标签:没有 进程 数据读取 EAP 匹配 .com 值传递 很多 long
目录:
并发基本概念、并发的优势与风险、CPU多级缓存、MESI、乱序执行优化、Java内存模型
并发基本概念:
并发:同时拥有两个或多个线程,如果程序在单核处理器上运行,多个线程将交替地换入或换出内存,这些线程是同时"存在"的。每个线程都将处于执行过程中的某个状态,如果运行在多核处理器上,此时,程序中的每个线程都将分配到一个处理器核上,因此可以同时运行。
高并发:互联网分布式系统架构设计中必须考虑的因素之一,通常指,通过设计保证系统能够同时并行处理很多请求。
并发的优势与风险:
优势:
速度提升:同时处理多个请求,响应更快。复杂的操作可以分成多个进程同时进行
优质设计:程序设计在某些情况下更简单,可以有更多选择
资源利用:CPU能够在等待IO的时候做一些其他的事情
风险:
安全性:多个线程共享数据时可能会产生与期望不符的结果
活跃性:某个操作无法继续进行下去时,就会发生活跃性问题。比如死锁、饥饿等问题
性能:线程过多会使得CPU频繁切换,调度时间增多。同步机制也会消耗过多内存
CPU多级缓存:
(1)主存、高速缓存、CPU核心的关系
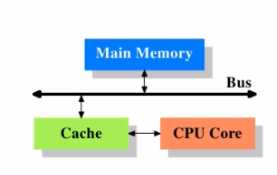
带有告诉缓存的CPU执行计算的流程?
1、程序以及数据被加载到主内存
2、指令和数据被加载到CPU的高速缓存
3、CPU执行指令,把结果写到高速缓存
4、高速缓存中的数据写回主内存
为什么需要CPU cache?
因此CPU的频率太快,快到主存跟不上。在处理器时钟周期内,CPU常常需要等待主存,浪费资源。所以cache的出现,是为了缓解CPU和内存之间速度的不匹配问题。
cache容量远远小于主存,因此出现cache miss在所难免,既然cache不能包含CPU所需要的所有数据,那其存在的意义是什么呢?其意义即是局部性原理。
A、时间局部性:如果某个数据被访问,那么在不久的将来它很可能再次访问。
B、空间局部性:如果某个数据被访问,那么与它相邻的数据很快也可能被访问。
(2)缓存一致性
高速缓存出现不久后,主存和告诉缓存之间的速度差异越来越大,因此一些系统可能采用的二级缓存,甚至三级缓存。
在多核CPU中,内存的数据会在多个核心中存在数据副本,某一个核心发生修改操作,就产生了数据不一致的问题,而一致性协议正是用于保证多个CPU cache之间缓存共享数据的一致。
在MESI出现之前的解决方案是总线机制,这种方案效率很低,锁住总线期间,其他CPU无法访问内存。
CPU多级缓存-缓存一致性MESI
MESI为了保证多个CPU缓存中共享数据的一致性,定义了cache line的四种状态。而CPU对cache line的四种操作可能产生不一致的状态,因此缓存控制器监听到本地操作和远程操作时,需要对地址一致的cache line状态进行一致性修改,从而保证数据在多个缓存之间保持一致性。
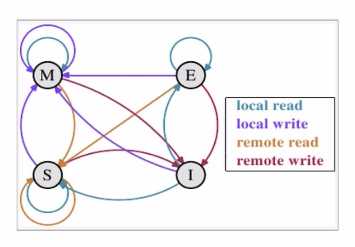
四种状态:
M:被修改(Modified)
该缓存行只被缓存在该CPU的缓存中,并且是被修改过的,与主存中的数据不一致。该缓存行中的内存需要在未来某个时间点(允许其他CPU读取该主存中相应内存之前)写回主存。当写回主存后,该缓存行状态会变成独享(exclusive)状态。
E:独享的(Exclusive)
该缓存行只被缓存在该CPU的缓存中,它是未被修改过的,与主存中数据一致。该状态可以在任何时刻当有其他CPU读取该内存时变成共享状态。同样地,当CPU修改该缓存行中内容时,该状态可以变成Modified状态。
