标签:做了 词频统计 共享 hub 代码仓库 初步 format strip 人做
第二次结对项目(词频统计要求网址):
https://www.cnblogs.com/xinz/archive/2011/11/27/2265000.html
项目网址:
详细要求位于这里。
简要概括:根据输入的命令行参数,对文本中的字符进行对应的统计,例如使用-c命令统计字符出现次数,利用-f统计单词出现次数等等。项目一共分为5个步骤,4个必做项和一个附加项。分别为统计字母比例,单词数,短语数,动词形态还原、停用词剔除、动词介词词组统计。在本次项目中,我们依次完成了这样的5个步骤,并且在代码仓库中打好了tag,可以git checkout到相应的step,包含py文件、unittest文件夹中的测试文件和test文件夹中的测试数据。注意,每个step包含前面step的所有命令行参数功能,step0-4没有进行优化,step5(默认tag标签)中支持所有功能且经过了速度优化。
在这次结对编程中,我们采取的是分工 -> 领航员与驾驶员 -> 分工 这样的合作模式。
具体流程为:拿到任务后进行开会分析具体要求、完成方法和任务量,找到代码规范参考网站,约定第一周周五晚完成基本功能,谁有空谁写,不在乎代码的效率和质量,周六在已经完成自己部分且对项目熟悉了的基础下,碰面结对编程,互相讲解自己完成的代码并在讲解中发现问题和优化方式,在困难的部分进行共同思考、完成算法设计,同时编程一人coding一人监督检查。之后进一步讨论疑惑的点,一个人做test文件检查正确性,一个人继续优化和重构代码,分工完成与助教参考程序的比对和对模糊要求地方的理解和高效的实现。
采取这样模式的主要原因是一个是这个项目延续了两周,在日常难以协调出长时间进行编程的时间,所以选择在周末进行领航员与驾驶员式的结对编程,平常以分工和简短的讨论为主。在分工代码出现问题时会采用远程共享桌面的方式进行合作。
