AQI‘]).tail(10)或者 24 bottom10_cities = clean_aqi_data.sort_values(by=[‘AQI‘],ascending= False).head(10) #同理上述写法,降序排列 25 print(‘空气质量最差的10个城市:‘, bottom10_cities) 26 27 if __name__ == ‘__main__‘: 28 main()
--snip--
#数据清洗,只保留AQI>0的数据
# filter_condition = aqi_data[‘AQI‘] > 0
# clean_data = aqi_data[filter_condition]或者
clean_aqi_data = aqi_data[aqi_data[‘AQI‘] > 0]
--snip--
Pandas数据可视化
import pandas as pd def main(): aqi_data = pd.read_csv(‘china_city_AQI.csv‘) print(‘基本信息:‘) print(aqi_data.info()) print(‘数据预览:‘) print(aqi_data.head()) #基本统计 print(‘AQI最大值:‘, aqi_data[‘AQI‘].max()) #top10 top10_cities= aqi_data.sort_values(by=[‘AQI‘]).head(10) print(‘空气质量最好的10个城市:‘,top10_cities) #bottom10 #bottom10_cities = aqi_data.sort_values(by=[‘AQI‘]).tail(10) bottom10_cities = aqi_data.sort_values(by=[‘AQI‘],ascending= False).head(10) #同理上述写法,降序排列 print(‘空气质量最差的10个城市:‘, bottom10_cities) #保存csv文件 top10_cities.to_csv(‘top10_aqi.csv‘,index = False) #index为不需要序列号 bottom10_cities.to_csv(‘bottom10_aqi.csv‘,index = False) if __name__ == ‘__main__‘: main()
标签:lse 文档 read png 操作 属性 describe main ali
原文地址:https://www.cnblogs.com/Mack-Yang/p/9826019.html