S:共享的(Shared)
该状态意味着该缓存行可能被多个CPU缓存,并且各个缓存中的数据与主存数据一致,当有一个CPU修改该缓存行,其他CPU中该缓存行可以被作废,变成无效状态。
I:无效的(Invalid)
该缓存是无效的(可能有其他CPU修改了该缓存行)
四种操作:
Local read:读本地缓存中的数据
Local write:将数据写到本地的缓存中
Remote read:将内存的数据读取过来
Remote write:将数据写回到主存中
在一个多核的系统中,每一个核都有自己的缓存来共享主存总线,每个CPU会发出读写请求,而缓存的目的是为了减少CPU读写共享主存的次数。
四种操作与四种状态的关系:
一个缓存除了在I状态之外都可以满足CPU的读请求
一个写请求只有在M或E状态下才能执行。如果处在S状态,必须先将该缓存中缓存行变成I状态。通常以广播的方式执行。不允许多个CPU修改同一个缓存行,即使修改该缓存行不同的数据也是不允许的。
一个处于M状态的缓存行,必须监听所有试图读缓存行的操作,这种操作必须在缓存将缓存行写回到主存,并将状态变为S状态之前被延迟执行。
一个处于S状态的缓存行,也必须监听其他缓存使该缓存行无效或者独享该缓存行的请求并将缓存行变成无效。
一个处于E状态的缓存行,要监听其他缓存读缓存中该缓存行的操作,一旦有该缓存行的操作,它就会变成S状态。
对于M和E两种状态而言,数据总是精确的,和缓存行的真正状态是一致的,S状态可能是非一致的,如果一个缓存将处于S状态的缓存行作废,另一个缓存可能已经独享了该缓存行,但是该缓存却不会将缓存行升为E状态,因为其他缓存不会广播它们作废掉该缓存行的通知。由于缓存并没有保存该缓存行的copy数量,因此也没办法确定自己是否独享了该缓存行。
E更像一个投机性的优化,因为一个CPU想修改一个S状态的缓存行,总线事务需要将所有该缓存行copy的值变成I状态,但修改E状态的缓存,却不需要总线事务。
CPU多级缓存-乱序执行优化
处理器为了提高运算速度而做出违背代码原有顺序的优化,单核处理器能够保证处理器做出的优化不影响结果,但多核处理器会造成乱序,使最终结果错误。
并发之Java内存模型
该模型实际上是描述Java中各种变量(线程共享变量)的访问规则,以及在JVM中将变量存储到内存和从内存读取变量这样的底层细节。其规定了不同线程如何及何时可以看到其他线程写入共享变量的值以及如何在必要时同步对共享变量的访问。
(1)Java内存模型介绍
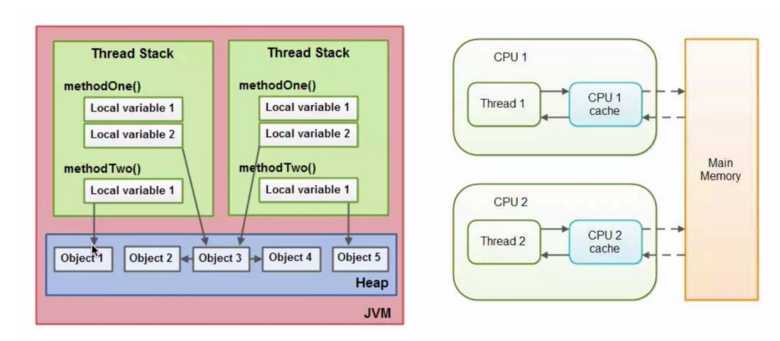
JVM中内存分配的两个概念:
A、stack(栈)
特点:存取速度快,对象生命周期确定,数据大小确定
存储数据:基本类型变量,对象引用
位置:缓存、寄存器、写缓存区
B、heap(堆)
特点:存取速度慢、运行时动态分配大小,对象生命周期不确定,垃圾回收作用域
存储数据:对象
位置:主内存、缓存
理论上说所有的stack和heap都存储在物理主内存中,但随着CPU运算其数据的副本可能被缓存或寄存器持有,持有的数据遵从一致性协议。存储在堆上的对象可以被持有该对象引用的栈访问,能访问对象也就能访问该对象中的成员变量。当两个线程同时访问一个对象时,每个线程都拥有该对象成员对象变量的私有拷贝。
(2)Java内存模型抽象
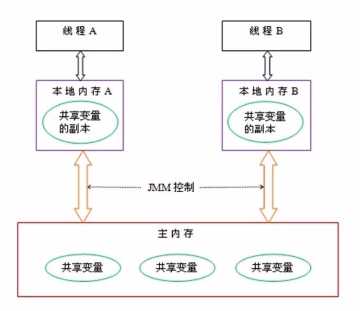
线程对共享内存的所有操作都必须在自己的工作内存中进行,不能直接从主内存中读写。