由于是第二次项目,之前对彼此代码风格都有一定了解,并且两个人都对变量命名规范等没有很强的强迫症,所以我们选取了一篇博客中的编码规范(该博客地址在我们的github项目中),并对一些细节在第一次讨论时做了一定的规范,很快达成一致。在讨论中,我们还确定了代码的几个部分和合作的方式。讨论时的会议记录如下:
策略
由于时间的限制,所以做的结果是一个我们可以接受的尽量好的结果。我们采取的结对策略是分工,领航员与驾驶员,分工的合作模式,所以在接到项目的前期,我们先是使用开会的方式很快的确定了采用python作为编程语言,和一些对应的编码规范。
资料收集
比起盲目尝试,这样一个经典的项目会有很多的参考。所以在讨论之后我们进入一段时间的资料收集,参考网络上如何进行词频统计的代码示例来总结一些经验。在这个阶段,我们主要使用Skype直接分享调研得到的结果。通过这个调研结果,我们发现使用python的collection包中的Counter可以很快速的帮助我们对词频进行统计。使用正则匹配的re函数包可以用正则表达式进行分词。所以我们先定下了初步的使用到的函数
初步分工
我们在这个阶段主要是依据之前收集的资料进行初步的编程,先不考虑任何的实现效率,使用库函数和基本的逻辑判断做一个初步的,可以实现所有功能的版本,保证可以复现出一个相对正确的结果。并编写一定的测试样例来保证我们结果的正确性,对每一步迭代进行单元测试和回归测试
领航员与驾驶员
在周末,完成了初步功能版本的我们开始了结对优化。我们使用的是Visual Studio中的python效能分析功能进行效能分析,使用unittest进行单元测试的编写。
首先,我们进行了一些实现误区上的纠正,例如几个命令行参数不可以混用以及例如stopword应该如何处理这个样子的误区我们进行了纠正,并修改了对应的单元测试,之后我们为代码添加了计时模块,同时利用程序本身的计时和python效能分析来进行判断。
