标签:参数 固定 不同的 href 关系 分类器 应用 range 允许
最优间隔分类器
对于一个给定的数据集,目前有一个很现实的需求就是要找到一个合适的决策边界,使得样本中的最小间隔(几何间隔)最大,而且这样的分类器能够使得分割的训练样本集之间的间隔(gap)最大。现在,我们假设训练集合线性可分,即可以找一条超平面把正样本和负样本分割开来。那么我们如何找到一个超平面来最大化几何间隔呢?我们得到了如下的优化问题:
maxγ,w,b γ
s.t. y(i)(wTx(i)+ b) ≥ γ, i = 1, . . . , m
||w|| = 1
也就是说,我们希望最大化γ,其中对于每一个样本而言,每一个函数间隔值都不小于γ。其中,设定||w|| 固定为 1,能够保证函数间隔等于几何间隔,也能保证几何间隔最小可达到γ。因此,解决这个优化问题后就可以得到该训练集合的最大可能几何间隔。
但是很难解决上面的优化问题,因为||w|| = 1是非凸优化,这就无法使用标准优化软件去解决这个优化问题。因此,我们把这个优化问题转化成相对简单的问题,如下:
s.t. y(i)(wTx(i)+ b) ≥ ?γ, i = 1, . . . , m
s.t. y(i)(wTx(i)+ b) ≥ 1, i = 1, . . . , m
我们先把SVM和最大间隔分类放在一边,这里主要讨论一下如何求解约束优化问题。考虑如下形式的问题:
s.t. hi(w) = 0, i = 1, . . . , l.
在这里我们将介绍拉格朗日乘子法(Lagrange multipliers)。在该方法中,我们定义拉格朗日算符(Lagrangian)如下:
L(w, β) = f (w) +
这里的βi称之为拉格朗日乘子(Lagrange multipliers)。求解该式的最优解,只需要使得L对 βi 和wi 的偏微分为0即可,如下:
;
之后只要求解出w和 β 即可。
在这部分,我们将把这个问题扩展到约束优化问题中,即找到约束优化中不等式来代替拉格朗日乘子法中的等式约束。这里不再讲解拉格朗日对偶理论和详细的证明,但是仍将给出主要的方法和结果,以便我们能够把该方法应用到最优间隔分类器的优化问题上。
考虑如下问题,我们称之为原始优化问题(primal optimization problem):
minw f (w)
s.t. gi(w) ≤ 0, i = 1, . . . , k
hi(w) = 0, i = 1, . . . , l.
为了解决该问题,我们开始定义广义拉格朗日(generalized Lagrangian):
L(w, α, β) = f (w) + +
这里,αi 和 βi都是拉格朗日乘子。考虑下式:
θP(w) = maxα,β : αi≥0 L(w, α, β)
这里下标P表示原始的(primal)。现在我们赋一些值给w。如果w违反了原始限制(如对于某些i,gi(w) > 0 或者 hi(w) != 0),那么我们将得到:
相反的,如果对于某个w,约束条件能够很好的满足,那么θP(w) = f(w),因此有:
因此,对于所有满足原始约束条件的w,θP取得相同的值作为我们问题的目标。如果不满足约束条件,则θP结果为正无穷大。因此,考虑最小优化问题:
minw θP(w) = minw maxα,β : αi≥0 L(w, α, β)
我们可以看到这和原始优化问题是相同(具有相同的解)。为了后面的使用,我们定义最优目标值为p?= minw θP(w) ,称之为原始问题解。
现在我们考虑一个稍微不同的问题,定义θD(α, β) = minw L(w, α, β),这里的下标D表示对偶(dual)。注意这里与θP不同,θP是针对α, β的最优化函数,而θD是针对w的最优化函数。现在,我们可以得到对偶优化问题:
maxα,β:αi ≥0 θD(α, β) = maxα,β:αi ≥0 minw L(w, α, β)
当然,在某些情况下,存在d?= p? 。因此,我们可以通过解决对偶问题替换原始问题。我们来看看能够替代的情况有哪些。