不同线程无法直接访问其他线程工作内存中的变量,因此共享变量的值传递需要通过主内存完成。
并发问题的根源:
当A、B两个线程同时访问某个对象的成员变量X,当A操作变量a时会将a副本拷贝到线程A的工作内存中,当线程a未执行完毕时,线程B也要访问变量a。对于两个线程而言,操作的都是自己工作空间中的变量副本。两个线程副本互不可见。如果A线程先完成了任务并将改变后的a写回主存,那么线程B的运算结束后写回主内存的a就会覆盖原来线程A的结果。造成线程A的任务丢失。为了保证程序的准确性,我们就需要在并发时添加额外的同步操作。
Java内存模型-内存间的八种同步操作
Java内存模型定义了8中操作来完成,主内存与工作内存之间的交互协议。它们都是原子操作(除了对long和double类型的变量)
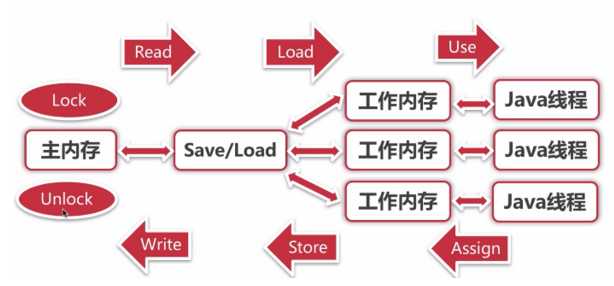
lock(锁定):作用于主内存中的变量,将它标记为一个线程独享变量
unlock(解锁):作用于主内存中的变量,解除变量的锁定状态,被解除锁定状态的变量才能被其他线程锁定
read(读取):作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用
load(载入):把read操作从主内存中得到的变量值放入工作内存的变量的副本中
user(使用):把工作内存中的一个变量的值传给执行引擎,每当虚拟机遇到一个使用到变量的指令时都会使用该指令
assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作
store(存储):作用于工作内存的变量,它把工作内存中一个变量的值传送到主内存中,以便随后的write操作使用
write(写入):作用于主内存的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中
操作规则:
1、不允许read和load、store和write操作之一单独出现
2、不允许一个线程丢弃它最近assign的操作,即变量在工作内存中改变了之后必须同步到主内存
3、不允许一个线程无原因地(没发生过任何assign操作)把数据从工作内存同步回主内存
4、一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量。执行user和store操作之前,必须先执行过assign和load操作
5、一个变量在同一时刻只允许一个线程对其进行lock,但lock操作可以被同一线程重复执行多次。必须执行相同次数的unlock才能解锁。两者必须成对出现
6、如果对一个变量执行lock,将会清空工作内存中此变量的值,在执行引擎使用这个变量前需要重新执行load或assign来初始化
7、如果一个变量事先没有被lock操作锁定,则不允许它执行unlock,也不允许去unlock一个被其他线程锁定的变量
8、对一个变量执行unlock之前,必须先把此变量同步到主内存中(执行store和write)
9、如果要把一个变量从主内存中复制到工作内存中,就需要按顺序执行read和load操作。从工作内存同步到主内存,就要按顺序执行store和write操作。Java内存模型要求上述操作按顺序执行,没有保证必须是连续执行
标签:没有 进程 数据读取 EAP 匹配 .com 值传递 很多 long
原文地址:https://www.cnblogs.com/zhangbLearn/p/9904332.html