在最初版本的优化中,因为我们误将动词加介词形式的短语作为优化的重点,所以我们将大部分精力放置于如何优化动词加介词的判断。由于re模块的正则匹配是一个不回溯的匹配模式,所以我们采取先分割单词再人为对单词进行组合成短语的形式进行判断。
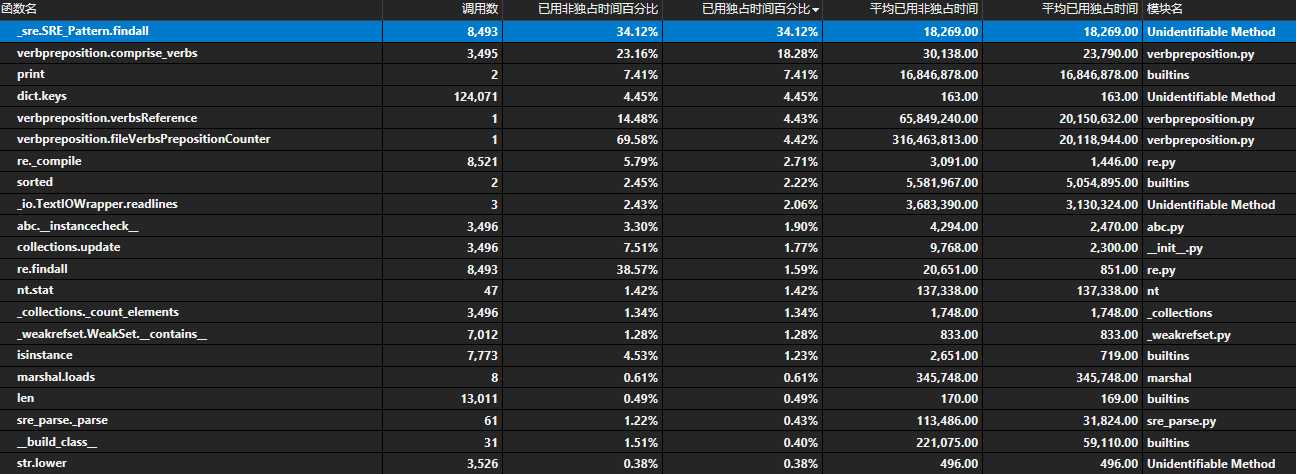
在上述截图中,我们发现compile函数调用了8521次,findall调用了8493次,查找字典中对应的key调用了124071次,我们查看了具体的调用处,
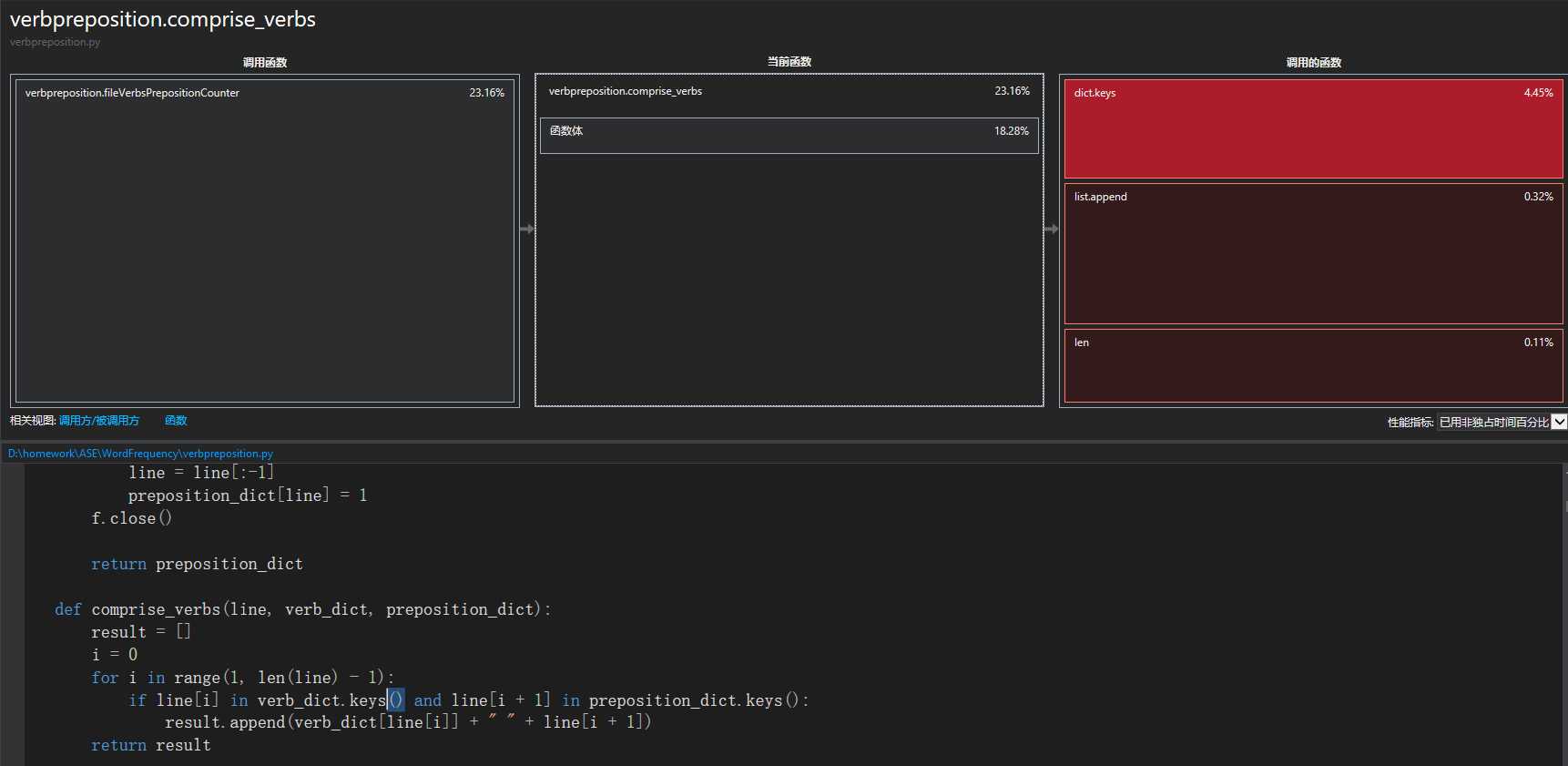
通过资料查阅,发现字典可以不使用keys来调用所有的键值,所以我们对代码进行了修改,将keys删除,来减少字典查询时间,
经过优化,速度从0.13提升到0.10(500K大小的文本文件)。之后,采用类似的策略,我们尝试减少了判断次数,比如在匹配成功的情况下可以直接跳过一个单词进行判断,也就是可以在发现了一个动词加空格加介词的形式时直接跳过一个单词。之后,同样的启发,我们对判断短语函数中的长短语判断逻辑进行了优化。也就是,尽量每个词只进行一次判断,采取一个跳跃的判断形式,类似于KMP的算法流程,如下所示:
while i < length:
while j < pharse:
if line[i + j][0] > ‘z‘ or line[i + j][0] < ‘a‘:
i = i + j
j = 0
temp=‘‘
break
temp = temp + line[i + j] + ‘ ‘
lens[j] = len(line[i+j])
j = j + 1
if j==pharse:
j = pharse - 1
result.append(temp[:-1])
temp = temp[lens[0]+1:]
for k in range(pharse-1):
