标签:输出 部分 初始 好的 效果 它的 att 开始 wrapper
特征选择
本节将接着上一讲,并结束掉经验风险最小化一章,之后讨论特征选择等相关问题。
我们在假设集合内假设有限的情况下已经证明了一些有用的理论。但是,很多假设集合,内部的参数都是实数(比如线性回归)即假设集合中包含了无数多个假设。那么,我们能否得到类似的结论呢?
首先,我们讨论一下不是很正确的一些论点,而这些论点是更好的且更加广泛,而且有利于我们的分析。假设的参数是实数d,因为计算机存储实数的时候使用双精度即64b来存储一个浮点型数据。这就意味着我们的学习算法会假如我们使用了双精度类型存储数据,即参数是64b大小,那么对于我们的假设集合实际上包含k = 264d个不同的假设。根据上一节的结论,我们可以保证ε(?h) ≤ ε(h*) + 2γ,在概率至少是1 – δ 的情况下,使得m ≥ O(1/γ2 * log(264d/δ)) = O(d/γ2 * log(1/δ) = Oγ,δ(d) (这里的下标γ, δ表示大O是依赖于该两参数)。因此,需要的训练样本数最多只是模型的参数的线性个数。
问题是,我们依据64b的浮点型数据存储并不能完全满足该论点,但是结论却是差不多对的。如果我们继续尝试最小化训练误差,也就是为了更好的学习到假设集合中的参数d,通常的我们需要训练样本达到d的线性个数。从这个意义上来说,这些结论对于一个使用了经验风险最小化的算法而言,根本不需要证明。因此对于多数判别学习算法,他们的样本复杂度是d的线性复杂度,然而这些结论并不总是那么容易实现。为了保证许多非经验风险最小化的学习算法的理论可用性,这方面仍在研究中。
之前的讨论是依赖于假设集合的参数,在某些情况下仍然是无法满足的。直观的看,这并不像是什么问题。假设我们的线性分类器假设集合为,hθ(x) =1{θ0 + θ1x1 + · · · θnxn ≥ 0},含有n+1个参数θ0…. Θn,但是他同时也可以写成hu,v(x) = 1{(u20? v20) + (u21? v21)x1 + · · · (u2n? v2n)xn ≥ 0},包含2n + 2个参数ui, vi 。然而这些都是定义了同一个假设集合 :n维度下的线性分类器。
为了推导出更令人满意的结论,我们定义一些东西如下:
对于给定的数据集S = {x(i), . . . , x(d)}(和训练数据集无关),其中x(i)∈ X,我们说粉碎(shatter)了S ,如果能够实现S上的任意类别(label)。举例子而言,如果对于任意类别集合{y(1), . . . , y(d)},中总是存在一些h使得对于所有i = 1, . . . d存在h(x(i)) = y(i)。
对于一个假设集合,我们定义它的VC维(Vapnik-Chervonenkis dimension),记作VC(),指被假设集合粉碎(shatter)掉的最大的数据集的大小。(如果能够粉碎任意大小的数据集,那么VC() = ∞)。
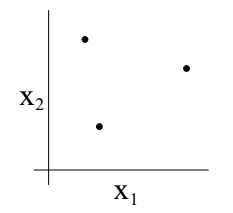
举例子而言,如下图的三个点:对于二维的线性分类器假设集合(h(x) = 1{θ0 + θ1x1 +θ2x2 ≥ 0})能否粉碎(shatter)掉途中的数据集呢?答案是可以。
换句话说,在VC维的假设下,为了证明VC()最小是d,那么我们仅需要展示假设集合至少能够粉碎(shatter)一个大小为d的数据集。下面是基于Vapnik的理论(这是机器学习理论中最重要的理论。)
定律:对于给定的假设集合 ,令VC() = d,那么至少有1 – δ的概率下,对于所有的h∈ ,存在 |ε(h) ? ?ε(h)| ≤ 。因此,在至少1 – δ的概率下,也存在 ?ε(h) ≤ ε(h?) 。
推论:对于|ε(h) ? ?ε(h)| ≤ γ ,如果对所有h∈ ,在至少1 – δ的概率下均成立(因此 ε(?h) ≤ε(h?)+2γ),那么满足m = Oγ,δ(d)。
假设我们给定的训练集合为S,如果我们基于经验风险最小化原则选择模型,下面是基本的思路:
这里有一个方法称之为k折交叉验证(k-fold cross validation),如下:
在数据集S1 ∪ · · · ∪ Sj?1 ∪ Sj+1∪ · · · Sk(即除去Sj以外)上训练模型Mi,得到一些假设hij
在这样的设置下,你可以使用特征选择算法来减少特征数量。对于给定的n个特征,有2n个可能的特征子集(因为每个特征都包含两个选择,被引入算法和不被引入算法),因此特征选择可以看作是在2n个可能模型中的模型选择。对于特别大的n来说,这通常是计算量非常大的计算,因为要比较2n个模型。因此,有些启发式的搜索策略被用于好的特征子集的发现。下面我们展示一个搜索策略,称之为前向搜索(forward search):
停止该循环过程算法可以通过当F={ 1, . . . , n },即涵盖了所有的特征为止,或者当F达到了某些阈值(比如设置学习算法想要使用的最大特征数)。
上述的算法是wrapper 模型选择(wrapper model feature selection)的一个实例,其中wrapper 指不断地使用不同的特征集来测试学习算法。与前向搜索相对应的,也有其他的一些搜索策略。比如后向搜索(backward search),即开始的时候F={ 1, . . . , n },每次更新需要删除一个特征(测试删除一个特征之后的效果,与前向搜索特征一个特征类似),不断的循环直到F = 。
过滤特征选择(filter feature selection)是给出了一个启发式但是计算量非常低的方法来进行特征子集的选择。该方法的主要思路是通过计算每个特征xi对于分类标签y的信息量得分S(i),然后选择得分S(i)最大的前k个特征即可。
那么接下来的问题就是使用什么样的方法作度量得分S(i)。关于得分S(i)的可能选择,我们可以定义S(i)为xi和y之间的相关性大小的绝对值,这将会使得我们的结果是选择出来与分类标签相关性最强的一些特征。而在实际过程中,更常用的(对于特征xi是离散值的情况)是选择xi和y之间的互信息MI(mutual information)作为S(i)。其中MI计算如下:
该等式是建立在xi和y的值是二元情况,等式很容易推广到xy是多个离散值的情况。其中p(xi, y ), p(xi) 和p(y)能够很容易的从训练集合中的得到。
为了更好的明白互信息是怎么来,我们注意到互信息可以表示为:KL距离(Kullback-Leibler divergence),MI(xi, y ) = KL( p(xi, y ) || p(xi)p(y) ) 。这是衡量了概率分布p(xi, y )和p(xi)p(y)之间有多大程度的不同。如果xi和y是相互独立的变量,那么 p(xi, y ) = p(xi)p(y),而两个分布之间的KL距离是0,这就意味着xi对于y没有很明显的信息量,那么S(i)就会很小;相反,如果xi和y是很相关,即xi对于y具有很大的信息量,那么MI(xi, y )将会很大。
标签:输出 部分 初始 好的 效果 它的 att 开始 wrapper
原文地址:https://www.cnblogs.com/kexinxin/p/9904430.html