标签:dir 允许 nod 通过 命中 read name 方式 包括


格式如图所示:


stat和fstat函数:检索到关于文件的信息(文件的元数据)。使用格式如图所示。

stat函数:以文件名作为输入,并填写stat数据结构中的各个成员。

fstat函数:以文件描述符作为输入。
以readdir系列函数来读取目录的内容。
opendir函数: 以路径名为参数,返回指向目录流的指针。使用格式如图所示

readdir函数:调用返回指向流dirp中下一个目录项的指针,如果没有更多目录项则返回null。closedir函数:关闭并释放其所有资源。
内核用三个相关的数据结构来表示打开的文件
工作过程:
dup2函数:复制描述符表项oldfd到描述符newfd,覆盖描述符表表项new-fd以前的内容。使用过程如图所示。
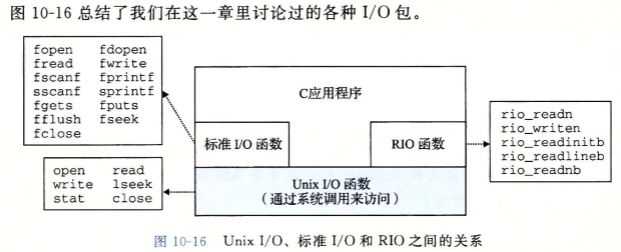
I/O包的总结:如图所示
指导原则:
问题:当学习到教材635页时,看到如图的fork,不太懂fork是什么意思?
解决方案:自己查阅了一下百度,看到了关于fork()函数的资料。它的功能是创建一个子进程。
父进程调用fork()系统调用,然后陷入内核,进行进程复制,如果成功:
1,则对调用进程即父进程来说返回值为刚产生的子进程pid,因为进程PCB没有子进程信息,父进程只能通过这样获得。
2,对子进程(刚产生的新进程),则返回0,
这时就有两个进程在接着向下执行
如果失败,则返回0,调用进程继续向下执行
------详情请见fork函数的介绍
(statistics.sh脚本的运行结果截图)
错题1:有关缓存的说法,正确的是()
A .LRU策略指的是替换策略的缓存会选择最后被访问时间距现在最远的块
B .不同层之间以字节为传送单元来回复制
C .缓存不命时,决定哪个块是牺牲块由替换策略来控制
D .空缓存的不命中叫冲突不命中
答案:AC
解析:我漏选了C,教材P423中介绍了决定哪个块是由缓存的替换策略来控制的。
例如随机替换策略的缓存会随机选择一个牺牲块。
LRU替换策略的缓存会选择最后被访问的那个块。
错题2:有关RAM的说法,正确的是()
A .SRAM和DRAM掉电后均无法保存里面的内容。
B .DRAM将一个bit存在一个双稳态的存储单元中
C .一般来说,SRAM比DRAM快
D .SRAM常用来作高速缓存
E .DRAM将每一个bit存储为对一个电容充电
F .SRAM需要不断刷新
G .DRAM被组织为二维数组而不是线性数组
答案:ACDEG
解析:我漏选了C和D。
SRAM比DRAM要快,成本也高。SARM也用作高速缓存存储器,既可以在芯片上也可以在芯片下。
本周主要学习了Unix I/O模型及它的系统级函数,了解了Linux内核的三个数据结构及其文件的打开方式。第一次接触了描述符的概念,且描述符的表项指向打开文件表中的表项,而打开文件表中的表项又指向v-node表中的表项。还了解标准I/O库,经过书中的了解,标准I/O库的确是优于I/O库的选择。
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 200/200 | 2/2 | 20/20 | |
| 第二周 | 300/500 | 2/4 | 18/38 | |
| 第三周 | 500/1000 | 3/7 | 22/60 | |
| 第四周 | 300/1300 | 2/9 | 30/90 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
2018-2019-1 20165203 《信息安全系统设计基础》第六周学习总结
标签:dir 允许 nod 通过 命中 read name 方式 包括
原文地址:https://www.cnblogs.com/20165203-xyx/p/9904790.html