假设f和g是凸函数,而且hi是仿射(Affine,类似于线性,但是允许截距项的存在)函数。此外,我们认为gi是可行的,即对于所有的i,存在w使得gi(w)<0 。针对该假设,一定存在w?, α?, β?使得w?为原始问题的解, α?, β?是对偶问题的解,而且p?= d?= L(w?, α?, β?)。此外,w?, α?, β?还满足KKT条件(Karush-Kuhn-Tucker),如下所示。
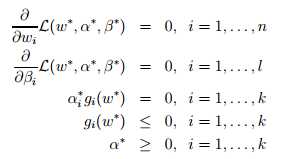
此外,如果存在w?, α?, β?满足KKT条件,那么这也是原始问题和对偶问题的解。对于条件中α?igi(w?) = 0, i=1, ... ,k,称之为KKT对偶互补条件(dual complementarity condition)。特别的,这里暗含着如果α?i>0,那么gi(w?) =0。之后,这在SVM中的支持向量(support vectors)起到关键作用。此外,KKT对偶互补条件也将在我们SMO的收敛测试中用到。
之前我们讨论了如下优化问题(即原始优化问题)来求得最优间隔分类器。
s.t. y(i)(wTx(i)+ b) ≥ 1, i = 1, . . . , m
gi(w) = ?y(i)(wTx(i)+ b) + 1 ≤ 0
针对每一个样本,我们都存在该约束条件。根据KKT对偶互补条件αigi(w) = 0,我们知道仅对于训练集合中函数间隔恰好等于1的样本,才存在线性约束前面的系数αi > 0,也就是说这些约束式gi(w) = 0。对于其他不在线上的点(gi(w)<0),极值不会在他们所在的范围内取得,αi = 0。
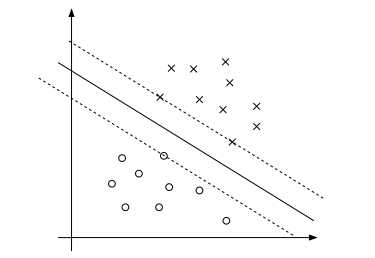
看下面的图:实线是最大间隔超平面,假设×号的是正例,圆圈的是负例。在虚线上的点就是函数间隔是1的点,那么他们前面的系数αi > 0,其他点都是αi = 0。这三个点称作支持向量。一般而言,支持向量数量相对于整个训练集合而言是非常少的,之后我们会发现这是非常有用的。
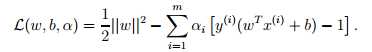
注意到这里只有αi和βi
,因为原问题中没有等式约束,只有不等式约束。接下来我们需要寻找该问题的对偶式。首先,对于给定的αi,L(w, b, α)仅受w和b影响,我们需要最小化L(w, b, α),只需要让L对w和b的偏微分为0。对w求偏微分如下: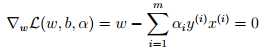
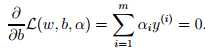

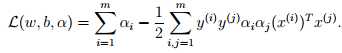
这里我们把向量内积 (x(i))Tx(j) 表示为<(x(i)), x(j)>。此时的拉格朗日函数只包涵了变量αi,求解出αi之后即可以得到w和b。根据对偶问题的求解,我们得到了如下的最大化问题:
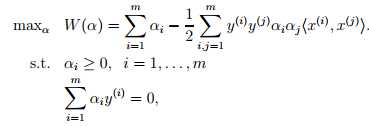
这里我们需要考虑p? = d? 的条件,即KKT条件。因为目标函数和线性约束都是凸函数,而这里不存在等式约束h,存在w使得对于所有的i,使得gi(w) <= 0,因此存在w* 和 a*使得w*是原问题的解, a*是对偶问题的解。这里求解的ai就a*如果求解出了ai,根据w = 即可以求解出w(也就是w*,原问题的解)。同样根据下式得到b:
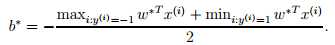
求解得到b,即距离超平面最近的正的函数间隔要等于距离超平面最近的负的函数距离。关于上面的对偶问题如何求解,在下一讲中我们将采用SMO算法来阐明。
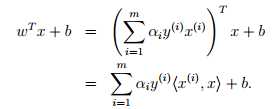
通过优化问题的对偶形式,我们更深入的看到了需要优化问题的结构,并且找到了能够适合于特征向量内积的算法。在下一讲,我们会讨论核方法在高维数据中使用以及求解支持向量机的算法。
标签:参数 固定 不同的 href 关系 分类器 应用 range 允许
原文地址:https://www.cnblogs.com/kexinxin/p/9904407.html