lens[k] = lens[k+1]
i = i + 1在之后的优化逻辑中,由于我们拼接字符串会多引入一个空格,而我们用来有一定逻辑判断的rstrip函数进行了空格去除操作,这部分逻辑判断并不是必须的,因此我们采取[:-1]的字符串截取操作。
在这一版本的效能分析中,我们发现求字符串长度的len函数调用次数非常多,所以我们将此处的字符串拼接操作改成了使用列表进行存储操作,减少字符串拼接次数,同样获得了一定的速度提升。
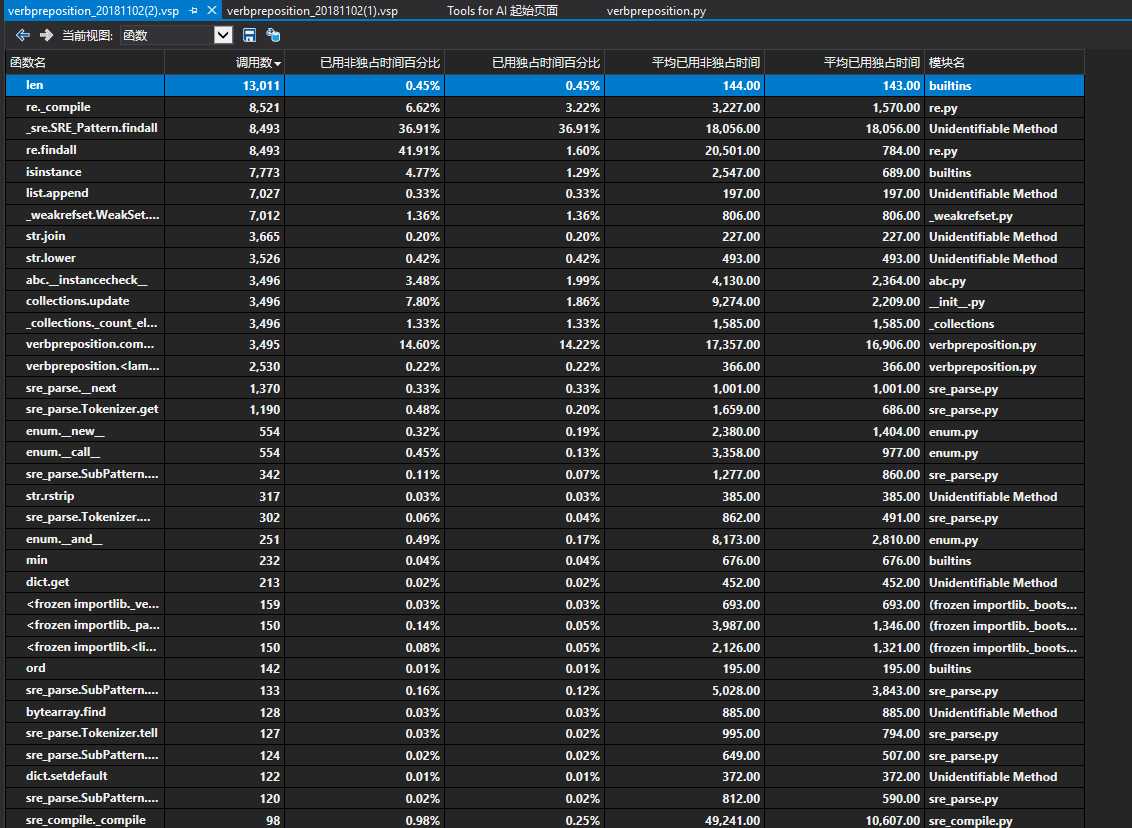
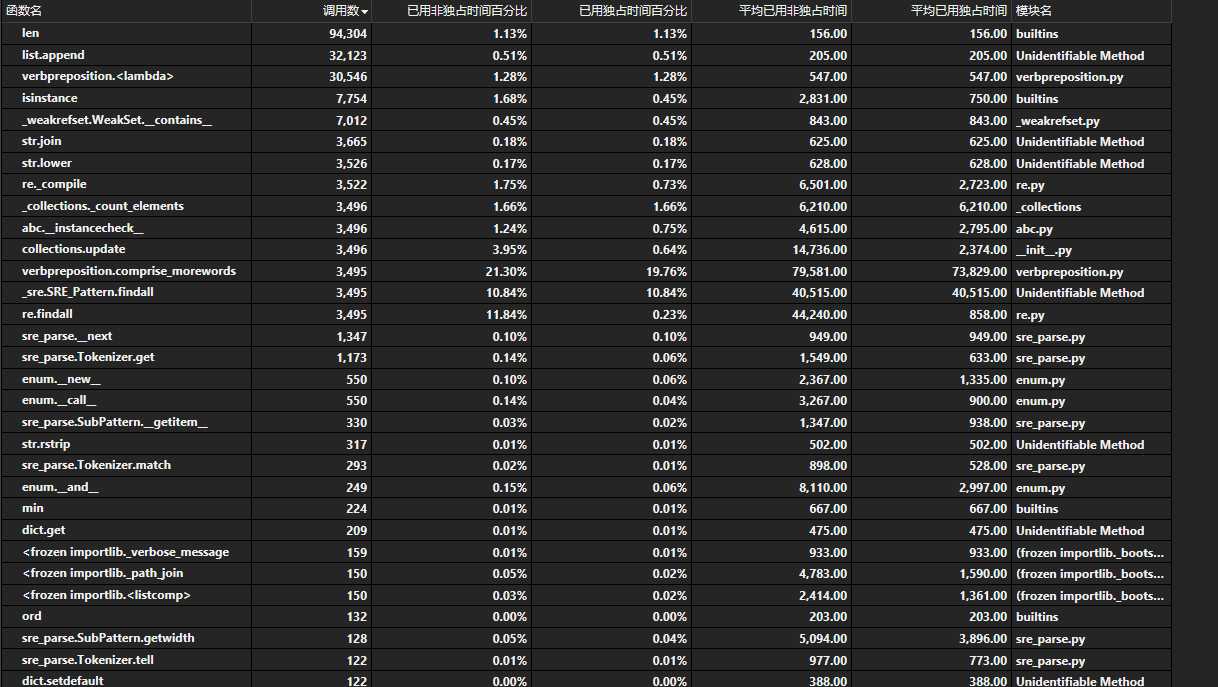
在效能分析中,我们用于分割单词的re.findall函数调用的次数非常多,为了解决这个问题,我们尝试了NTLK的函数分割包,和pynlpir这样的函数包,和自己写的if逻辑判断,发现速度都没有提升(摊手)
这个问题后来通过先分把长段分割成句子,再通过将句子分割成单词,减少正则表达次数得到了一定的缓解,但是这个样子的结果表现并不稳定。
所以我们的结对优化过程就是这样一个修改,测试的迭代过程。再次分工
在最后的阶段,我们采取了自行测试分析,找寻可能的方法作尝试的方法来进行进一步的优化,比如发现字符串采用format的形式进行连接操作会比使用"+"进行连接操作要更有效率。
存在一些问题
一开始的优化目标出现了问题,精力分配出错。然后在测试过程中因为一次最多测试两种想法,很多开出来的脑洞并没有尝试就被抛弃了(因为想不起来是啥)。对于一些编码的细节把握还是有欠缺,比如字符串操作的几种方式的效率这样的细节。
队友:
优势:缺点:
代码不注意细节,小问题比较多。
标签:做了 词频统计 共享 hub 代码仓库 初步 format strip 人做
原文地址:https://www.cnblogs.com/qiweizhen/p/9901695.html